
Před rokem Google, respektive jeho tým DeepMind porazil nejlepšího hráče ve hře Go. Umělá inteligence AlphaGo se učila na 30 milionech tahů zahranými člověkem. Později firma uvedla ještě lepší verzi AlphaGo Zero, která se začala učit hraním sama proti sobě. Posledním vývojovým stupněm je software nazvaný AlphaZero. Toho letos DeepMind učil hrát nejen Go, ale také dvě varianty šachů (klasické a japonské Shogi). A ve všech hrách je bezkonkurenční.
Firma založila tři instance AlphaZero, pro každou hru zvlášť. Proces probíhal v 700 000 krocích, při kterých 5000 procesorů TPU první generace generovalo hry a 64 TPU druhé generace trénovalo neuronovou síť. AlphaZero na začátku znalo jen pravidla her, zkušenosti sbíralo až hraním proti sobě.
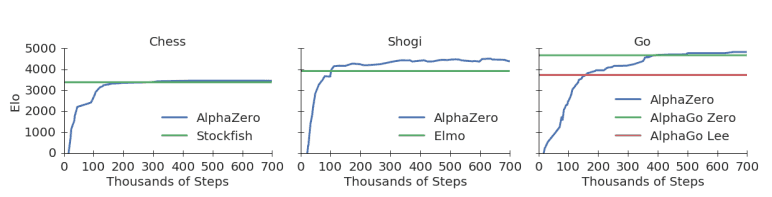 Kdy začalo AlphaZero vyhrávat?
Kdy začalo AlphaZero vyhrávat?Již po 300 000 krocích (4 hodinách reálného času) dokázalo AlphaZero poprvé porazit Stockfish, aktuálně nejlepší šachový program. V Shogi poprvé porazil rovněž nejlepší software Elmo po 110 000 krocích (necelých dvou hodinách). Původní AlphaGo porazil po 165 000 krocích (8 hodinách).

Plně vytrénované AlphaZero pak nastoupilo ve 100 hrách proti zmíněným nejlepším softwarům v oboru. V šachu nad Stockfishem vyhrál 28×, remizoval 72× a ani jednou neprohrál. Mimochodem, když AlphaZero hrálo s bílými figurkami (a tedy začínalo), pravděpodobnost výhry byla osmkrát vyšší (25 výher s bílými, 3 s černými).
V Shogi proti Elmu vyhrál 90×, 2× remizoval a 8× prohrál. Proti AlphaGo Zero se třemi dny tréninku měl 60 výher a 40 proher.
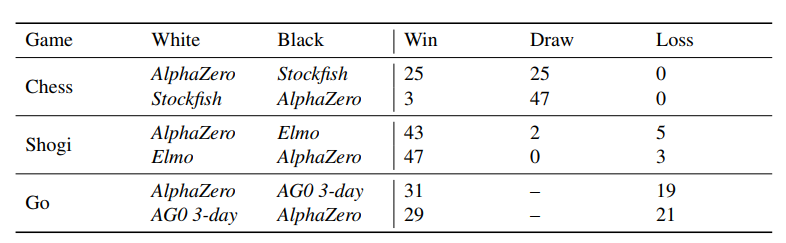 Bilance AlphaZero po 100 hrách
Bilance AlphaZero po 100 hrách







































