
ARM přišel s 64bitovou
instrukční sadou ARMv8 poměrně pozdě (uvedena byla v roce
2012), její návrh je ale docela pozitivně hodnocen. Proti
aktuálním procesorům x86 mají nicméně procesory ARM jeden
deficit: ve schopnostech instrukcí SIMD, které pracují jen
s 64 či 128bitovými vektory, kdežto x86 již poskytuje
256bitové AVX a AVX2 a výhledově se dostáváme
k AVX-512 s dvojnásobným vektorem. V připravované
aktualizaci architektury označneé ARMv8-A nicméně ARM hodlá
srovnat krok (respektive spíše „dohnat a předehnat“)
a pokročilé instrukce SIMD doplnit rozšířením nazvaným
SVE.
SVE znamená „Scalable Vector
Extensions“ a ona škálovatelnost v názvu není jen tak
pro nic. SVE má pokrývat operace typu SIMD se šířkou vektoru až
2048 bitů, což by například pro běžné 32bitové hodnoty (FP32)
znamenalo 64 čísel zpracovávaných jednou instrukcí, pro menší
datové typy dvojnásobek nebo čtyřnásobek. SVE tím pádem bude
vstupenkou procesorů ARM do světa superpočítačů neboli sektoru
HPC, kde se uplatní skutečně masivní šířka vektorových
registrů.
Nicméně ARM zdá se chce, aby toto
rozšíření instrukční sady bylo univerzálnější, neboť
masivní zrychlení při použití instrukcí SIMD se hodí v celé
řadě oblastí, významně zejména v multimédiích. V běžných
procesorech pro spotřebitelskou sféru by ale takto široké vektory
neměly valné využití, pro řadu operací je optimální šířka
128bitů a již 256bitové instrukce nejsou využitelné vždy
(například je pro ně uzpůsoben formát HEVC, ale H.264 s menšími
bloky již méně). Z tohoto důvodu je rozšíření SVE
navrženo do jisté míry agnosticky k šířce vektoru,
a zkompilovaný kód má fungovat na celé škále vektorových
jednotek FPU s různou šířkou. Spodní hranicí má být
128bitová šířka, kterou bychom mohli nejspíše nalézt
v budoucích mobilních čipech, a horní již zmíněných
2048 bitů.

ARM uvádí, že chce problém
vektorizace na různé šířky instrukcí SIMD přesunout z rukou
překladače a programátora (v případě, kdy je kód
optimalizován ručně) do hardwaru. Instrukce SVE tak mají být
kompatibilní pro všechny šířky, a samotný procesor se má
starat, aby kód zpracoval ideálním způsobem pro svou jednotku
FPU.
To zřejmě znamená, že pokud je
jednotka úzká, budou se instrukce dělit a zpracovávat ve
více taktech, nebo naopak pokud je jednotka široká (oněch 2048
bitů), bude do ní posláno více operací najednou (pokud to
ovšem závislosti a skladba programu dovolí). Jak přesně je tato
kompatibilita realizována, ale ze zveřejněných popisů nevyplývá.
Patrně by to ale mohlo obnášet, že vektorové operace budou
pracovat v oddělitelných sekcích o určité základní
šířce, které se pak budou opakovat, například po oněch 128
bitech. To například pro sčítání nebo násobení nebude
problém, ale brání to efektivnímu použití permutací či
horizontálních operací, což nejsou právě neužitečné
instrukce. Podobně rozdělené zpracování nicméně používá
i AVX a AVX2, takže ARM s tímto problémem nebude
sám.

SIMD instrukce ARMv8-A SVE
První uživatel: superpočítače Fujitsu
Zdá se, že se prozatím nepočítá
s implementací SVE v rámci hotových licencovatelných
jader ARM Cortex. SVE tak bude dostupné zpočátku jen firmám,
které licencují čistě instrukční sadu a na jejím základě
vytvářejí vlastní architekturu jádra (například Qualcomm).
Prvním oznámeným uživatelem je japonské Fujitsu, což vám možná
rozsvítí žárovku. Nedávno bylo oznámeno, že tato firma hodlá
architekturu ARMv8 použít v nových HPC procesorech místo
dosavadních jader Sparc a její volba tak s instrukcemi
SVE začíná dávat smysl. Procesory, které firma chystá pro svou
novou generaci superpočítačů, budou tedy numerický výkon
realizovat právě pomocí nich. Objevit se mají v superpočítači
pro instituci RIKEN v roce 2020.
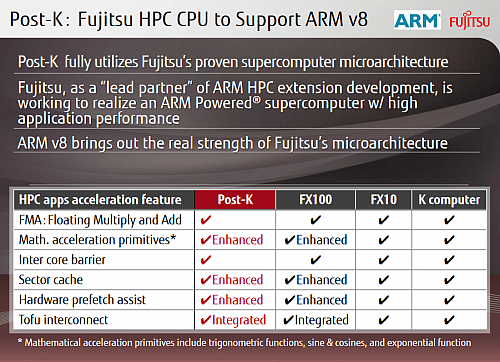
Fujitsu přejde ve svých HPC procesorech z archtiektury Sparc na 64bitový ARM

Jak to bude s dalším využitím
a zda se SVE objeví i v procesorech ARM pro „sprostý
lid“, zatím není jasné. Podpora nízkých šířek vektoru by
asi měla naznačovat, že se tyto instrukce dostanou i do
běžných ARMů. Zda to ale bude nějak brzy, to těžko říct.
Dostupné informace nezmiňují, jaké datové typy kromě čísel
s plovoucí desetinou čárkou (patrně v dvojité
a jednoduché přesnosti) budou dostupné, takže těžko říct,
jak užitečné by toto rozšíření bylo například pro
multimédia. Pokud ARM myslí i na celočíselné hodnoty, pak
by však sada byla dostatečně univerzální.
Zdroje: The
Register, AnandTech










































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU