

AMD uvádí první desktopová APU Kaveri
Dnešním dnem startují na trhu první dva modely ze sestavy čipů Kaveri, a to odemčená čtyřjádra A10-7850K a A10-7700K. O něco později by k nim měl přibýt ještě procesor A8-7600, jehož TDP je nižší – 65 či 45 W. Ten ale zatím na světě není. Jak hned uvidíte, AMD už ve svých materiálech přestalo používat zvláštní označení pro grafická jádra, která označuje toliko jako (u těchto tří modelů) Radeon R7. Konkrétní konfiguraci tedy bude určovat samo modelové číslo APU.
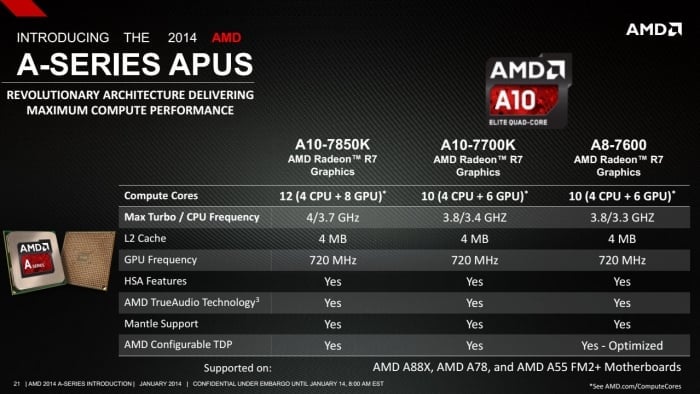
Modely APU Kaveri. A10-7850K a A10-7700K jdou na trh dnes
| Model | Jádra |
L2 Cache | Takt CPU |
CPU - turbo |
GPU - takt |
GPU - turbo | Shadery | TDP |
Cena |
| A10-7850K | 4 | 4 MB | 3,7 GHz | 4,0 GHz | 654 MHz? | 720 MHz | 512 | 95 W | 173 USD |
| A10-7700K | 4 | 4 MB | 3,4 GHz | 3,8 GHz | 654 MHz? | 720 MHz | 384 | 95 W | 152 USD |
| A8-7600 | 4 | 4 MB | 3,3 GHz | 3,8 GHz | 654 MHz? | 720 MHz | 384 | 65 W | 119 USD |
V tabulce parametrů uvádím oficiální ceny v USD. Nicméně oba dnes uváděné modely již mají v cenících české eshopy, a to za ceny přibližně 3850 CZK pro A10-7700K a téměř 4400 CZK pro A10-7850K. Ceny tedy začínají poměrně vysoko. Jen částečně je omlouvá to, že k modelům A10 má AMD přikládat kupon na stažení hry Battlefield 4 (což je nový a atraktivní titul). Zatím ale nevíme, jak moc omezený bude počet kuponů a tedy i dostupnost tohoto bundlu.
Jak můžete vidět v tabulce, finálními takty se Kaveri zastavilo o notný kousek níž, než jeho předchůdce Richland. Situace je mírně podobná tomu, co jsme viděli u APU Llano, což byl první 32nm čip AMD. Kaveri je prvním velkým procesorem, který firma vyrábí na 28nm procesu v továrnách GlobalFoundries. Ten jednak ještě není natolik vyladěný jako 32nm linky, vedle toho ale obecně neumožňuje jít s takty CPU tak vysoko, což AMD samo přiznává.

Kaveri je prvním velkým procesorem, který AMD vyrábí na 28nm procesu GlobalFoundries bez použití technologie SOI
28nm proces GlobalFoundries je založen na běžných waferech typu bulk, zatímco doposud AMD u čipů na bázi K10, Bulldozeru a Piledriveru vždy používalo procesy typu SOI (Silicon on Insulator). 28Nm proces SOI by zřejmě podal o něco lepší výsledky, výrobní náklady jsou však vyšší a AMD coby prakticky jediný uživatel SOI u GlobalFoundries si už do této technologie nedovolilo investovat další finance. Proces typu bulk tedy není pro výrobu CPU ideální, naopak ale údajně lépe sedí výrobě GPU a podobných obvodů. Použití konkrétní 28nm litografie tedy Kaveri umožnilo zvednout hustotu tranzistorů ve veledůležité integrované grafice, ovšem za cenu nižších dosažitelných taktů o procesorů pro desktop.
Souvisí to i s tím, že i u tohoto APU byly při návrhu prioritou notebooky. Čip má být údajně odladěn pro zátěžovou spotřebu (TDP) okolo 35 W, při níž ještě frekvenční omezení 28nm procesu nehrají velkou roli. Snížením napětí a taktů pak AMD může Kaveri adaptovat na nižší spotřeby kategorie ULV (15 W), jejich zvýšením pak zase pro roli desktopového 65–95W procesoru, což je případ dvou dnes uváděných modelů. Důsledkem nicméně je, že v této kategorii CPU část Kaveri na desktopu nezaznamená příliš velký výkon, byť nižší takty kompenzuje přepracovanou architekturou se zvýšeným IPC.
TDP si můžete vybrat v BIOSu
Velmi zajímavou novinkou u APU Kaveri je podpora pro nastavení TDP čipu. U Kaveri by tato možnost měla být přímo přístupná uživateli, a to prostřednictvím BIOSu desky. Částečně se tak stírá dřívější rozlišení mezi 100W (u Kaveri 95W) odemčenými modely, a čipy se sníženým TDP, nižšími takty zamčeným násobičem. Tentýž procesor by mělo být možné provozovat jak při plném TDP 95 W, tak s omezením na 65 W. Jak dobře bude vše fungovat, bude ale ještě třeba zjistit. AMD podotýká, že u plnotučných 95W APU není nastavování TDP plně optimalizováno. Naopak by mělo být vyladěno u úspornějšího 65W modelu A8-7600, u kterého se explicitně počítá s přepnutím na 45W TDP.

Čip Kaveri
Kaveri obsahuje, zřejmě zejména zásluhou efektivnějšího využití plochy v GPU, značně vyšší počet tranzistorů než Trinity/Richland. Na čipu se jich údajně má nacházet 2,41 mililardy; vměstnat se je podařilo do 245 mm². To je mimochodem prakticky stejná plocha, jako má Trinity, toto APU ale na 32nm procesu typu SOI dokázalo do prakticky stejné plochy natěsnat jen asi 1,3 miliardy tranzistorů.

Detailní snímek čipu
Kaveri přichází, po desetiletí poprvé bez SOI
Operační paměť, poprvé ve znamení HSA
Aby zdůraznilo vzájemnou integraci GPU a CPU, začalo AMD v propagačních materiálech obě části APU označovat za „výpočetní jádra“ (compute cores), postavené sobě na roveň. Kaveri tak vcelku obsahuje až 12 takto definovaných jednotek (4 jádra CPU, až 8 GPU bloků architektury GCN po 64 stream procesorech). AMD se nicméně dušuje, že si tímto způsobem nechce hrát na nějaké dvanáctijádro. Trvající rozdíly mezi vlastnostmi a schopnostmi CPU a GPU se slovy každopádně smazat nedají.

Kaveri - první APU s architekturou HSA
Kaveri je prvním APU, u kterého lze říci, že AMD dotáhlo původní koncepci „Fusion“. Mezitím již aleAMD toto marketingové označení opustilo a preferuje termín HSA, což je zkratka pro Heterogenous System Architecture. Doposud byla grafická jádra čipů vždy spíše integrovanými grafikami a na čipu žila tak trochu ve vlastním světě. S HSA má ale toto skončit a z výpočetních jednotek GPU se mají stát plnoprávní účastníci unifikovaného výpočetního provozu. Tedy alespoň dle AMD.
V čipu je samozřejmě GPU nadále vyděleným výpočetním blokem podobně jako dříve. Ona unifikace s CPU ve skutečnosti spočívá v detailech architektury a programovacího modelu, které usnadňují současné používání obou výpočetních zdrojů.

Kaveri - první APU s architekturou HSA
Nejzásadnější změna spočívá v tom, jak Kaveri nakládá s operační pamětí. Všechna APU a vůbec integrované grafiky pro svůj paměťový prostor používají systémovou paměť, jejich vlastní segment však vždy byl více či méně oddělen. Je tomu tak proto, že RAM musí být udržována v koherentním (synchronizovaném) stavu s obsahem pamětí cache v CPU, a pokud si v ní GPU operuje, není toto v konvenční architektuře možné. GPU kvůli tomu mělo svou paměť vyhrazenu a jeho prostor CPU necachovalo, aby nepracovalo s neplatnými daty.

Kaveri - první APU s architekturou HSA
Ze softwarového hlediska jsou pochopitelně možné transfery dat mezi oběma segmenty, i přímý přístup GPU či CPU do prostoru druhé „polovičky“. Podléhají ale výkonnostním omezením spojeným s podstatou hardwaru, koherentního a nekoherentního přístupu. V Kaveri toto padá. Jeho GPU již má plný přístup k celému adresnímu prostoru počítače (respektive až do 32 GB), stejně jako může CPU přistupovat do celé paměti. Zajištěna by přitom již měla být koherence dat s obsahem pamětí cache (podobně, jako to řeší víceprocesorové architektury CPU). Paměťový model APU s podporou HSA firma AMD označuje jménem hUMA.
Tato unifikace je výhrou pro programátory, kteří se zbaví části komplexity spojené s programováním kódu GPGPU přes framework OpenCL. Plnohodnotně sdílená paměť eliminuje pomalé přenosy dat mezi paměťovými prostory. Zároveň umožňuje, aby se GPU částečně vymanilo z podřízené role koprocesoru. Tradičně musí být kód GPGPU grafickému procesoru přiřazen a inicializován hostitelským procesorem, který tak musí řídit všechnu práci vykonávanou na GPU. Toto fungování pochopitelně plýtvá výkonem a často brání tomu, aby akcelerace úlohy na GPU vůbec zrychlila její výpočet.
V architektuře HSA je již GPU možno programovat volněji díky heterogenním frontám (hQ). Pod HSA již může GPU samo inicializovat a spouštět své úlohy, čímž se snižuje zátěž CPU ale i latence. Zároveň ale může přidělit práci také CPU. To umožňuje, aby konkrétní kód byl vždycky vykonáván těmi výpočetními jednotkami, které se pro něj více hodí. Díky sdílené paměti by přesouvání práce mezi CPU a PGU mělo být poměrně flexibilní a programátoři už nebudou přicházet o výkon proto, že se některá část algoritmu na GPU počítá neefektivně. Tato a další zlepšení architektury HSA by měla být využita v programovacím frameworku OpenCL 2.0.
Paměťový řadič nakonec zvládne i DDR3 na 2400 MHz
Ačkoliv předběžné informace hovořily o paměťovém řadiči toliko s oficiální podporou toliko pamětí DDR3 na efektivním taktu 2133 MHz. Nakonec AMD slibuje i podporu RAM taktované na 2400 MHz. Podmínkou ale je, aby paměť podporovala rozšířené profily AMP (AMD Memory Profile). Takovou paměť zřejmě uvede i samotné AMD, pochopitelně opět ve spolupráci s nějakým výrobním partnerem. Zdá se, že AMD také u pamětí přejde na značení Radeon R5/R7/R9; přičemž paměti s taktem 2400 MHz a AMP budou zřejmě označeny jako Radeon R9 a standardní 2133MHz moduly jako R7.

Kaveri - škálování výkonu GPU s taktem RAM
Použití pamětí s vyšším taktem by mělo značně pomoci výkonu integrovaného grafického jádra (pro srovnání: podobná dedikovaná karta Radeon HD 7750 má mnohem rychlejší 4,8GHz paměti GDDR5). Dle grafů od AMD nabízí slušný nárůst výkonu skok z 1600 MHz na 2133 MHz, u 2400MHz modulů je už zisk slabší, i když stále patrný.
Architektura Steamroller: na podvozku Bulldozeru, ale s lepším IPC
Ačkoliv na APU je třeba se dívat jako na kombinaci komponent, z technického hlediska je pochopitelně jednou z nejzajímavějších novinek nová architektura CPU, nazvaná Steamroller (parní válec). Ta vychází z linie započaté Bulldozerem a rozvíjené Piledriverem, po těchto dvou generacích je ale Steamroller první architekturou, která do koncepce přináší zásadní změny. Díky nim by měl poměrně významně narůst výkon na jeden MHz (IPC), který se mezi architekturou K10 a Bulldozerem zhoršil. Trošku paradoxní je, že AMD většinu informací o Steamrolleru zveřejnilo již prakticky před rokem a půl na konferenci Hot Chips 24 (v srpnu/auguste 2012). Na fyzickou dostupnost nové architektury jsme bohužel museli čekat až do této doby.

Parní válec, jiným slovy Steamroller (Autor: Barry Skeates, Wikimedia Commons)
Steamroller v zásadě přebírá modulovou koncepci Bulldozeru. Základem architektury Steamroller je tedy opět úzce integrované dvoujádro se sdílenými komponentami. Sdílená je celá FPU (která obsahuje také jednotky pro výpočet všech instrukcí typu SIMD a FMA3/FMA4), která zároveň počítá vlákna běžící na obou jádrech. Jádra samotná jsou tak vlastně klastry jednotek ALU a jednotek AGU pro přístup do paměti. Bulldozer mimo FPU mezi dvěma jádry v modulu sdílel ještě L2 cache, L1 pro instrukce cache a frontend. Právě v něm se zřejmě skrývala jedna ze zásadnějších achillových pat architektury – instrukční dekodér, který byl sdílený mezi oběma jádry a střídavě přepínal mezi oběma aktivními vlákny.
Steamroller od sdíleného dekodéru pro obě jádra v modulu upouští. V Kaveri tak budou mít obě jádra dekodér svůj, který budou moci plně vytížit i pokud je aktivní druhé jádro v modulu. Profitovat z této změny by měl ale jak vícevláknový, tak jednovláknový kód. Zdvojení dekodérů znamená, že lze lépe vytížit dostupné jednotky ALU a FPU. Dle AMD má být řazení instrukcí v rámci vykonávání kódu Out-of-Order efektivnější o nějakých 5–10 %.

Schéma architektury Steamroller
Frontend modulu doznal dále zlepšení co se týče predikce větvení kódu. Chyby prediktoru byly omezeny o 20 % (chování prediktorů je ale závislé na podobě kódu). IPC by mělo i vylepšené přednačítání dat z paměti a také optimálnější vykonávání zápisů. Procesor by měl lépe zvládat tzv. store-to-load forwarding, tedy situaci, kdy čte z paměti či cache data, která tam dříve sám zapsal, a opětovné čtení hodnoty lze tedy přeskočit.
Zatímco velikost L2 cache modulu a datové L1 cache obou jader zůstává u Steamrolleru (potažmo APU Kaveri) stejná, AMD přistoupilo k zvětšení instrukční L1 cache. Ta měla u Bulldozeru poměrně slušných 64 KB, byla však sdílená, a měla poměrně nízkou (dvoucestnou) asociativitu. AMD zřejmě její výkon považovalo za slabé místo, proto byla u Steamrolleru rozšířena o 50% na 96 KB. Sekce navíc zřejmě umožnila zvýšit asociativitu na třícestnou. I samotné zvýšení velikosti by ale mělo mít dopad na výkon. Dle AMD byly celkem o 30 % zredukován počet případů, kdy procesor při práci nenalezne v instrukční L1 potřebný kousek kódu.
AMD přepracovalo také uspořádání sdílené FPU. Ta v Bulldozeru obsahovala celkem čtyři jednotky či pipeline – dvě FMAC a dvě jednotky pro celočíselné SIMD. U Steamrolleru byl počet pipeline zredukován na tři, měly by ale obsahovat všechny funkční jednotky, které obsahovaly pipeline v bulldozeru, pouze se skrývají za menším počtem portů. Výpočetní propustnost by tedy měla být zachována, i když by teoreticky mohlo dojít k propadům výkonu v extrémních případech. Zdá se ovšem, že výkon v aplikacích, které intenzivně využívají instrukce SIMD, u Steamrolleru neklesl – o tom níže. Reorganizace FPU nicméně má snížit plochu CPU a také o něco zredukovat spotřebu.

Tabulka s orientačními údaji o nárůstu výkonu oproti architektuře Piledriver při stejném taktu (AMD).
Poznámka: U Cinebench R15 jsou přehozené výsledky Single core a 2C-4T.
Podle čísel, která pocházejí přímo od AMD, se výkon jader CPU při stejném taktu oproti Piledriveru (APU Richland) zlepšil až o 20 %, nicméně průměrný nárůst je nižší. Tabulku vidíte výše – nejlépe na tom je APU v enkódování videa pomocí programu x264, což je úloha, ve které podávaly relativně slušný výkon již Bulldozery a Piledrivery. Průměrné zlepšení IPC o 10 % je dobrým výsledkem, v reálu to nicméně není až taková výhra, neboť je kompenzováno obdobným snížím taktů (alespoň u 95W desktopových čipů). V poznámce AMD přiznává, že bez pomoci HSA a obecně grafického jádra zůstává výkon CPU spíše na úrovni loňských APU. Což by ale teoreticky mohly spravit pozdější modely s vyšším taktem, pokud se je firmě podaří uvést.
Co se týče podpory instrukčních rozšíření, zůstává Steamroller na stejné úrovni, kam se AMD dostalo s architekturou Piledriver. Jádra tedy umí SSE4, AES, XOP, AVX, FMA3 a FMA4, méně významné instrukce jako TBM, BMI1, F16C. Naopak se nekoná podpora novinek, které Intel přinesl s Haswellem – tedy AVX2, což jsou celočíselné instrukce SIMD nad 256bitovým vektorem a TSX, tedy podpora pro transakční paměť. AVX2 a některé další instrukce ale AMD uvede u další generace architektury, Excavatoru. Ten by měl bagrovat už v příští generaci APU, nazvané Carrizo, kterou zatím očekáváme na rok 2015.
Grafické jádro. GCN poprvé v APU
Grafické jádro je nadále enormně důležitou součástí APU. Stejně jako v předchozích generacích, i u Kaveri bude GPU, jemuž je na čipu vyhrazeno 47 % plochy muset kompenzovat nižší výkon CPU v porovnání s procesory značky Intel. Vedle samotného GPU klade AMD velký důraz též na různé akcelerátory s ním spojené, které s ním také představují ono „hetero“ v heterogenní výpočetní architektuře.
U Kaveri AMD konečně přechází na svou nejnovější architekturu GPU, označenou GCN – APU této řady budou konečně technologicky rovna aktuálním dedikovaným kartám. AMD sice již GCN nasadilo v loňských čipech Kabini, jenže „velká" APU, u nichž lze již mluvit o herních grafikách, doposud používala shadery staré architektury VLIW4. Samotná architektura GCN se pravda na trhu pohybuje již třetím rokem, nicméně v APU Kaveri AMD použilo její nejčerstvější revizi, přítomnou v novém GPU Hawaii (Radeon R9 290/290X). APU tak může těžit z optimalizací pro dedikované karty, teoreticky mu může hrát do karet i to, že sdílí architekturu s Xboxem One a Playstationem 4.

APU Kaveri - grafické jádro
Smysluplné CrossFire?
Díky architektuře GCN má také mnohem lépe fungovat hybridní CrossFire, tedy režim, kdy spárujete integrované GPU s dedikovanou kartou. Pokud je APU spjato s podobně výkonnou kartou, má docházet k poměrně efektivnímu zvýšení výkonu. Ideální je GPU má parametry co možná odpovídajícími – AMD zde doporučuje Radeon R7 240 s pamětí DDR3. Běh v tandemu s APU A10-7850K má údajně zhruba zdvojnásobit (+ 95 %) výkon této – pravda, ne nějak superrychlé – samostatné grafiky, a to při rozlišení 1920 × 1080 bodů.
Asymetrické CrossFire s dedikovanými grafikami nicméně poběží pořádně až po vydání ovladačů s číslem verze 13.35, neboť potřebné optimalizace (které mimo jiné souvisejí i s technologií Frame pacing) se ještě nedostaly do stabilního vydání. Integrované GPU má umět spolupracovat s jakoukoliv kartou založenou na GCN, ale jak už bylo řečeno, nejlépe to bude fungovat s rychlostně blízkými Radeony R7.

APU Kaveri - škálování výkonu v CrossFire s Radeonem R7 240
Podpora Mantle
Díky tomu, že běží na architektuře GCN, mohou integrované Radeony R7 také těžit z podpory pro grafické API Mantle. To má značně omezit výkonnostní bariéry, které klade architektura rozhraní DirectX, jenž je stále značně závislé na jednovláknovém výkonu. Obecně také jeho běh spotřebovává relativně hodně výkonu CPU, což následně může přiškrtit i grafický výkon – zejména, pokud je CPU slabší, jako u APU.

Mantle: Nárůst výkonu v demu, extrémně limitovaném procesorem
V testovacím demu Starswarm od Oxide Games je navozena situace, která toto úzké hrdlo výkonu poměrně extrémně odhaluje. APU A10-7850K spojené s Radeonem R9 290X v něm dosahuje pod DirectX méně než 10 fps; s použitím Mantle je ale stejná komplexní scéna schopna běžet až na 30 snímcích za sekundu. Vedle snížené náročnosti na CPU se projevuje též to, že Mantle umí lépe využívat více vláken. Relativně slabé CPU tak mnohem lépe živí i highendové GPU.

I v reálném hraní ale Mantle údajně dokáže vytvořit veliký rozdíl: 45 % výkonu navíc v Battlefield 4
Starswarm lze považovat za syntetické demo, takže tatko masivní nárůst nelze čekat v reálné herní scéně. Nicméně i tak můžou být dopady velké. AMD uvádí výsledky Battlefieldu 4, tedy první hře, která má vykreslování přes Mantle podporovat (patch ale postihlo určité zpoždění, takže přijde až někdy během následujících týdnů či měsíců). V této hře údajně APU A10-7850K s Radeonem R9 290X dokáže stále podat o 45 % lepší výkon než pod DirectX. Při nastaveních Ultra a rozlišení 1920 × 1080 bodů tato konfigurace dosahovala s Mantle 55 snímků za sekundu, zatímco s DirectX jen 38 (test s 8 GB DDR3 na 2400 MHz, deskou Asus A88X-Pro, Windows 8.1 a ovladačem Catalyst 13.11 beta 9.5).
Vedle Mantle umí APU Kaveri i druhou vymoženost, kterou AMD představilo spolu s uvedením čipu Hawaii, a sice akceleraci prostorového zvuku a audio efektů TrueAudio. Kaveri má integrováno patřičné DSP a jeho uživatelé tedy budou moci vyzkoušet akcelerovaný zvuk ve hrách, které budou TrueAudio podporovat (jak jsme psali v článku o této technologii, několik titulů již bylo oznámeno). Vedle herního audia je ale integrované DSP možno použít i k dalším výpočtům nad zvukovými daty – například pro potlačování šumu ve vstupu z mikrofonu.

Kaveri obsahuje také audio koprocesor TrueAudio
Jak Mantle, tak TrueAudio se již brzy mají objevit v ovladačích Catalyst. Knihovny s podporou se mají nacházet v ovladačích verze 14.1 beta, které vyjdou údajně ještě tento měsíc. Co se týče data vydání patche pro Battlefield 4, společnost Dice ještě konečný termín jeho dostupnosti neoznámila. Podle představitelů AMD by se však podpora Mantle v této hře měla dostavit brzy, tak se snad dejme tomu v lednu či únoru (januári/februári) dočkáme.
Multimédia a software
AMD do Kaveri také integrovalo novou generaci multimediálních akcelerátorů. Relativně malé změny se týkají obvodu UVD, jenž má dostat robustnější dekodér pro formát H.264 – bude tedy snášet i abnormální streamy a zejména bude použitelnější třeba při ztrátě packetů na síti či jiných přenosových potížích. AMD zatím nepřineslo podporo pro dekódování formátu HEVC (alias H.265). Podle toho, co zatím víme, ji ale nemají mít ani procesory Broadwell. Dekódování H.265 tedy bude probíhat na CPU, nicméně na trhu by se údajně měly objevit softwarové ovladače používající alespoň částečnou akceleraci pomocí OpenCL/HSA (AMD uvádí Telestream Switch).

UVD 4 v Kaveri
Fluid Motion Video coby náplast na 60Hz monitory
Kaveri však dostane jinou zajímavou novinku týkající se sledování videa, a to technologii nazvanou Fluid Motion Video. Jedná se o řešení situace, která nastává prakticky při každém sledování filmu na počítači. Zatímco zdrojové video má frekvenci 24 snímků za vteřinu, počítačové obrazovky prakticky vždy běží na 60 Hz. Při vykreslování tedy musí GPU kreslit snímky v průměru dvaapůlkrát, což znamená, že snímky jsou střídavě zobrazovány třikrát a dvakrát. Podobně jako microstuttering při hraní toto vede k nepříjemnému cukání obrazu, který lze pozorovat při plynulých zoomech, rotacích a pojezdech kamery, či pokud je na obrazovce plynule se hýbající objekt.

AMD Fluid Motion Video
AMD Fluid Motion Video tuto nepříjemnost řeší tak, že snímkovou frekvenci zvýší na 60 Hz pomocí interpolace. Kvalita této konverze bude pochopitelně záležet na tom, jak dobře bude algoritmus rozpoznávat pohyb a jak kvalitně bude syntetizovat nové snímky. Pokud vše bude fungovat dobře, bude pohyb mnohem plynulejší než i při přehrávání na nativních 24 Hz. Konverze snímkové frekvence by měla běžet na GPU a fungovat by snad měla v rámci existujících přehrávačů videa založených na frameworku DirectShow. Snad by tedy mohla fungovat transparentně v rámci vykreslovače, i když to jen spekuluji; teoreticky také může vyžadovat dekódování na UVD, aby mělo GPU k dispozici informaci o pohybových vektorech ve videu.
Nicméně s přepočítáváním je obvykle spojen určitý úbytek kvality, neboť program jednoduše není vševědoucí a v mnoha případech jednoduše není správné interpolace schopen – zejména pokud dochází k pohybu nepravidelnému, na scéně se něco objevuje, mění se osvětlení. Interpolace obecně dosti špatně funguje například u kreslené animace. Použití Fluid Motion Videa tedy asi bude záležitostí vkusu (osobně bych preferoval raději přehrávání na kompatibilní frekvenci, tedy 24/48/120 Hz, či řešení tohoto problému pomocí G-sync či FreeSync). Každopádně ale bude zajímavé vidět, jak dobře v AMD algoritmus zvládli.

VCE 2 v Kaveri
Větší změny než u UVD nastaly o enkodéru VCE. Kaveri nese jeho druhou generaci, která je oproti té první v čipech Trinity poněkud schopnější. Zatímco původní VCE kódovalo H.264 s omezenými schopnostmi (umělo například jen snímky typu I a P), Kaveri by mělo kvalitu výstupu o něco zlepšit (umí už i snímky s obousměrnou predikcí, tzv. B-frames).
VCE 2 ale přináší zlepšení kvality i pro bezdrátový přenos obrazu AMD Wireless Display. Pro jeho potřeby dokáže enkodér video komprimovat ve formátu se vzorkováním 4:4:4, takže nedochází k rozmazávání například červeného textu kvůli podvzorkování kanálů chroma U/V. Tento režim je zejména důležitý pro kvalitní a ostré zobrazení GUI programů a operačního systému, a často také textu. Vzorkování 4:4:4 ale VCE 2 zřejmě umí jen při intra-kompresi, takže AMD má co zlepšovat. Pokud by totiž enkodér zvládl i P-snímky, mohly by se snížit nároky na přenosovou rychlost bezdrátové sítě či zvýšit kvalita. Pochopitelně by ale byla nutná podpora i ze strany přijímače.
Akcelerace přes HSA stále vyžaduje podporu vývojářů
Úspěch, s jakým se bude AMD dařit dohánět výkonnostní deficity APU oproti Core i5 a i7 pomocí akcelerace na GPU, bude záviset zejména na softwarové podpoře OpenCL, HSA ale i speciálních akcelerátorů. AMD ve svých tiskových materiálech k uvedení Kaveri poukazuje třeba na podporu HSA v grafických programech společností Adobe a Corel (Adobe Photoshop a Corel Aftershot Pro), kde by měly být akcelerovány vybrané filtry.

Multimédia a GPGPU akcelerace na APU Kaveri
Dalším potenciálně zajímavým softwarem, kterému se dostalo akcelerace přes HSA, je kancelářský Libre Office. Pomocí OpenCL v něm má být akcelerováno přes 100 funkcí tabulkového procesoru Calc. Výpočet vzorců v rozsáhlých tabulkách přitom dokáže být poměrně náročnou záležitostí, takže v tomto případě je významné zrychlení vítanou věcí.

AMD pro Kaveri vyvinulo akcelerovaný dekodér formátu JPEG, který nahradí systémovou knihovnu ve Windows
Přímo AMD také naprogramovalo akcelerovaný dekodér obrázků ve formátu JPEG, díky kterému budou APU Kaveri moci rychleji dekódovat fotografie či grafiku na webových stránkách. Dekodér by měl být součástí ovladačů a nahradí standardní systémovou knihovnu ve Windows, takže by se výkonnostní zlepšení (výsledky v tabulce změřilo AMD na čipu A10-7850K) měla projevit ve všech programech, které systémový dekodér používají. Vhod to přijde zejména o fotografií s vysokým rozlišením, nebo při vytváření náhledů složek.
Kaveri bude pochopitelně profitovat z podpory „obyčejného“ OpenCL, již existující v aplikacích. Kód optimalizovaný přímo na architekturu HSA se asi bude objevovat pomaleji; zase by ale teoreticky mohl poskytovat přesvědčivější výkonnostní nárůsty. AMD uvádí, že o stažení SDK pro programování nad touto technologí je poměrně velký zájem, tak doufejme, že se konečně pomalu začne ukazovat, že ona „Fusion“ má nějaký významnější dopad.

Open source software akcelerovaný přes OpenCL

Další akcelerované programy
Závěr
Tolik tedy zatím k desktopovým APU Kaveri. Recenzi jednoho z obou dostupných čtyřjader si zde bohužel zatím nepřečtete, takže dnes musíme skončit v oblasti teorie.

Nová APU přinášejí poměrně zásadní inovaci jak v CPU, tak v GPU, svou hodnotu ale budou muset ukázat i praktickým výkonem. A to zejména vzhledem k tomu, že v poslední generaci (či půlgeneraci) Richland výkon zejména grafiky až tak moc nenarostl. Kvůli nízkým frekvencím to však s tím „přesvědčováním“ architektura Steamroller nebude mít lehké. Méně než o CPU už bych se bál o tradičně silné (na integrovanou grafiku) GPU. I okolo ní ale kolují informace, že se AMD nepodařilo dosáhnou původně předpokládaných taktů – ostatně v minulosti AMD v prezentacích u Kaveri slibovalo celkový výkon vyšší o nějakých 150 GFLOPS. Příchod Kaveri vlastně trochu připomíná APU Llano, které coby první čip AMD na 32nm procesu (tehdy ještě SOI) také přišlo s překvapivě nízkými takty.
Otevřená je pochopitelně možnost, že AMD postupně uvede ještě o něco výše taktované modely (prostor by mohl být zejména u GPU). Zda je ale pro takový upgrade prostor a zda s tím AMD počítá, pochopitelně nevíme.








































