
Procesory s architekturou ARM zatím moc nenaplnily hrozbu, která v nich byla spatřována pro zavedenou architekturu x86 (a potažmo čipy Intelu), pokud jde o nasazení v serverech. Ovšem nedávno do této oblasti oficiálně vstoupil silný hráč v podobě Qualcommu, jenž loni v prosinci oznámil 10nm procesory se jménem Centriq (v první generaci Centriq 2400), což by měly být docela těžkotonážní procesory s nijak skromnými ambicemi. V případě úspěchu by tedy mohly řádně zkomplikovat situaci Xeonům od Intelu, ale i Epycům od AMD, které se právě také snaží proniknout do lukrativního trhu, který si Intel téměř celý zabral pro sebe. Qualcomm nyní k těmto svým serverovým CPU zveřejnil detaily, vrhající na Centriq a jeho architekturu první světlo.
Centriq 2400 používá 48 jader na míru navržené architektury nazvané Falkor. Vzhledem k tomu, že v mobilních čipech Qualcomm stále častěji používá místo vlastních jader licencované Cortexy, by mohlo vznikat podezření, že něco podobného nastane i zde. Ovšem Falkor by měl být údajně skutečně „čistý Qualcomm“. Falkor má představovat pátou generaci jeho vlastní architektury. Přímo údajně není z mobilních jader Krait a Kryo odvozen, pracovali na něm ale stejní inženýři (což trochu pobízí ke spekulacím, zda firma neopustila v mobilním segmentu své Kryo právě z tohoto důvodu).
 Qualcomm Centriq 2400
Qualcomm Centriq 2400Podle Qualcommu byl při návrhu primárně sledován vysoký výkon, následně je ale jádro optimalizováno na co nejlepší spotřebu. Architektura byla od počátku údajně cílena na servery, což odráží třeba to, že vůbec nemá kompatibilitu s 32bitovým režimem (instrukční sadou ARMv7), podporována je jen 64bitová instrukční sada ARMv8.
Dvoujádrové moduly
Základní jednotkou architektury Falkor je dvoujádrový modul, ovšem spíše než známým Bulldozerům je podobný čipům Core 2 a Atom či Xeon Phi. Jádra nemají sdílené jednotky, ale L2 cache je pro obě společná. Privátní jsou jen L1 cache. Tento „duplex“ má také společné připojení ke zbytku procesoru, což podobně jako u Xeonu Phi zjednodušuje propojovací logiku, jelikož uzlů v síti je jen 24 místo 48.
 Základní duplex s dvěma jádry Falkor
Základní duplex s dvěma jádry FalkorL2 cache má jinak být inkluzivní k L1, mít osmicestnou asociativitu, ECC a údajně „minimální“ latenci 15 cyklů, kapacita zatím prozrazena nebyla. Obě CPU v duplexu by měla mít nezávislé řízení spotřeby a separátně má být ovládána i cache. Jádra budou podporovat clock gating i odpojení od napájení. Vstupování a probouzení z úsporných stavů jsou ovládány na hardwarové úrovni.
Falkor: jádro dělané pro 3–4 instrukce za takt
Qualcomm zveřejnil popis vnitřního uspořádání jádra, z kterého lze do určité míry hádat IPC. Jádro Falkor má tři dekodéry, takže dokáže zpracovávat tři instrukce za takt. K tomu se ale přidává jedno větvení za takt, celkem tedy čtyři operace („4-issue“). Na čtyři instrukce za takt je také dimenzován fetch, dodávající instrukce do dekodérů. Zpracování je stylem out-of-order a dispatch buffer má „okno“ obsahující 76 instrukcí. Pro přímá větvení je buffer separátní.
Výpočetních pipeline či portů, do kterých může dispatch poslat instrukci, je osm: tři ALU, z nichž jedna umí násobení, zbylé dvě jsou méně komplexní. Jedna z nich je používána pro nepřímé větvení, zatímco přímé větvení jde opět samostatně do separátní, osmé pipeline. Jádro má dvě pipeline/jednotky pro práci s pamětí – jedna je vyhrazená pro load, jedna pro store. Falkor tedy dokáže za takt uskutečnit jedno 128bitové čtení a jeden 128bitový zápis do paměti/cache. Zbylé dvě pipeline patří FPU (pod což spadají také 128bitové SIMD instrukce Neon). Počet stupňů v pipeline se liší podle instrukcí – násobení v ALU a load/store potřebují 13 stupňů, NEON a FPU 15, jednoduché operace ALU jen 11 a pipeline pro přímé větvení má stupňů jen 10. Vidět to můžete názorně na následujícím slajdu.
 Schéma jednotlivých pipeline jádra Falkor, ukazující počet stupňů (řádky v diagramu)
Schéma jednotlivých pipeline jádra Falkor, ukazující počet stupňů (řádky v diagramu)Write-through L1 cache a L0 s nulovou latencí
Mezipaměti L1 cache jsou poměrně specifické. Datová L1 cache má 32 KB s osmicestnou asociativitou a latencí 3 cykly. Čím se liší od dalších současných jader, je to, že je použita politika „write-through“. To znamená, že všechny zápisy do L1 cache jsou vždy současně zapisovány i do L2 cache, místo aby byla L1 cache nezávislá (politika „write-back“). Toto zjednodušení bylo jedním z typických rysů architektury Bulldozer (a jejích dětí) u AMD a také jednou z jejích slabin. Zda bude výkonnostním omezením i u Falkoru, zatím netušíme.
Zvláštní je i instrukční L1 cache. Ta má totiž ve skutečnosti dvě úrovně. Hlavní L1 cache pro kód má 64 KB opět s osmicestnou asociativitou a latencí 4 cykly. Kromě tohoto bloku má ale Falkor ještě třícestně asociativní 24KB „L0 cache“. Tento blok je jakousi zkratkou do L1: L0 má latenci 0 cyklů a přístup k jejímu obsahu je tedy možný bez zpoždění, pokud se v ní potřebná část kódu najde. Tato L0 cache není „micro-OP cache“, jelikož neobsahuje dekódované instrukce, jsou v ní ukládány instrukce předtím, než projdou dekodérem. Pro software vypadá transparentně jako součást L1 cache, programy tedy budou obojí detekovat dohromady jako 88KB L1 cache.
 Serverová deska s ARM procesorem Qualcomm Centriq 2400, CPU se osazuje do socketu LGA
Serverová deska s ARM procesorem Qualcomm Centriq 2400, CPU se osazuje do socketu LGAIPC spíše jako Cortexy
Podle tohoto popisu vypadá Falkor o něco silnější než typické „malé jádro“ (Atom Silvermont, AMD Jaguar), nicméně také ne o moc „širší“, než jsou současné top jádra ARM Cortex (A72, A73, A75). Nepůjde tedy asi o jádro se špičkovým IPC atakujícím architektury Haswell/Skylake nebo Zen, výkon na 1 MHz bude pravděpodobně někde níž. Kam přesně se Falkor posadí v pomyslném prostoru mezi Cortexy a těmito „velkými jádry“ architektury x86, to ale bude záviset na tom, jak dobře se Qualcommu podaří architekturu vyladit a potenciál 4-issue návrhu s třemi ALU vytěžit. Pro srovnání – jak Zen, tak Skylake mají čtyři ALU a také vyšší počet FPU/SIMD jednotek.
Podle Qualcommu má procesor Centriq běžet na napájecím napětí zhruba 1,0 V a cílem jsou frekvence „nad 2,0 GHz“. Výkon na jedno jádro tedy nebude úplně nízký, ale pravděpodobně nijak dramaticky vyšší, než jsme zatím viděli u různých mobilních ARMů (s výjimkou velmi širokých jader Apple). Jaké má být TDP, nevíme, ale při 48 jádrech je evidentní, že na jedno jádro připadá méně energie a s tím i výkonnostního potenciálu, než u procesorů Xeon nebo Epyc.
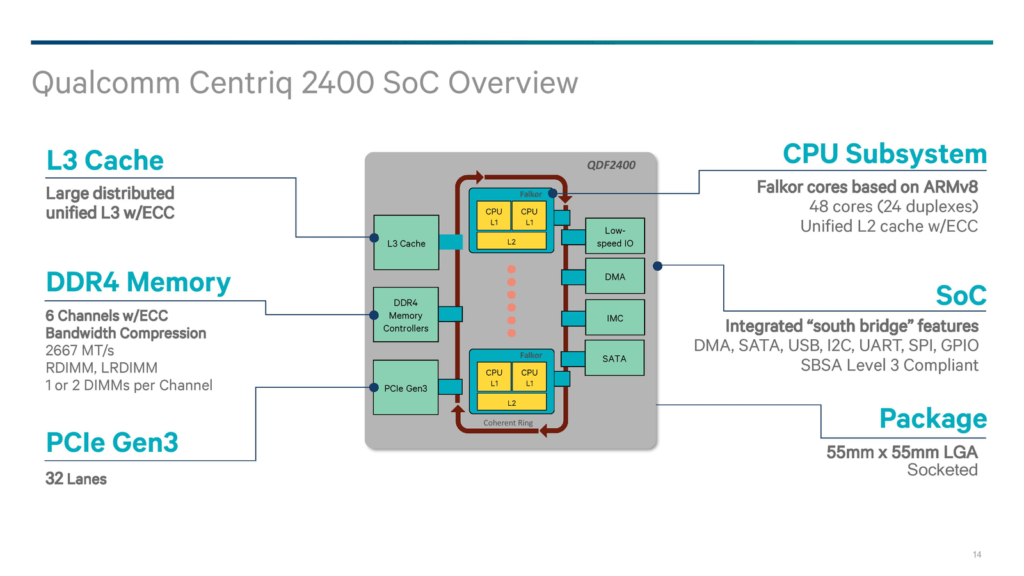 Qualcomm Centriq 2400, schéma čipu
Qualcomm Centriq 2400, schéma čipuBezpečnost a serverové speciality
Pro použití v serverech má architektura některé další specifické vlastnosti. Podporuje například bezpečnostní systém ARM Trustzone (trusted execution) a také Secure Boot. Primární zavaděč je přímo v ROM procesoru a při spuštění systému je každá další softwarová vrstva ověřována proti certifikátům od Qualcommu, výrobce serveru nebo uživatele, aby se zabránilo spuštění neautorizovaného (a tedy potenciálně škodlivého) kódu.
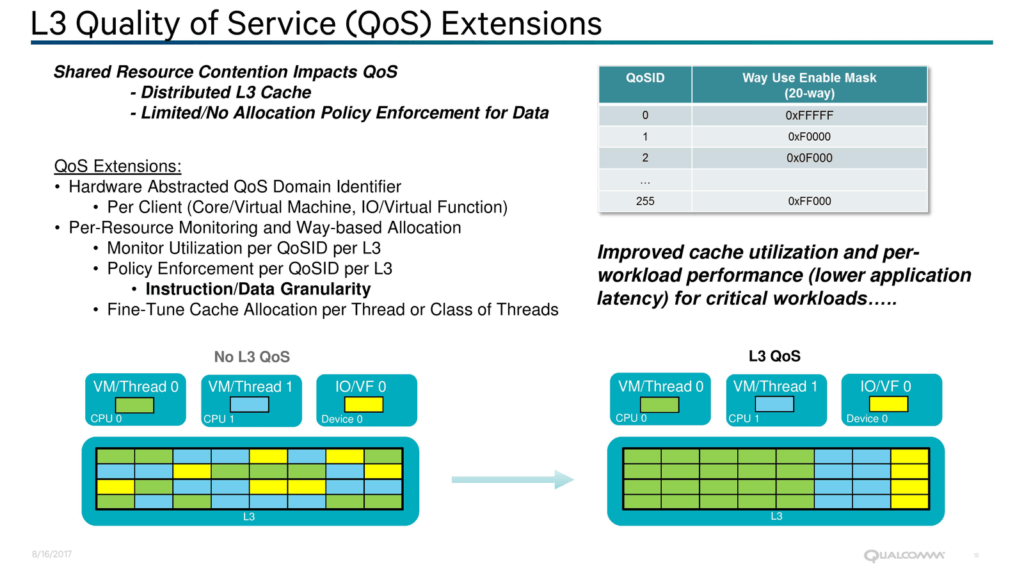
Falkor má mít také instrukční sadu rozšířenou o instrukce pro akceleraci kryptografických algoritmů AES, SHA-1 a SHA-256. Pro servery bude také důležitá implementace „QoS“ v L3 cache. Procesor u ní bude hlídat přidělování zdrojů tak, aby například jedno jádro nemohlo spotřebovávat většinu prostředků a brzdit tak další. Přidělování L3 cache bude monitorováno a řízeno, přičemž politika QoS bude nastavitelná. Samotná L3 cache asi bude segmentována po jádrech a celková kapacita by měla škálovat podle počtu jader. Také L3 cache je chráněna ECC, což je ale u nemobilních CPU standard.

Hardwarová komprese RAM
Centriq má mít šestikanálové paměti DDR4 s podporou frekvence 2666 MHz (což je na úrovni letos uvedených „metalových“ Xeonů i Epyců) a ECC. Na každý řadič bude možné instalovat dva moduly DIMM, takže maximální kapacita bude stejná jako u Xeonů Skylake-SP, tedy 1,5 TB na CPU při použití 128GB modulů LRDIMM. Konektivita PCI Express bude naopak o něco slabší – Centriq má řadiče pro 32 linek PCIe generace 3.0. Přímo na čipu budou integrovány i řadiče SATA, USB a další (UART, I2C, GPIO). Všechna tato rozhraní, paměťové řadiče a jádra s L3 cache budou komunikovat interně vyvinutou propojovací logikou „QSB“ (Qualcomm System Bus). Její topologie není úplně jasná. Slajdy mluví o prstencové sběrnici, celek by mohl být komplikovanější.
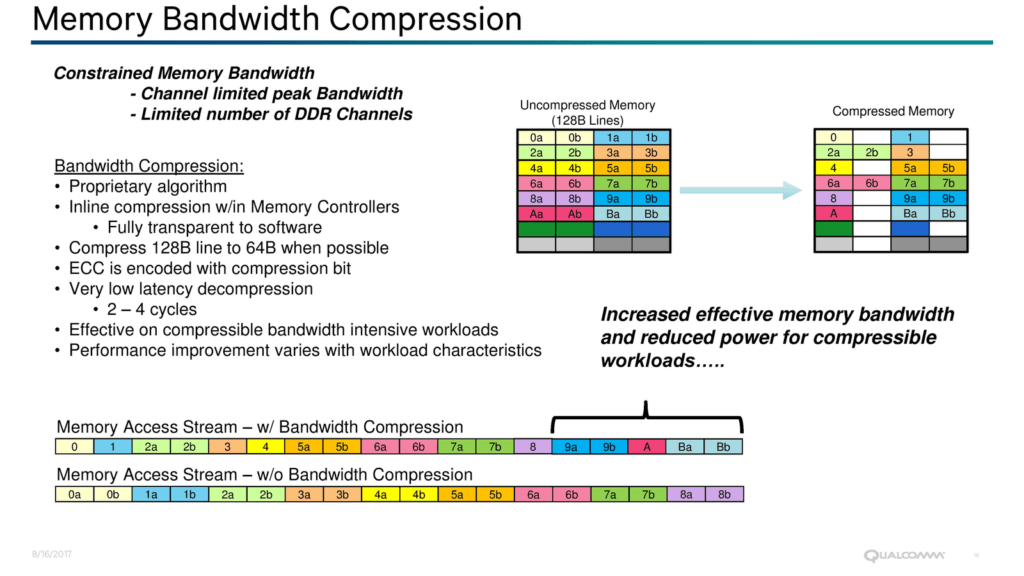 Technologie komprese RAM v procesorech Qualcomm Centriq 2400
Technologie komprese RAM v procesorech Qualcomm Centriq 2400Proti konkurenci bude Centriq mít jednu zajímavou odlišnost. Paměťový řadič bude hardwarově komprimovat data s cílem dostat co nejvíce z dostupné propustnosti a kapacity. Má to fungovat tak, že řadič bude při ukládání dat do paměti z cache CPU zkoušet každý 128bajtový řádek komprimovat do 64 bajtů, pochopitelně bezeztrátově a s kontrolním ECC. Pokud se toto podaří (v závislosti na komprimovatelnosti daných dat), pak je do RAM zapsána tato komprimovaná verze s příslušným příznakem. Při opětovném načtení dat do CPU řadič provede automaticky dekompresi (ta má přidat 2–4 cykly k latenci RAM), totéž pak při uložení z paměti na trvalé úložiště či odeslání po síti či I/O. Vše by mělo fungovat transparentně, takže programy snad nemusí být nijak změněny, aby dokázaly případné výkonnostní přínosy zužitkovat.








































