





Jsou to již tři roky, co se na půdě Evropské unie připravuje směrnice reformující autorské právo. Text se od prvotní publikace Evropskou komisí změnil, v základu ale zůstává stejný. Má zajistit spravedlivější odměny autorům nebo držitelům práv a ve velké míře také nastoluje nová pravidla při boji s pirátstvím. Všichni v oboru se shodnou, že reforma byla potřeba. Na čem už se ale neshodnou, je její konkrétní podoba.
Reforma s sebou totiž přináší dva kontroverzní body, články 11 a 13, které mohou změnit web (a potažmo celý internet) tak, jak jej známe. Současná podoba návrhu je v angličtině dostupná na europa.eu. Do češtiny oba články přeložila Unie vydavatelů. Náš rozbor najdete v reportu Jak chce EU reformovat autorské právo? Zde jen ve stručnosti připomenu hlavní fakta.
Článek 11
Článek 11 říká, že provozovatelé velkých online služeb, které nějak nakládají s autorským obsahem připravovaným vydavateli tiskových publikací, musí za využití těchto děl vydavatele spravedlivě odměňovat. Bezplatně / bez dovolení smí pouze odkazovat nebo z textů vybrat jednotlivá slova či velmi krátké výňatky. Bez zákonem stanovených odměn ale budou vědecké či výzkumné publikace nebo soukromé weby, které nepodléhají vydavatelům (menší média, blogy apod.)
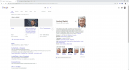
 Snippet v akci. Google vzal výňatek našeho nadpisu, těla článku i obrázek
Snippet v akci. Google vzal výňatek našeho nadpisu, těla článku i obrázekReálně jde o to, že Google, Facebook atd. nebudou moci odkazovat na zpravodajské weby tak jako doposud. Google ve vyhledávači či Facebook na zdi zobrazují tzv. snippety. Ty obsahují nadpis článku, úryvek text, odkaz a titulní obrázek. Vydavatelům vadí, že tito velikáni nakládají s jejich obsahem, ale nedostávají za to žádnou odměnu, i když Google a Facebook na jejich obsahu (nepřímo) vydělávají.
Článek 13
Článek 13 rovněž postihne hlavně Google (YouTube) a Facebook, ale obecně se dotkne všech větších služeb, které slouží ke sdílení obsahu. Slovo velký směrnice definuje tak, že služba má roční obrat přes 10 milionů eur a návštěvnost přes 5 milionů unikátních uživatelů měsíčně. Pod to by teoreticky spadlo třeba české Ulož.to.
Ve zkratce budou provozovatelé těchto služeb zodpovědní za obsah, který u nich ukládají samotní uživatelé. Provozovatelé si budou muset zajistit potřebná práva pro nakládání s autorsky chráněným obsahem nebo vyvinout velké úsilí k tomu je získat. (Návrh ale zmiňuje, že provozovatelé nemusí aktivně monitorovat, co všechno se k nim nahrává.) K tomu jim zůstane i stávající povinnost mazat obsah, který jim majitelé práv nahlásí. Musí ale také preventivně zajistit, aby nešel nahrávat ani do budoucna. Výjimku mají díla, která jiná díla citují, recenzují, dělají z nich parodie apod., taková provozovatelé mazat nebudou.
TIP: Wikipedia protestuje proti reformě autorského zákona
Výjimku také mají různé neziskovky (encyklopedie, vědecké a vzdělávací instituce), služby pro sdílení zdrojových kódů (například GitHub) nebo osobní cloudy (Dropbox, OneDrive apod.). Ty licence k dílům získávat nemusí.
Tohle může dopadnout hodně špatně
Nepřekvapí, že oba články rozdělily společnost. Velcí vydavatelé je obhajují, velké online služby zase kritizují. Zvláštním případem je u nás Seznam, který je zároveň velkým vydavatelem i vyhledávačem/portálem, který nakládá s obsahem jiných. I on se ale otevřeně staví proti návrhu.
Coby autor bych samozřejmě chtěl spravedlivější odměny a méně pirátství, ale zároveň se na věc dívám s nadhledem. A myslím, že stávající návrh může spíš škodit. Je napsaný velmi vágně, takže v mnoha ohledem lze vyložit různě. Lze předpokládat, že se různými způsoby také implementuje do zákonů v členských zemích. (Pokud tedy směrnice projde.) Firma působící na více trzích se pak bude muset řídit zákony, které mohou jít proti sobě.
To by ale nebylo nejhorší, megafirma holt musí s úředním šimlem počítat. Co mi vadí víc, je to, že články 11 a 13 nepotřebujeme. Současně nastavené právo a pravidla si umí s příčinami poradit nebo je řešit stejně (ne)efektivně jako zmíněné články.
 Návštěvnost Cnews.cz ze 49 % generují vyhledávače
Návštěvnost Cnews.cz ze 49 % generují vyhledávačeNapříklad není pravda, že by zpravodajské weby nebyly odměňovány vyhledávači nebo sociálními sítěmi. Možná z nich nemají přímé příjmy, ale generují jim návštěvnost, kterou už sami zúročí na reklamách. Návštěvnost zavedených webů může klidně z většiny tvořit právě přístup k vyhledávačů. Na Cnews.cz přichází 49 % návštěv právě z Googlu, Seznamu a spol. Přímé návštěvy zadáním adresy do prohlížeče tvoří asi 27 %. Zbytek si rozdělují odkazy odjinud, sociální sítě, e-maily atd.
S Googlem i Facebookem se dá bojovat
Pokud médiím tolik vadí, že na ně Google a Facebook nepřiměřeně odkazují a vydělávají na tom, mohou s tím bojovat už dnes. Weby mají na serverech uložené soubory robots.txt, kde mohou nastavit pravidla přístupu robotům, kteří pro vyhledávače a další služby web procházejí. Klidně mohou definovat, aby jim Google ani Facebook na webu vůbec nešmejdili. Když už nějaký zákon, tak takový, podle něhož by se všechny online služby procházející cizí stránky musely těmito pravidly skutečně závazně řídit.
Média ale Google neblokují, i když mohou. Naopak pro něj stránky ještě optimalizují. Najímají si SEO experty, kteří se jim snaží weby po technické i obsahové stránce upravit tak, aby se ve výsledcích objevovaly nahoře. Sami přitom mohou v HTML kódu definovat, co se v takovém snippetu (úryvku) na Googlu nebo Facebooku objeví. Média dokonce sama provozují RSS kanály, do kterých posílají odkazy s výňatky textu, obrázky a titulky článků. Uživatelé pak díky tomu mohou v jedné aplikaci sledovat více zdrojů současně. Agregátory typu Feedly nebo český PrávěDnes.cz pak nedělají nic jiného, než že díky RSS připravují přehled zpráv.
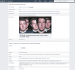
 Facebook si v robots.txt drží vyhledávače od těla
Facebook si v robots.txt drží vyhledávače od tělaMédiím tedy nejde o kontrolu přístupu k jejich webům, to si jejich webmasteři mohou zařídit sami. Chtějí, aby na ně Google a spol. odkazovali, ale zároveň i platili. Přijde mi nepředstavitelné, aby Google musel s každým zvlášť podepisovat smlouvu. To zřejmě přišlo nepředstavitelné i předkladatelům směrnice, kteří vyloučili malá média a blogy bez vydavatelství, kterých bude násobně více. Bez lobbistů nejsou koláče, holoto! Přitom takový odborný blog jednoho nadšence může mít mnohem větší informační hodnotu než reklamou protkaný bulvár, co jen láká na clickbaitové titulky.
TIP: Místo zpráv jen prázdné obdélníky. Google se připravuje na cenzuru v EU
Mimochodem: V Německu si v minulosti vydavatelé také dupli a chtěli po Googlu „daň z odkazu“. Google na ně přestal odkazovat úplně, vydavatelé stáhli ocas a zase se s firmou dohodli.
Půjde to bez filtru?
Nutnost aktivní spolupráce je pro mě nepředstavitelná i v případě článku 13. Že je na YouTubu nebo Ulož.to velká spousta pirátského obsahu, o tom není třeba diskutovat. Google se alespoň snaží upload filtrovat, takže filmy, seriály a další obsah partnerských studií dokáže potlačit ještě před zveřejněním. Systém Content ID ale budoval několik let, musel jej vyjít na desítky nebo stovky milionů dolarů a stejně nefunguje dokonale. Jak by tohle mohl nasadit někdo menší?
Jak se pozná ono v návrhu zmíněné nejlepší možné úsilí? Tohle návrh nijak neřeší a teoreticky to umožní komukoliv žalovat YouTube, že neochránil zrovna jeho video. A nejde jen o video, stejně budou chráněny zvuky, texty, obrázky… V návrhu stojí, že nepřikazuje aktivně monitorovat nahrávaný obsah, ale jak jinak kontrolovat, že je právně v pořádku, než jeho analýzou?
Jak má vůbec provozovatel podobného úložiště posuzovat, zdali uploader má, či nemá práva ke sdílení? Asi bude obvyklé, že studia nebudou chtít, aby jejich filmy sdílel kdokoliv. Mohou ale přidělovat individuální práva a YouTube by musel nastavit další podmínku, co povolovat a co ne. Kolik různé byrokracie bude muset snést uploader a kolik YouTube a spol.?
Jak potlačit pirátství?
Současný stav, kdy stačí dílo prostě nahlásit, a provozovatel sítě jej smaže, není dostatečný. S tím souhlasím. Článek 13 ale reálný problém také neřeší a spíš jej jen umocňuje, protože odpovědnost přenáší na provozovatele místo majitele práv, který si dnes sám musí hlídat, co mu kde „ukradli“.
V ideální společnosti by mohla fungovat nezávislá databáze, do které by majitelé práv nahrávali svá díla, z nich by se vytvořily otisky a podle nich by se pak dal obsah na sítích filtrovat. U otisků by mohly být také různé identifikátory popisující, kdo a jak může s dílem nakládat. Jenže v ideální společnosti nežijeme, taková databáze tady chybí a bez ní to fungovat nemůže. Firmy akorát budou jedna po druhé znovu vynalézat kolo a kopírovat ne moc dobře funkční Content ID od YouTubu.

Mnohem jednodušší by bylo, kdyby veškeré nahrávané a veřejně sdílené soubory měly jednoznačně identifikovaného uploadera. Při registraci by se musel prokázat občankou nebo jiným dokladem. Pak už by si rozmyslel, jestli bude na Ulož.to něco nahrávat. Samozřejmě to nevyřeší P2P pirátské sítě, samozřejmě to v některých případech půjde obejít falešnými doklady a samozřejmě by se to muselo nějak sladit s GDPR. Přišlo by mi to ale jako méně komplikované a zároveň účinnější řešení. Než přijímat špatně napsaný zákon, tak raději žádný.
Myslíte si, že články 11 a 13 jsou správné?
PS: V komentáři několikrát opakuji, že Google a Facebook musí nebo nemusí… Návrh tyto firmy konkrétně nezmiňuje, ale všem je jasné, že míří zejména proti nim. Obě dominují webu, byť každá v jiné oblasti. Oběma můžeme vyčítat, že na internet měly výrazný negativní vliv. Zavedly pravidlo, že špičkové služby lze poskytovat zdarma, pokud za ně uživatelé vymění své soukromí. Když už je kvůli něčemu přísně regulovat, tak právě v oblasti nakládání s uživatelskými údaji. Házet na ně zodpovědnost za mediální krizi a pirátství, mi ale přijde přes čáru.











































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU