
Data mining je v kostce řečeno proces získávání určitých informací ze zdrojových dat. Proces, který zajistí, že se tato data převedou do informace užitečné pro lidské osoby. Metoda je moderním programátorům již velmi dobře známa a často se dnes používá. Je zajímavé, že se občas provádí pouze na částech původních dat (z časových, finančních nebo výkonnostních důvodů), ovšem aby tato metoda dokonale fungovala, je přirozeně nutné mít vždy reprezentativní vzorek dat. Neméně důležitou součástí procesu získávání informací z dat je i jejich validace a verifikace.
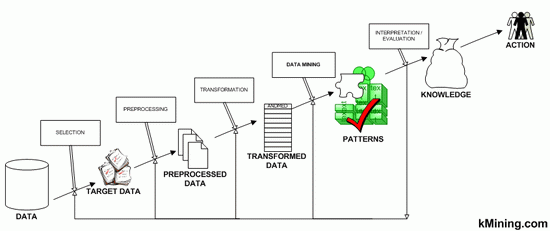 Jednoduchý průběh data miningu. Nejdříve informaci někdo vyrobí. Provede se výběr zdrojových dat, které se nejdříve protřídí podle určitých hledisek a převedou na strukturovaný výstup, se kterým se dále pracuje. Z těchto pracovních dat se podle daných vzorců vypočítá/předpoví výsledek, který je v čitelné formě převeden do lidské řeči. Zdroj: Eason & Son
Jednoduchý průběh data miningu. Nejdříve informaci někdo vyrobí. Provede se výběr zdrojových dat, které se nejdříve protřídí podle určitých hledisek a převedou na strukturovaný výstup, se kterým se dále pracuje. Z těchto pracovních dat se podle daných vzorců vypočítá/předpoví výsledek, který je v čitelné formě převeden do lidské řeči. Zdroj: Eason & Son
Pro data mining se dnes používá prakticky libovolný CPU, ovšem na desktopech jim dnes dominují vícejádrové AMD a Intely. Velmi zajímavou oblastí se pro moderní data mining ukázaly být i výkonné grafické karty, které si v dataminingové sféře vědy, studiích počasí, při zpracování výstupů ze senzorů apod. ujídají stále větší kus podílového koláče. Je to pochopitelné, jsou pro ně díky své univerzální architektuře vhodné (mají z hlediska data miningu i řádově větší výkon) a navíc je najdeme v každém moderním PC. V poslední době vzniklo pro nejrozšířenější grafické čipy dokonce i několik API, která umožňují výkon grafických karet zužitkovat ve vlastních aplikacích, ale obraťme opět pozornost k data miningu. I když by se snad někomu mohlo zdát, že data mining není ideální úloha pro paralelní zpracování, praxe nám opět ukázala, že některé dataminingové programy dosáhly díky použití GPU při zpracování úloh typu OLAP (Online Business Analyticial Processing) skutečně mimořádný výkonnostní růst.
Stručně řešeno, OLAP je technika pro přehledné „zanoření se“ do podskupiny dat, která může být součástí skutečně obrovské databáze. Řekněme například, že někdo chce analyzovat prodeje na základě produktu, umístění obchodu a data prodeje. Tato trojice údajů se dá označit jako „kostka“, jelikož když si každou z těchto proměnných vyneseme (i s pomocnými přímkami) na jednu z os, vytvoří nám dojem prostorové kostky. Vzájemným posouváním jednotlivých hodnot lze pak vyjádřit různé stavy produktu (různě velké kostky). Co ovšem dělat tehdy, pokud je údajů k vizualizaci znatelně více? V praxi se totiž málokdy analyzuje pouze podle 1–3 údajů. Jistě se shodneme, že ani ten nejlepší ředitel marketingu nenakreslí 12rozměrnou kostku… Pochopitelně, obrátit se k metodě OLAP.
Tvůrci moderních OLAP systémů se shodují, že datová komprese je pro ně nesmírně důležitou, jelikož pouze data umístěná kompletně v paměti RAM lze zpracovávat rozumně efektivně. Dle slov Mattiase Krämera, viceprezidenta společnosti Jedox AG (tvůrci OLAP software), je možné zhruba 20 GB zdrojových dat zkomprimovat na rozumné 2 GB, což je hodnota pro moderní systémy více než přijatelná. V rámci svého urychlení OLAP analýz nabízí jejich aplikace Palo 3.1 podporu moderní technologie Nvidia CUDA, díky které lze výpočty přenechat na grafické kartě.
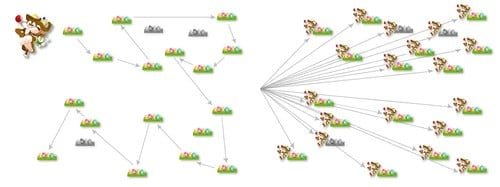 Trochu nefér srovnání CPU a GPU. Jednojádrový procesor musí několik souborů projít postupně. GPU s desítkami či stovkami jader dokáže přistupovat ke všem najednou. Zdroj: Jedox
Trochu nefér srovnání CPU a GPU. Jednojádrový procesor musí několik souborů projít postupně. GPU s desítkami či stovkami jader dokáže přistupovat ke všem najednou. Zdroj: Jedox
Firma přirovnala výhodnost podobného přístupu k následující analogii: představme si, že máme doručit noviny do velkého počtu domácností. Můžeme samozřejmě vzít náklaďák a objet všechny domácnosti ideální cestou, nicméně je tu i druhá možnost – použít armádu kol, kdy každé doručí zásilku do jednoho či více domů. Kola (GPU jádra) jsou sice pomalejší a méně výkonná než náklaďák, na druhou stranu však kombinace gigantického počtu a možnosti použít i neoptimální cestu (čti neztrácet čas s jejím počítáním) dává kolům navrch.
Dalším důvodem pro využití podobného OLAP s GPU je i to, že servery, na kterých aplikace typicky běží, jsou zařízení obvykle spravovaná vzdáleně a bez jakýchkoli nároků na grafiku, takže ta leží ladem a když už ji tam jednou máme, proč ji nevyužít? Tvůrci aplikace se nechali slyšet, že v závislosti na struktuře OLAP byl rychlostní přínos v podobných případech oproti běžnému CPU čtyřiceti až stonásobný.

Vše tedy naznačuje tomu, že kompletní integrace grafiky a procesoru, jak by to rád viděl třeba Intel, se zřejmě v mainstreamu ještě nějaký ten pátek nedočkáme. Samostatné grafické karty jsou stále výkonnější a díky CUDA, OpenCL nebo ATI Stream SDK z nich lze dostat skutečně velmi atraktivní výkony při libovolné dataminingové úloze. I to je důvod, proč například projekty jako Folding@Home (vzdálené výpočty chorob, viz ExtraHardware) začaly podporovat tento přístup a využívají k výpočtům raději GPU namísto CPU.









































