
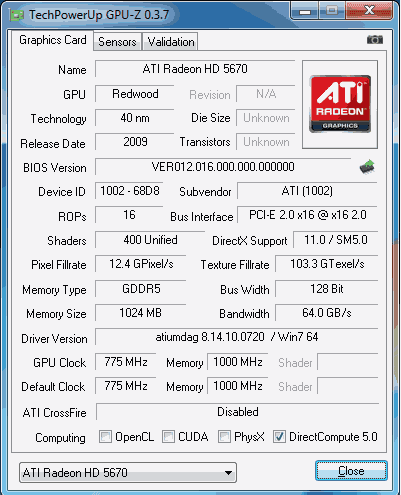
Jaký bude Radeon HD 5670 a oč je lepší HD 5000 než HD 4000?
Díky předčasně vydané recenzi Radeonu HD 5570 serveru IT168.com (zde automatický překlad do češtiny) jsme se dozvěděli oficiální specifikace čipu RV830 "Redwood" včetně parametrů nejvýkonnější karty, která ho bude využívat – Radeonu HD 5670. V mnoha ohledech jde o parametry jádra velmi blízké stávajícímu Radeonu HD 4670, viz následující tabulka:

Pokud bychom vzali v potaz možný rozdíl výkonu triangle setup enginu daného frekvencí (tzn. také +3 %*), byl by průměrný rozdíl všech parametrů roven nule.
* výkon triangle setup enginu nebývá u mainstreamových a low-end čipů zdokumentován a někdy se liší oproti high-endu (bývá např. poloviční v některých – blíže nespecifikovaných – situacích a podobně)
Tato čísla mohou vyznívat poněkud skepticky, neboť se poslední – byť papírově nejvýraznější – rozdíl týká frekvence pamětí. Ta je díky použití GDDR5 modulů oproti Radeonu HD 4670 sice dvojnásobná, ovšem její vliv na výkon u čipu RV730 byl velmi nízký (přetaktování pamětí o 10 % znamenalo nárůst výkonu na úrovni 2–3 %). I kdybychom zohlednili nárůst paměťové propustnosti, bylo by jen těžko možné očekávat výkon přes 10 % nad starou HD 4670. Odkud se tedy bude brát výkon HD 5670?
Přicházejí multifunkční interpolátory
Generace Radeonů HD 5000 přinesla jednu novinku, která není příliš na očích, a o které se zatím příliš nemluvilo, neboť v případě high-endových produktů nebyl její vliv tak výrazný, jaký může přinést nižšímu mainstreamu. Mluvím o jednotkách, které v recenzích příliš zmiňované nejsou – o multifunkčních interpolátorech. Jedním z jejich účelů je (zjednodušeně řečeno) aplikovat výsledek texturovací jednotky na polygon.
Některé základní operace (bilineární filtrace, point sampling) zvládá texturovací jednotka v jednom taktu. Pokud chceme, aby byl tento potenciál využit, musí být i interpolátorů stejný počet, jako texturovacích jednotek; např. 32:32, tzn. poměr 1:1, aby stíhaly všechna data dál zpracovávat.
V některých situacích ale výrobce může narazit na případ, kdy snížení počtu interpolátorů v čipu vede jen k minimálnímu poklesu výsledného výkonu, ale k citelnému snížení rozměrů čipu (lepší poměr cena/výkon). To se týká především situací, kdy je výkon čipu limitován jiným faktorem a plný počet interpolátorů by byl nevyužit. V případě RV730 (HD 4670) šlo o limitaci propustností paměťové sběrnice. Nebyla taková, aby mohl být potenciál všech 32 texturovacích jednotek plně využit, takže ATI osadila pouze 16 (polovinu) interpolátorů.
To je také jedním z důvodů, proč rychlejší paměti výkonu RV730 příliš nepomáhají; v případě osazení výkonnějších pamětí se limitem stává rychlost interpolace. U Radeonů HD 4800 (RV770/790) se tento problém projevoval v minimální míře, neboť texturovacích jednotek bylo 40 a interpolátorů 32 (osm čtveřic).

Architektura Radeonů HD 5000 tento přístup změnila, multifunkční interpolátory vynechala a jejich funkci přesunula na unifikované jádro (detaily níže). Tím dochází k situaci, kdy mizí další limit, který může omezovat výkon: Radeonu HD 5670 je tím dovoleno efektivněji vytížit texturovací jednotky a paměťovou sběrnici, což teoreticky může znamenat až dvakrát vyšší škálování výkonu v situacích dosud limitovaných rychlostí interpolace a až dvakrát efektivnější škálování na paměťové propustnosti.
Jak rychlý HD 5670 bude?
V praxi můžeme očekávat až dvakrát lepší výsledky v testech zaměřených na specifické efekty (= situace, kde byl potenciál RV730 omezen interpolátory na polovinu). Vliv na herní výkon bude zřejmě značně proměnlivý a závislý na dalších aspektech, hlavně nárocích hry na paměťovou propustnost. Ve výjimečných situacích – kdy aplikace nebude schopna využít ani vyšší propustnosti paměti, ani dvojnásobného výkonu při interpolaci – můžeme očekávat výsledky jen mírně nad RV730/HD 4670, ale v ostatních případech není nereálná zhruba třetina výkonu navíc.
Takový rozdíl se z hardwarové stránky jeví jako velmi zajímavý – RV830 nese pouze o 20 % více tranzistorů než RV730, přičemž jejich valná část padla na podporu DirectX 11. Jde tedy o velký krok vstříc efektivitě a výkonu na jeden tranzistor. Zda se stejným způsobem zlepší i poměr výkonu na jeden watt si budeme muset počkat; tyto detaily zřejmě prozradí až recenze po skončení NDA.
P.M.I., texturovací jednotky a záhada obdélníkového čipu
Slyšeli jste už o P.M.I.?
Koho zajímají technické detaily blíže, toho možná osloví následující část článku, kde princip multifunkční interpolace vysvětlím podrobněji:
V době vydání Radeonů HD 5000 v několika recenzích a prezentacích padl termín P.M.I. Pro nejsrozumitelnější vysvětlení jeho významu bude nejlepší začít u textury.
Samotná práce s texturou začíná addressingem (adresováním). Každá textura má dva typy souřadnic – jeden, který se vyjadřuje v pixelech (např. u textury velké 512 × 512 si asi dokážete představit souřadnice 12, 50,…) a druhý je dán rozsahem 0 – 1 (kde 0 je jeden okraj a 1 je druhý). Pomocí těchto souřadnic je třeba určit správnou část textury, se kterou se v danou chvíli bude pracovat. Toto zastává z valné většiny texture-addressing unit (TAU), která je součástí texturovací jednotky.
Filtrace textur – ať bilineární, trilineární, nebo anizotropní – provádí TFU (texture filtering unit) – také součást texturovací jednotky. Tohle je myslím v základu poměrně známé.

Texturovací jednotky ATI obsahují samostatnou část, která provádí adresaci a samostatnou část, která provádí filtraci. Nvidia má texturovací jednotky u posledních čipů navržené tak, že po HW stránce sdílí část pro potřeby adresace i filtrace. Jednotka buďto adresuje, nebo filtruje – obojí najednou realizovat nemůže, snad jedině pro point sampling (?).
Když je textura připravená, je třeba ji nanést na příslušný polygon, resp. trojúhelník/triangl. S tím souvisí atributová interpolace (attribute interpolation, český název se moc nepoužívá). Každý roh polygonu má přiřazené určité atributy, většinou jde o barevné, normálové a texturové souřadnice/koordináty. Při samotné rasterizaci je potřeba vypočítat příslušnou hodnotu těchto atributů pro každý pixel onoho polygonu. Tyto hodnoty se vypočítávají zmíněnou interpolací (z těch rohových).
Interpolaci prováděly u ATI dosud (-R7xx) samostatné automatické aritmeticko-logické jednotky, které jsou pro ni určené (multifunkční interpolátory), zatímco u Nvidie ji (od G80 výše) provádí určitá část unifikovaného jádra. V souvislosti s tím vyvstává otázka, zda tento systém zbytečně nekonzumuje výkon unifikovaného jádra, který by byl potřeba jinde, např. pro pixel shading. Jednoznačná odpověď bohužel neexistuje, opět závisí na poměru ALU:TEX, který daný čipy nabízí.
Pokud je aritmetický výkon nízký a texturovacích jednotek mnoho, může dojít na situaci, která potkala první generaci low-end a mainstream unifikovaných čipů Nvidie (GeForce 8500, 8600). Ty měly pro zachování malých rozměrů velmi nízký poměr ALU:TEX, takže docházelo k situaci, kdy byla pro účely interpolace ukrojena přílišná část výkonu unifikovaného jádra a herní výkon byl nižší, než parametry naznačovaly. Nvidia si z toho ale vzala ponaučení a u nástupcem (G94/GeForce 9600 GT) byl poměr ALU:TEX upraven rozdílem frekvencí obou domén. GT200 šla o krok dál navýšením počtu SPs v rámci TPC o 50 %. Fermi má poměr ještě o třetinu zlepšit, ale není potvrzeno, zda interpolaci bude provádět stále SFU – na detaily musíme ještě čtvrt roku počkat.

ATI fixní interpolátory odstranila až na současné generaci čipů, která od low-endu po high-end nabízí vysoký poměr ALU:TEX (4:1), takže negativní dopady na výkon nehrozí. (U R6xx a R7xx měly produkty nižších cenových segmentů poměr snížený na 3:1 a 2:1).
Pokud už mluvíme o interpolátorech na dosavadních čipech ATI (do RV7xx včetně), hodilo by se ještě připomenout, že jejich množství nebylo závislé na unifikovaném jádře, texturovacích jednotkách, ani celých SIMDs. Možná si pamatujete, že relativně nedlouho před dokončením vývoje, kdy návrh RV770 nesl ještě 8 SIMDs (640 SPs) a 8 čtveřic interpolátorů, došlo k rozhodnutí, že se pro zvětšení plochy jádra (potřebné pro side-port, resp. pro dostatečný počet pads na spodní straně čipu, aby bylo umožněno side-port vyvést ven) do čipu umístí 2 SIMDs navíc (celkem 800 SPs). 8 čtveřic (32) interpolátorů ale už zůstalo, k navýšení nedošlo, takže ve velmi specifických situacích, kdy se nepoužívá trilineární ani anizotropní filtrace, může docházet k mírné limitaci výkonu (řádově odhaduju jednotky procent v reálných hrách).
Vraťme se ale k principu, jak interpolace na RV770 a starších funguje. Jak jsem zmínil, jde o interpolaci automatickou, neboli statickou. Ta je realizována pro atributy všech vrcholů vždy když dojde k rasterizaci příslušné skupiny pixelů (každá jednotka je schopna interpolovat jeden vec4 atribut pro 32 fragmentů v taktu). Výsledek je uložen jako data registru, se kterými dál může pixel shader pracovat.

Systém P.M.I. nahradil současný statický model interpolace. Jeho implementace je zároveň krokem vstříc DX11. Stanovuje, aby interpolace vertex atributů byla prováděna "on demand" („na požádání“). To funguje tím způsobem, že čip zdrojová atribute data uchovává ve sdílené paměti a interpolace je provedena až v okamžiku, kdy je potřeba (a je provedena unifikovaným jádrem – to už ale s požadavky DX11 nesouvisí, to už je způsob konkrétního přístupu, který si každý výrobce může zvolit).
Zátěž na unifikované jádro může být z výše uvedených důvodů nižší, než jakou nesly samostatné jednotky. Výkon menších čipů (které nebývaly vybaveny plným počtem interpolátorů) se díky tomu může výrazněji blížit teoretickým parametrům.
Cypress = 2× Juniper?
Již před vydáním čipu RV870 (Cypress, Radeon HD 5800) se objevilo nezvykle mnoho spekulací poukazujících na určitou formu „vícejádrovosti“ tohoto čipu. Absence fotografie jádra ("die-shot") v kombinaci s duálním rastrizérem tuto domněnku na nějaký čas přiživila, ale postupem času se o této možnosti mluvit přestalo. Uklidněnou hladinu rozčeřilo nové schéma čipu zveřejněné na prosincové prezentaci ze SIGGRAPH 2009, které skutečně RV870 (HD 5800) vykresluje jako čip, jehož hlavní část je složena ze dvou identických (pouze zrcadlově otočených) bloků, které odpovídají layoutu RV840 (Juniper, HD 5700).
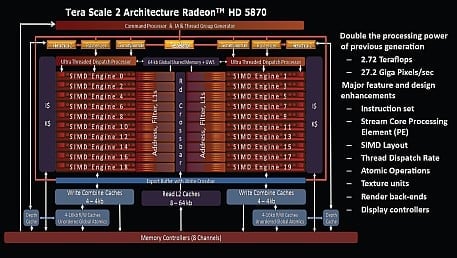
Architektura Radeonu HD 5870 detailněji než v první vlně recenzí: prezentace AMD ze SIGGRAPH 2009
To by vysvětlovalo mnoho. Od duálního rasterizéru přes vícejádrové spekulace až po vydání RV840 a RV870 téměř současně. Stejně tak i (nečekaně) obdélníkovitý tvar RV840. Standardně jsou mainstreamové produkty vydávány s mnohaměsíčním odstupem; nejprve je připraveno high-end jádro a až po jeho dokončení se síly soustředí na nižší deriváty.
V souvislosti se současnou generací produktů ATI se ale zdá, že základní blok (800 SPs + 40 TMUs) byl vyvinut samostatně a použit 1× pro RV840 a 2× pro RV870. Takový přístup by významným způsobem zkrátil vývoj čipu a urychlil příchod mainstreamových produktů. Podmiňovací způsob v poslední větě již asi není nutné používat, ovšem ne vše se zdá být jasné; konkrétní způsob propojení obou bloků v rámci RV870 je zatím zahalen rouškou nejasností.













































