

Desktopový Zen, Summit Ridge pro socket AM4 (vizualizace)
Podstatně širší než buldozer
AMD odhalilo poměrně dost informací
o parametrech a uspořádání jader, včetně oficiálního
diagramu, který můžete vidět níže. Tyto údaje se jinak poměrně
kryjí s údaji, které
se postupně objevovaly díky patchům pro GCC či Linuxové
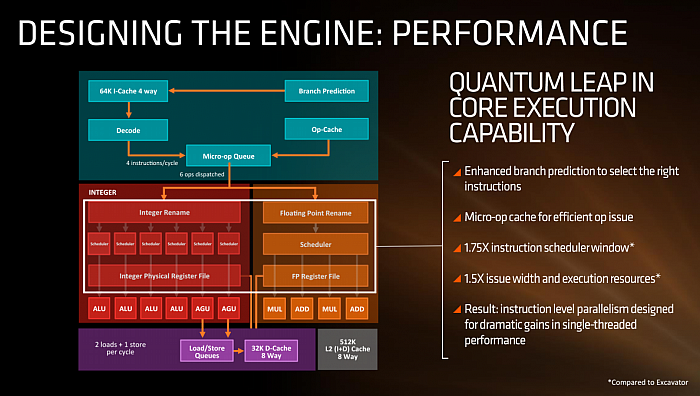
jádro. Můžeme tedy potvrdit, že jádro má celkem šest pipeline
v celočíselné části, kde jsou čtyři ALU (dvojnásobek
proti jádru Bulldozer) a dvě AGU neboli load/store jednotky –
ty umí zpracovávat dvě 128bitová čtení nebo jeden 128bitový
zápis za takt (celkem ale vždy jen dvě operace).
Jádro Zen je staveno na značně vyšší IPC než architektury rodiny Bulldozer
FPU, která u AMD
počítá i celočíselné instrukce SIMD, je opět oddělená
s vlastními schedulery a out-of-order bufferem a má
čtyři pipeline, tedy tolik, co má Bulldozer či Piledriver pro dvě
jádra. Podle schématu by pipeline měly mít různé úlohy a zdaleka ne všechny instrukce budou moci být vykonány každou z nich. Zdá se, že šířka jednotek je nativně 128bitová, nejoptimálnější jsou tedy pro Zen instrukce SSE-SSE4, který bude jádro umět při vhodném mixu vykonat až čtyři za takt. Pro operace AVX (256bitové) bude
propustnost poloviční.
Po stránce výpočetních jednotek je
tedy jádro Zen stavěno na podstatně vyšší výkon na 1 MHz
než Bulldozery – a tím i vyšší výkon v jednom
vlákně. Tomu má přispět i značně hlubší out-of-order
buffery, „okno“ instrukčního scheduleru má údajně být proti
Excavatoru větší o 75 %; vylepšeno bude jako obvykle
také předvídání větvení.
Frontend jádra má k dispozici
čtyři instrukční dekodéry, jeho kapacita je však navýšena
údajně poměrně velkou mezipamětí cachující dekódované
instrukce („Micro Op Cache“), což je zlepšovák, který Intelu
dobře slouží od Sandy Bridge. Z fronty dekódovaných
instrukcí lze za takt do jádra odeslat 6 operací. „Issue
width“ by tedy měla být dle využití Micro Op Cache 4–6.
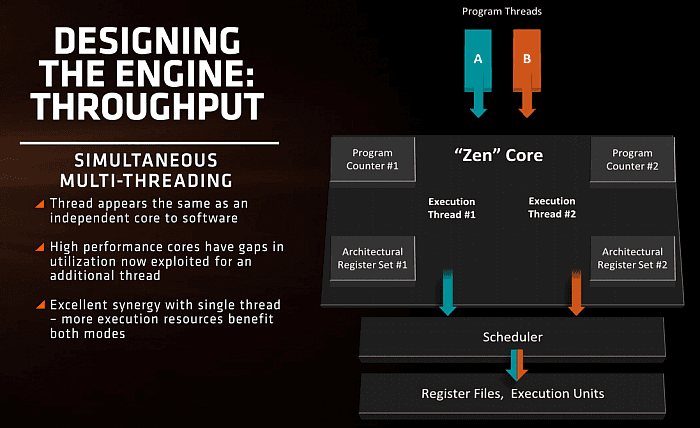
SMT
Již dříve bylo známo, že jádro
Zen bude podporovat dvoucestné SMT, tedy zpracovávání dvou
softwarových vláken naráz v jednom jádru, které tak pro
programy vypadá jako jádra dvě. Podle AMD je tato technika výhodná
zejména proto, že benefituje z věcí, které AMD beztak udělá
kvůli zvyšování výkonu v jednom vlákně – tedy
zejména zvýšení počtu výpočetních jednotek. Více prostředků
zvyšuje množství zdrojů, které zůstávají při výpočtech
jednoho vlákna nevyužité – při běhu dvou vláken lze část
takového ztraceného potenciálu využít, jelikož „bubliny“
v jednom vlákně umí využít druhé. AMD zde také dosáhne
paritu s Intelem, kterému SMT (pod označením HT) pomáhá ve
vícevláknovém výkonu již od doby Nehalemu.
SMT je v podstatě obdoba technologie HT u Intelu, používá ji ale i řada dalších architektur CPU
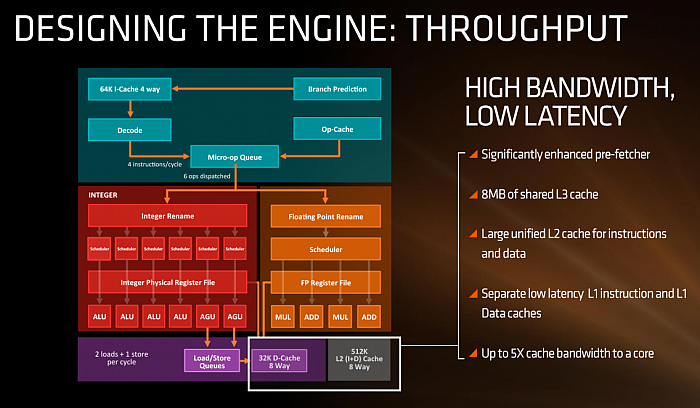
Cache: mnoho prostoru pro zlepšení
Jedním z kritizovaných aspektů
Bulldozeru byl subsystém cache a pamětí. AMD u Zenu
zdůrazňuje, že právě tato část by měla doznat velkých
zlepšení. L1 cache bude spolu s L2 cache privátní pro každé
jádro. L1 je rozdělená pro instrukce a data – ta
instrukční má 64 KB se čtyřcestnou asociativitou, datová pak 32
KB s osmicestnou asociativitou. Obě mají mít údajně nízkou
latenci, co to však konkrétně znamená, nevíme. Datová L1 cache
je jinak typu write-back, nikoliv write-through (tedy bez možnosti
opožděného „líného“ zápisu do další úrovně paměťového
subsystému), což bylo problematické u Bulldozeru a jeho
derivátů.
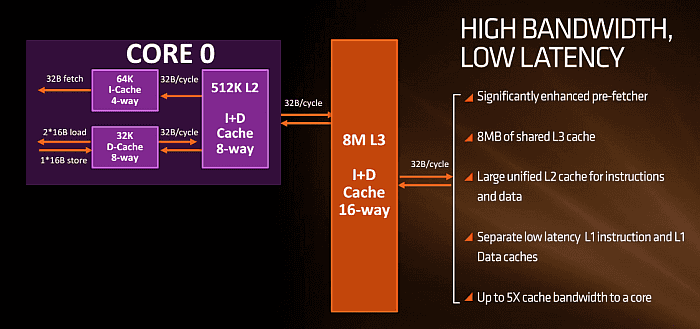
L2 cache má kapacitu 512 KB opět
s osmicestnou asociativitou. L3 cache, která má
šestnácticestnou asociativitu a kapacitu 8 MB. Je sdílena
mezi jádry a to buď mezi všemi osmi, nebo podle některých
neoficiálních zdrojů vždy mezi čyřmi. V takovém případě
by pak osmijádro Summit Ridge mělo dvě tyto L3 cache (celkem 16
MB), to ale není potvrzeno a zatím bych počítal spíše s první
variantou. Mezi L3 a L2 cache umí procesor posílat 32 bytů za
takt oběma směry, totéž pak mezi L2 a L1. Z L1 cache
pak lze do jádra „fetchovat“ 32 bytů v případě
instrukční cache; do datové L1 je možno zapsat z jednotek
AGU jak již bylo řečeno 1×16 bytů nebo z ní přečíst
2×16 bytů.
AMD v prezentaci uvádí, že
přenosová rychlost z pamětí cache dostupná jednomu jádru
byla v Zenu zvýšena až pětinásobně. Údajně by vedle
lepší propustnosti systém cache měl mít také nízké latence,
což by v případě úspěšného naplnění těchto slibů
bylo zlepšení ve všech ohledech. Kromě toho má Zen proti
předchozím architekturám mít také vylepšený prefetching, což
by opět mělo pomoci v přísunu dat do jader.
Nový subsystém pamětí cache má mít výrazně vyšší propustnost a údajně nízké latence
Opět zaměřeno na spotřebu
V prezentaci je také věnována
stránka důrazu na efektivitu architektury Zen co do poměru výkonu
a spotřeby – ta bude totiž extrémně důležitá pro
servery a později pro notebooky. Tomuto cíli slouží řada
architektonických voleb (write-back L1 cache, Micro Op Cache,
eliminace operací MOV přesouvajících data mezi registry jejich
přejmenováváním). Jádro má ale také používat agresivní
„clock gating“, tedy odstřihávání nepoužívaných bloků od
hodinového signálu, což bude zřejmě možné učinit pro různé
části jádra nezávisle.
Spotřebě zároveň bude pomáhat výroba
na novém procesu s tranzistory typu FinFET – na 14nm
technologii GlobalFoundries. Podle webu AnandTech prý AMD potvrdilo,
že je použita verze tohoto procesu optimalizovaná na hustotu,
v samotných prezentačních slajdech ale toto zmíněno není.
Architektura Zenu poprvé odhalena
První Zeny až po Silvestru –
Summit Ridge do socketu AM4, Naples pro servery
V tiskové zprávě se na jednom
místě hovoří o tom, že Zen začne svou pouť v nabídce
procesorů pro stolní PC „začátkem příštího roku“. To je
zřejmě definitivní odpověď (byť ještě ne přesná na den
a hodinu) na otázku, zde se procesory stihnou ukázat do konce
letoška, kterou ještě
v červenci firma nechávala zčásti otevřenou. Možnost
byť třeba omezeného vypuštění ještě v prosinci, asi
nakonec byla vzdána.
Půjde o procesory Summit Ridge
pro nový
socket AM4, v plné palbě osmijádra s šestnácti
vlákny a TDP 95 W. Nová platforma přinese podporu
dvoukanálových pamětí DDR4, PCI Express 3.0 a také třeba
úložiště SSD typu NVMe. Lze asi čekat, že se v prodeji
objeví i nějaké částečně deaktivované modely Summit
Ridge za levnější cenu (která bude u osmijader asi mnohem
vyšší, než u současných FX-83xx). V databázi Zauba
se například nacházejí záznamy o čtyřjádrech s TDP
65 W. Pokud jde o APU založená na Zenu, ta mají přijít až příští rok, a dle CTO firmy Marka Papermastera zřejmě až v jeho druhé polovině.
První test: IPC na 3,0 GHz
AMD při prezentaci ukázalo také
první oficiální „benchmark“ osmijádra Summit Ridge. Lépe
řečeno test IPC, tedy výkonu při konstantním taktu. Ukázáno
bylo srovnání Summit Ridge v platformě AM4 (nikoliv finálního
kusu, šlo o inženýrský vzorek) a osmijádrového
Broadwellu-E, Core i7-6900K. Pro srovnání výkonu „na jeden
MHz“ byly obě CPU nastavena na 3,0 GHz, což je pro Broadwell-E
pochopitelně podtaktování. Spuštěn byl rendering v Blenderu,
který by měl využít všechna jádra i HT/SMT, tedy celkem 16
vláken u obou čipů.
Tento výpočet AMD dokončilo o pár
snímků videa dříve, což znamená, že zde konkrétně dosáhlo
dokonce o maličko vyšší výkon na takt (IPC), než
Broadwell-E, byť má výrazně menší L3 cache (alespoň pokud se nepotvrdí dohad o 2×8 MB). Jde samozřejmě jen o jeden
test, nicméně ponaučení je takové, že minimálně v některých
úlohách by Zen mohl dosahovat i IPC mírně přesahující
architekturu Broadwell, byť AMD mluví oficiálně stále jen o 40%
orientačním zlepšení nad rámec Excavatoru.
V jiných
úlohách či testech to pochopitelně může vypadat odlišně,
logicky se asi dá očekávat, že AMD pro tuto demonstraci zvolilo
test, v kterém Zen vypadá nadprůměrně dobře. V reálné
situace samozřejmě také bude záležet na taktech, které se zatím
u Zenu očekávají nižší, než u Intelu (oficiálně
ale pro ně žádná data nemáme).

Demonstrace Blenderu na vzorku Summit Ridge proti Core i7-6900K, oba čipy na 3,0 GHz
Serverová 32jádra
Kromě desktopové platformy AM4 má
AMD přichystánu také serverovou verzi Naples. Ta nabídne Zeny až
s 32 jádry, což budou zřejmě procesory složené ze čtyř
čipů Summit Ridge, takže by snad měly mít osmikanálové paměti
DDR4 – což ale zatím také nebylo oficiálně potvrzeno.
Tato CPU se mají osazovat do socketu označeného SP3, který dle
některých zdrojů má mít 4094 pinů či kontaktů (půjde zřejmě
o pouzdro typu LGA), víc než šestikanálový socket Intelu
(LGA3647).






Na webu jsou již k vidění
fotografie dvouprocesorové desky pro Naples ukázané na akci, s CPU
a chladiči osazenými, takže samotný socket vidět není.
Měla by mít dva procesory Naples a dost možná ukazuje, že
jsou schopné pracovat bez nějakého externího čipsetu jako SoC
(pokud tedy čipsetem není malý čip sousedící s obvodem
Aspeed zajišťujícím vzdálenou správu a grafický výstup).
Deska má jen osm paměťových slotů pro každý socket, což by
ale mohlo být proto, že na ní pro víc ani není prostor.
Zen+
Mimochodem, AMD také v prezentacích
jasně avizuje, že architektura Zen nebude nějakým koncem evoluce,
ale naopak jen prvním stupněm – což je poměrně logické,
jelikož jde o design započatý na zelené louce a měl by
tedy umožňovat další rozvoj. Podle prezentace by následník,
zatím provizorně označený „Zen+“ (což ale není kódové jméno, jen označení pro to, co přijde po Zenu), měl dosáhnout vyššího výkonu,
a to zřejmě nejen vyššími taky, ale také dalšími
architektonickými zlepšeními, které opět zvednou výkon na
1 MHz, tedy ono tolik ceněné „IPC“.

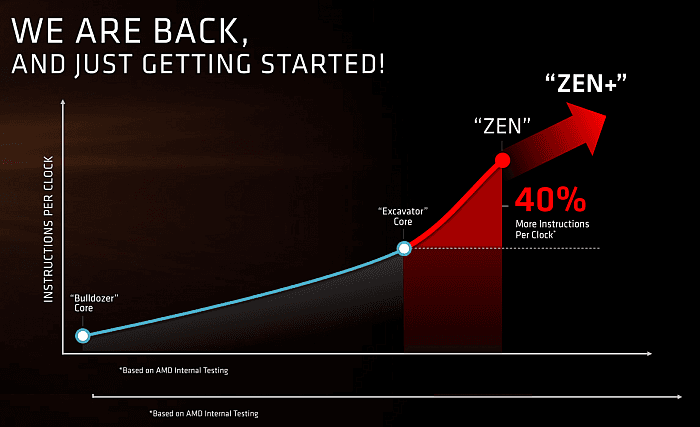
Zen+, neboli architektura následující po Zenu, by měla IPC opět zvýšit
Zdroje: AMD (1,
2),
AnandTech,
ComputerBase










































