V oblasti CPU a GPU, či AI procesorů soutěží firmy o to, kdo nabídne nejvyšší výkon v dané kategorii, přičemž faktor, který je limituje je velikost čipu, který je maximálně možné vyrobit na křemíkových procesech. Ve vyždímání tohoto potenciálu byla lídr Nvidia, která už v roce 2017 dostala GPU Volta GV100 přes 800 mm² a dostala se asi na samý limit toho, co TSMC dokáže. Tyto limity mají monolitické čipy doteď.
Pak je tu ale kategorie, která je vysoko nad tím. Firma Cerebras se rozhodla, že nabídne výkon za hranicemi, které klade maximální velikost čipu. Předloni jsme tu psali o jejím AI akcelerátoru WSE – Waffer Scale Engine. Při běžné výrobě se postupuje tak, že se čip tvořící čtverec či obdélník replikuje vedle sebe na waferu (křemíkové desce) a po výrobě se tyto kousky od sebe rozřežou. Cerebrases WSE na to jde jinak.
Sice také na waferu vytváří jednotlivé replikované bloky, ale nerozřezává wafer (odstraní se jenom okraje okolo výsledného bloku, který má celkovou plochu 46 225 mm²). Firma místo separace těchto vyrobených čipů naopak dělá to, že přemostí vodiči dělící prostor mezi jednotlivými bloky, a tím z nich opět udělá celek. Současnou technologií nelze udělat z jednoho waferu jeden obří čip (protože velikost oné jedné části, která se replikuje, je omezená na těch něco přes 800 mm²), ale technologie Cerebras toto omezení obchází tím, že propojení aplikuje na wafer druhotně po jeho výrobě.
 Cerebras Wafer Scale Engine (první generace) srovnaný s GPU Nvidia Volta GV100 (Zdroj: Cerebras)
Cerebras Wafer Scale Engine (první generace) srovnaný s GPU Nvidia Volta GV100 (Zdroj: Cerebras)Výsledkem je „čip“, který má obrovské množství paralelních jader, což se dobře hodí pro akceleraci AI aplikací. Cerebras WSE je určený speciálně pro ně a díky monstróznímu množství tranzistorů, které dokáže na problém vrhnout, má zejména pro trénování neuronových sítí výkon, který tvoří kategorii samu o sobě proti běžným řešením z jednoho čipu, takže se tento procesor prodává za velmi vysoké ceny (údajně přes 2 milionů dolarů).
Wafer Scale Engine 2: 7nm proces umožní víc než dvojnásobek jader a paměti
V roce 2019 byla uvedena první generace WSE na 16nm procesu TSMC, která měla celkově nějakých 400 000 jader a 1,2 bilionu tranzistorů. Teď má Cerebras novou generaci, Wafer Scale Engine 2. Ta přešla na 7nm proces TSMC (N7, tedy stejný, na kterém vznikají Ryzeny 3000, 4000 a 5000 a také Radeony RX 5000 a 6000) a dosáhla víc jak dvojnásobné hustoty tranzistorů. Procesor vypadá velmi podobně a má stejnou plochu (v součtu 46 225 mm²). Už je v tom ale rovnou 2,6 bilionu tranzistorů.
Celý procesor má proti 400 000 jader v první generaci okolo 850 000 AI jader. Wafer Scale Engine nese přímo v křemíku také velké množství integrované paměti SRAM, která tvoří jeho pracovní prostor, díky němuž nemusí používat externí paměť jako třeba GPU. První generace obsahovala okolo 18 GB, což 7nm WSE 2 navýšil už na 40 GB paměti. Ta má celkovou propustnost (půjde asi o součet propustnosti jednotlivých bloků uvnitř celého megačipu) 20 PB/s a propustnost propojovací logiky mezi bloky čipu a jádry má být až 27,5 PB/s. Tyto parametry jsou 2,22× lepší než v první 16nm generaci.

Jak asi víte, při výrobě CPU nebo GPU se firmy musí potýkat s přítomností defektů na waferu (wafer, kde by všechny čipy byl zcela bez vady je velká vzácnost). U malých čipů je to jednoduché, malé procento čipů, do nichž se nějaký wafer strefil, se vyhodí. U velkých čipů jako je GPU nebo CPU ale jeden defekt vyřadí mnohem větší jednotku plochy, takže se musí počítat s redundancí. Takový čip se zachrání tím, že se deaktivují příslušná jádra nebo jednotky GPU a protože zbytek funguje, může se čip prodat jako nižší konfigurace. Někdy se dokonce ani nepočítá s tím, že by se plně aktivní konfigurace někdy použila (případ konzolových APU, která musí mít všechny stejné parametry).
Přes 12 000 jader jen jako rezerva pro defekty
Cerebras nemůže žádnou část waferu vyhodit, protože v rámci své šachovnice musí fungovat všechny. Je to proto řešeno tak, že každé z jader na tomto složeném megačipu lze vypnout a akcelerátor dál funguje, protože toto jádro nahradí ostatní. Cerebras uvádí, že původně mělo být asi 1,5 % jader (při 850 000 na celém procesoru by to bylo 12 750 jader) vyhrazeno jako rezerva, která může být „sežrána“ defekty. Nakonec ale prý firma zjistila, že 7nm proces TSMC má tak nízkou defektnost a je tak zralý, že toto množství je výrazně víc, než je třeba (je ovšem pravda, že v tuto chvíli už je proces pár let starý a díky tomu vyladěný).
Wafer, respektive z něj vzniklý WSE, který vidíte na fotkách, má hodně vysokou spotřebu (představte si, že by se do desky o průměru 30 cm soustředila spotřeba všech procesorů nebo GPU, které se z ní vyrobí a rozřežou). Je proto potřeba hodně silné speciální vodní chlazení. Výsledný systém CS-1 (s 16nm první generací) tak obsahuje jen jednu desku WSE, ale infrastruktura okolo potřebuje rozměrný server, který má v racku výšku 15U, obsahuje dvanáct 100Gb síťových adaptérů Ethernet a 12 (2×6 redundantně) napájecích zdrojů o celkovém špičkovém výkonu až 23 000 W.
WSE 2 vyjde v Q3 2021
Podle firmy by druhá generace WSE 2 a na ní založený systém CS-2 měla vyjít letos v třetím kvartálu. CS-2 má být velmi podobný systému CS-1, takže by měla zachovat stejnou konektivitu a příkon, ovšem dosáhne díky výkonnějšímu srdci vyšší výkon.
Cena jednoho systému CS-1 je údajně přes 2 miliony dolarů (pokud to nečtu špatně a toto není jen částka za samotné křemíkové „plato“ bez provozní infrastruktury okolo). Druhá generace bude ale výrazně dražší, má stát „několik milionů dolarů“.

Uživateli systémů Cerebras první generace jsou zejména výzkumné instituce a procesory slouží pro simulace při výzkumu nemocí a léků včetně rakoviny, COVID-19, ale i dalších komerčních a státních využitích (architektura je vedle AI údajně použitelná i na vědecké simulace, simulace kapalin nebo genomiku). Systém by měly mít americké národní laboratoře Argonne, Lawrence Livermore, výpočetní centra v Pittsburghu, Edinburgh a dalších, někdy je WSE integrovaný do konvenčního superpočítače. Vyšší výkon druhé generace by část těchto uživatelů mohl vést k upgradům, ale také asi přitáhne další zákazníky, kterým unikátní výkon dokáže vydělat peníze nebo poskytuje možnost řešit do té dobyu nepraktické výpočetní problémy.


Proti běžným monolitickým čipům přináší opravdu Cerebras úplně odlišnou úroveň výkonu. Ovšem je možné, že teď s příchodem čipletových technologií a pokročilého pouzdření a propojení začne WSE pomalu dostává konkurenci. Třeba výpočetní GPU Intel Ponte Vecchio pro superpočítač Aurora sice nemá zdaleka takovou šílenou celkovou plochu jako Cerebras WSE, ale na poměry ostatních konkurentů „vrhá na problém“ také nebývalé množství křemíku, kdy jedno „GPU“ obsahuje přes 40 čipletů. V dalších generacích může Intel množství čipletů a plochu křemíku (a tím počty tranzistorů) posunout ještě dál, takže takovéto designy budou možná jednou WSE konkurovat. Tato extrémní řešení v budoucnu zdá se budeme vídat častěji.
Galerie: Cerebras Wafer Scale Engine 2
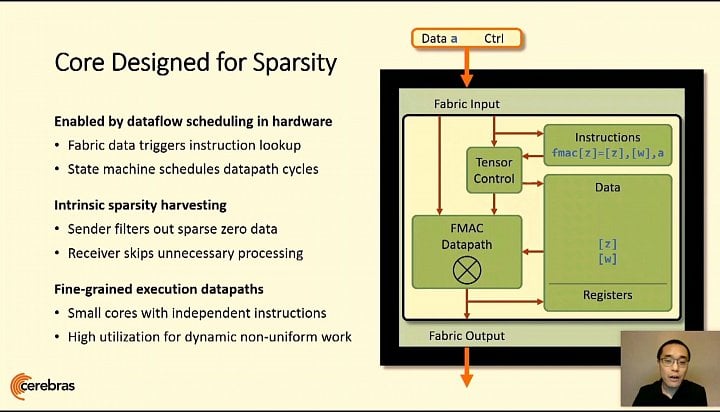



Zdroj: AnandTech











































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU