
F@H využívá tzv. distribuovaných výpočtů, tedy principu, kdy řídící systém/server rozděluje jednotlivé úkoly mezi klientské systémy (počítače) a jakýkoli uživatel připojený k internetu si může nainstalovat příslušný software a poskytnout výpočetní výkon svého stroje pro vědecké účely.
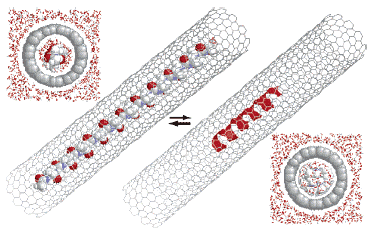
Konformace peptidů v omezeném prosoru (nanotubes)
Folding klient pro nová GPU stále nikde
Za projektem F@H stojí Stanfordská univerzita, za kterou v tomto projektu veřejně vystupuje především Michael Clair Houston (známý spíše jako Mike Houston). Projekt upoutal pozornost obzvlášť v minulém roce, kdy Standfordská univerzita ve spolupráci s ATI vyvinula tzv. GP-GPU klienta, který byl schopen příslušné výpočty provádět na aritmeticko-logických jednotkách (laicky „pixel shaderech“) grafického čipu R580 (Radeon X1900, později i na dalších), díky čemuž vzrostla rychlost zpracování příslušných výpočtů 20–40× (oproti CPU a v závislosti na sestavě).

ATI FireStream se až na velikost paměti (1 GB vs. 256 či 512 MB) fyzicky nijak neliší od Radeonu X1900 XT, jádro R580 je však využito k univerzálnějším výpočtům. Zdroj: GPUreview.com
V zimě situace poněkud utichla a jediná zpráva, kterou jsme se dozvěděli, bylo několik detailů od M. Houstona na diskuzním fóru folding-compunity.org, kde uvedl, že (tehdy nový) čip R600 je až 2,2× rychlejší, než R580, ale softwarové rozhraní nedovoluje využít jeho plného potenciálu, vinou čehož je výsledný výkon výrazně nižší, než jaký by měl být.

Nebiologický polymer (dimer)
Přesto, že nové DX10 akcelerátory by pro účely GP-GPU měly být teoreticky mnohem vhodnější, než čipy minulé generace, tak verze F@H klienta kompatibilní s Radeony HD a GeForce 8 nepřišla. Ačkoli je tento stav politováníhodný a současné high-endové systémy vybavené dvěma čipy R600 nebo G80 by byly schopny provádět výpočty zhruba 100× rychleji, než tomu bylo minulý rok na nejvýkonnějších procesorech, nejde o nechuť ze strany Stanfordské univerzity, ale shodu několika nepříjemných okolností a absenci univerzálního rozhraní, přes které by aplikace mohla ke grafickému jádru (či grafickým jádrům) přistupovat.
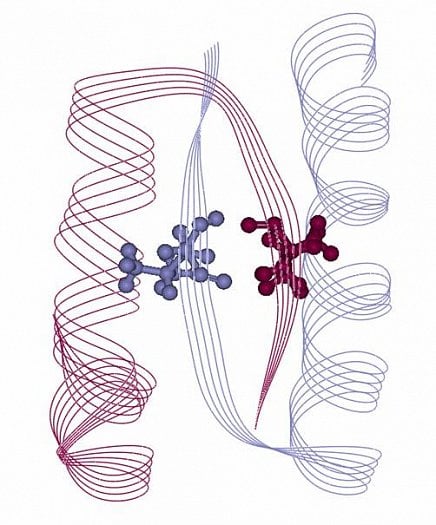
Struktura p53 dimeru s vyznačeným Leu330 mutantem
Na prahu zániku?
Mezi ony nešťastné okolnosti můžeme řadit např. odkup společnosti PeakStream 5. června letošního roku provozovatelem známého internetového portálu Google. PeakStream byla společnost, která se specializovala na tzv. StreamComputing a s ATI spolupracovala na vývoji projektu FireStream – akcelerovaných GP-GPU výpočtech pomocí systémů postavených na čipu R580 (po akvizici AMD známých jako AMD StreamProcessor). Situaci dále zkomplikoval odchod jednoho z klíčových vývojářů ze Stanfordské univerzity.
Ve světle nových informací, o které se na diskusním fóru serveru Beyond3D.com podělil samotný Mike Houston, celá záležitost nevypadá tak katastroficky, jak by se mohlo na první pohled zdát:
We are actually actively working on this. We just don't like to get hopes up too high, so we don't say much unless we have progress.
We have only a few things working reliably on R5XX and that is what is in the wild. We started a new push to get more science cores up, but ran into issues on all hardware. We have stripped the code down to a test harness for easier testing. We have found multiple issues. Some are related to FXC, the Microsoft DX compiler, and some are related to driver compiler wonkiness and other driver related corner cases. We are doing are best to get through things, but as you can see it's a long process. I can tell you that ATI boards and Nvidia boards for the newer code paths produce different results from each other, and different from reference.
The main goal is to get the GB path which as been working great for the FAH guys on the PS3 ported across and working on the GPU. It's more complex than what is currently shipping.
It would be great if there was an industry standard. There isn't so we use Brook for FAH. However, we can target CTM with Brook since ATI/AMD was nice enough to work with us on a CTM backend. CUDA is a more difficult matter. If CUDA ran on multiple vendors as well as multi-core, it would be more attractive for development. Brook is not perfect either, but we have had success in the past and at least the basic stuff runs on all vendors, including painfully slowly on Intel IGP chips. (No, we will not release a client for Intel IGPs!).

Nvidia si razí cestu hodně sama – přístup s vyšším jazykem CUDA a kompletními řešeními Tesla zatím nepřijali zdaleka všichni vývojáři
I should also add that it's just been recently when we have had simple enough tests to hand off to Nvidia and say WTF? We tried this in the past, but it was with the full client, which is massive, and we weren't able to get very far. With ATI, we got things working there, so it was a matter of making sure things didn't break and getting ATI to tune their compiler for performance a little more. There is nothing that is vendor specific, but it's hard to start with a large code base and trace through multiple levels of bugs.
One vendor has been easier to deal with than the other currently. Once we can get through making sure it's not fxc or Brook, we will reengage with Nvidia. To be fair, our success with working with ATI/AMD is likely because I knew people there well and was able to bypass a lot of red tape and also get people with influence behind the project. AMD has spent a lot of engineer time on helping with FAH and Brook. At Nvidia, it's hard to wrestle people interested in GPGPU away from wanting everything in CUDA. There is obvious interest at Nvidia in GPGPU since they have done CUDA, teach courses about CUDA, and have some molecular dynamics work with the NAMD guys. It's just getting support for DX9 currently or any support for Brook that is the problem.
Pokud vám angličtina není tak blízká, abyste si z výše uvedených odstavců dokázali vytvořit obrázek o celé situaci, nabízím stručnější shrnutí v českém jazyce:
CTM univerzální, CUDA specializovaná
Na podpoře pro nové čipy se stále pracuje, ale Stanford nechtěl zveřejňovat žádné informace, dokud nebude dosaženo určitého pokroku, aby v uživatelích nevyvolávali plané naděje. Houston uvádí, že na každém typu hardwaru (ATI/Nvidia) narazili na problémy – některé souvisejí s FXC (DX kompilátor Microsoftu), jiné s kompilátorem ovladače, případně se samotným ovladačem vůbec. Ačkoli se věci začínají ubírat lepším směrem, stále zbývá k finální verzi klienta ještě dlouhá cesta. Zatím, kromě jiného, podávají karty ATI i Nvidie odlišné výsledky a ani jedny navíc neodpovídají těm referenčním. Současným cílem je přizpůsobit „GB path“ (odzkoušená verze pro PS3) pro fungování na GPU.
Predikce četností konformace pro jednodušší bílkoviny
Houston s politování konstatuje, že by vše bylo nesrovnatelně snazší, kdyby existovalo nějaké standardizované či univerzální rozhraní (poznámka autora: jakási obdoba Direct3D či OpenGL pro GP-GPU). To bohužel k dispozici není, a proto je využíváno rozhraní Brook (extenze programovacího jazyka C Stanfordské univerzity). Díky spolupráci s ATI/AMD je možné přes Brook přistupovat k CTM (Close to Metal, rozhraní ATI/AMD pro GP-GPU). S rozhraním Nvidie CUDA je situace trochu složitější – Houston vidí největší problém v nedostatečné univerzálnosti tohoto rozhraní (kompatibilita výhradně s hardwarem Nvidie) a absenci podpory pro vícečipové systémy.
Brook též není dokonalý, ale po dobrých zkušenostech z předchozího projektu a alespoň základní funkčnosti na hardwaru všech výrobců, se jeví jako lepší alternativa. Kompatibilita sahá údajně až k integrovaným akcelerátorům Intelu, pro které ovšem (vinou extrémně nízké rychlosti) klient vyvíjen nebude.

Výpočty trvající 100 let už za rok
V okamžiku, kdy budou vyřešeny problémy s rozhraním, se Stanford hodlá znovu obrátit na Nvidii. Zároveň dodává, že úspěšnou spolupráci s ATI/AMD považuje za pravděpodobnou díky dobrým vztahům pramenících z předchozí spolupráce na F@H a Brook. Největší komplikace při spolupráci s Nvidií Houston vidí ve výhradní podpoře pro CUDA – z jiných rozhraní vývojáři Nvidie příliš nadšení nejsou.
Přestože není reálné očekávat plně funkčního GP-GPU klienta pro současné DX10 čipy v řádech týdnů a dokonce není nepravděpodobné, že bychom se ho mohli dočkat až po vydání další (půl)generace grafických karet (DX10.1+), bude hotové univerzální rozhraní znamenat snazší uzpůsobení i pro další produkty, čímž by se současný skluz mohl velmi rychle dohnat. Nezbývá než popřát M.Houstonovi a F@H týmu hodně štěstí – stonásobné zrychlení výzkumu v praxi může znamenat, že k poznatkům, ke kterým bychom se za použití loňských prostředků dostali za 100 let, se můžeme dopracovat již během příštího roku...








































