
Schéma, které web zveřejnil, totiž popisuje čip se čtyřmi nebo šesti jádry, přesněji řečeno dvěma až třemi moduly architektury Steamroller (čili parní válec). Vzhledem k tomu, že jednomodulové APU Trinity působí dnes přece jen značně slabě, dávalo by jejich opuštění smysl (navíc se ještě mohou nějakou dobu v klidu doprodávat, budou-li s Kaveri kompatibilní). Nahrazení dvou a čtyřjádrových modelů čipy o čtyřech a šesti jádrech by značně podpořilo výkon CPU těchto procesorů, byť by se to týkalo jen vícevláknových úloh.
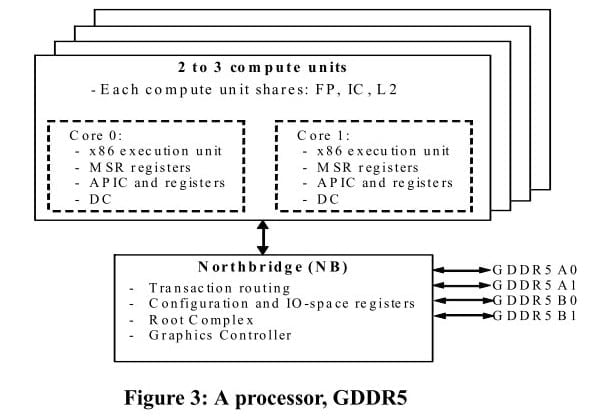
Nové informace z BSN* také již hovoří o tom, že by se na čipu měl vedle řadiče pro GDDR5 nacházet i řadič pro paměti DDR3/DDR3L. Je-li tomu tak, bude APU nakonec asi konvenčně řešený čip, a GDDR5 bude zřejmě integrováno v jeho pouzdře.
Něco nového se dozvídáme i k samotné architektuře Steamroller. Tu jsme probírali zde, takže nyní jen novinky. Dle BSN naroste intrukční L1 cache o 50 % na 96 KB, a její asociativita bude třícestná (což je divné, obvykle v tomto kontextu vidíte mocniny dvou, u Piledriveru je dvoucestná). Procesor má také rozšířit virtulizační shopnosti na řadič přerušení. Potvrzuje se, že obě jádra budou mít v Steamrolleru vlastní dekodéry (každý zvládne čtyři instrukce za takt). Sdílená zůstává FPU, L2 cache a instrukční L1 cache (kde lze sdílení využít k úspoře prostoru, pokud obě vlákna používají stejná data).
Již loni AMD hlásilo, že nová architektura bude mít o 30 % vyšší IPC, vedle uvedeného (a již známých změn), se na tomto zrychlení podepíší i různé zvětšené buffery. Branch target buffer L2 cache byl zvojnásoben (z 5120 záznamů tedy zřejmě na víc než 10 000). Prefetching filtering buffer (PFB) byl také zdvojnásoben na 16 záznamů. Procesor může mít najednou ve frontě 48 čtení a 32 ukládání dat z/do paměti (pro Piledriver to bylo 44, respektive 24). Co se vylepšení techniky Store to load forwarding týče, procesor si bude pamatovat osm, posledních uložení místo tří u Piledriveru.
/architektura_amd_steamroller_hot_chips_2012.jpg)
/architektura_amd_steamroller_hot_chips_2012.jpg)
/architektura_amd_steamroller_hot_chips_2012_0.jpg)
/architektura_amd_steamroller_hot_chips_2012_1.jpg)
/architektura_amd_steamroller_hot_chips_2012_2.jpg)
BSN* uvádí, že FPU by měla mít o 25 % kratší pipeline a tedy mnohem lepší latence instrukcí. Ale pozor – to je ve skutečnosti jen chybný výklad informace, že FPU Steamrolleru bude přeorganizována do tří jednotek či portů (též označovaných jako pipeline), zatímco Piledriver měl čtyři. Výkon by to však nemělo negativně ovlivnit, neboť výpočetní zdroje zůstanou zachovány, jen budou rozděleny mezi menší počet portů.
Z jisté části dokumentace mimochodem BSN* usuzuje, že Kaveri by mohlo dostat podporu pro běh v roli zařízení připojeného na sběrnici PCI Express, podobně jako například čipy GPU. Smyslem takového kroku (pokud se toto potvrdí) ovšem asi nebude osazování APU na rozšiřující karty. Na protokolu PCI Express je založena propojovací logika Freedom Fabric, kterou AMD používá v mikroserverech SeaMicro. Moduly těchto serverů nyní vedle CPU a paměti potřebují také osazený čipset a speciální čip, který slouží k napojení na Freedom Fabric.


Pokud by ale Kaveri zvládalo přímé spojení s Freedom Fabric, ušetřilo by se na desce místo a lehce by se snížila i spotřeba. Pokud by navíc APU dokázalo startovat i bez přítomnosti čipové sady (což dokáže například Atom Centerton), zbylo by možná na serverové kartě místo ještě na jeden socket, čímž by se hustota proceosorů (a tím i instancí serverů) proti stávajícím Xeonům a Opteronům zdvojnásobila.
Zdroj: Bright Side Of News*











































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU