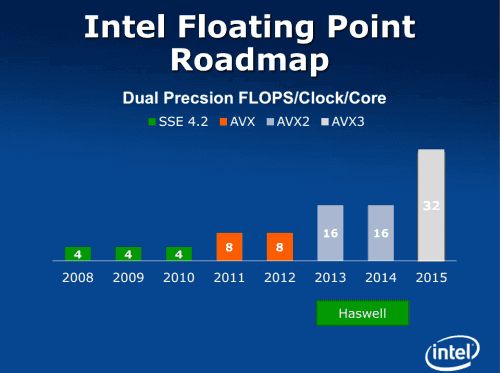
AVX-512 bude umožňovat do 512bitového vektoru, který používají, zahrnout (a tím zpracovat v jedné instrukci) osm 64bitových celočíselných hodnot nebo „floatů“ s dvojitou přesností. Při jednoduché přesnosti nebo 32bitových celých číslech se pak do vektoru (a potažmo registru) vejde hodnot šestnáct. Menší (8bitové či 16bitové) celočíselné hodnoty a instrukce pracující s nimi, které se hodí například v multimediálním kódu, zřejmě přijdou až později (v hypotetickém 512bitovém rozšíření sady AVX2). Počty v plovoucí řádové čárce ze začátku využijí zejména vědecké výpočty, různé simulace a další náročné úlohy; ve sféře osobních počítačů bude minimálně ze začátku jejich efekt minimální.

Slajdy k 14nm procesorům Intel Skylake
Stejně jako SSE a AVX, i AVX-512 znamená přidání nových registrů do procesoru, takže k jejich využití budete potřebovat podporu operačního systému. Nové 512bitové registry se stejně jako na Xeonu Phi označují ZMM. Je jich celkem dvaatřicet (a k tomu osm dalších vyhrazených pro masky). Prvních šestnáct registrů je namapováno do registrů YMM0 až YMM15 sady AVX (instrukce AVX tak budou pracovat s nižšími bity z celkové šířky). Dle Intelu ale v procesorech nebude docházet k výkonnostním problémům při mixování instrukcí AVX a AVX-512, což je bolest současných CPU Intel (při přepínání mezi instrukcemi SSE a AVX dochází k dlouhým prodlevám, na které musí programátor či překladač dávat pozor, jde nicméně o vlastnost implementace, nikoliv instrukční sady samé).
Slajdy k 14nm procesorům Intel Skylake
AVX-512 ale nebude automatickým rozšířením AVX. Místo kódování VEX se údajně používá nový prefix EVEX. Je o bajt delší, což o něco nafoukne velikost přeloženého kódu a tím zátěž datové L1 cache, nicméně bude umožňovat určité nové funkce. Zdvojnásobení šířky vektoru (tedy zdvojnásobení počtu hodnot, s nimiž se najednou počítá), každopádně slibuje i dvojnásobný výkon u operací, které tuto výpočetní kapacitu budou schopné využít. V praxi pochopitelně zrychlení aplikací budou menší, neboť SIMD se většinou dá aplikovat jen na část programu a kritická sekce i tak nemusí být plně rozšiřitelná na AVX-512.
Dokumenty Intelu potvrzují přítomnost AVX-512 v čipu Knights Landing, což by měla být příští, 14nm generace Xeonu Phi. Kdy se tohoto instrukčního rozšíření dočkají i klasické procesory, Intel zatím nesdělil, takže se budeme muset spolehnout na již zmíněné neoficiální informace, že by se tak mohlo stát v příštím „tocku“, tedy u 14nm architektury Skylake, která přijde po Broadwellu, zřejmě v roce 2015.

Xeon Phi - aktivně a pasivně chlazené varianty
Na využití a podpoře pro nové instrukce už Intel údajně pracuje s vývojáři překladačů a operačních systémů (včetně těch ze světa svobodného softwaru). Pokud máte o nízkoúrovňové programování či psaní kódu v assembleru zájem, můžete se podívat do dokumentace nových instrukcí. K dispozici je již i softwarový emulátor, na kterém lze vše testovat, dokud nebude Knights Landing dostupný (případně i poté, protože jeho pořízení nebude asi nic levného).

Zdroj: Intel







































