










Už tomu jsou dva roky, co Intel senzačně oznámil, že se hodlá pustit do výroby samostatných GPU, tedy že hodlá své ambice z integrovaných grafik v procesorech rozšířit do vyšších výkonnostních pater. Jejich příchod by měl konečně nastat příští rok a Intel teď začíná odhalovat to, jak budou vypadat. Zatím ještě ne informace o tom, co přinesou hráčům, ale firma představila na konferenci Supercomputing 2019 design HPC výpočetních karet, které na své GPU architektuře Xe (či Xᵉ) hodlá založit.
Ponte Vecchio: první 7nm GPU Intelu, pro superpočítače
První GPU, které takto Intel poodhalil, má kódové označení Ponte Vecchio (podle slavného zastavěného mostu ve Florencii). Ovšem pozor – zřejmě nejde úplně o první generaci grafiky, která má přijít příští rok (2021), ale až o následující, které je plánovaná na rok 2021 a má přijít do exascale superpočítače Aurora. Ten původně měl být postaven na zrušených 10nm Xeonech Phi „Knights Hill“, pak byl odložen a Intel pro něj měl vyvinout jinou architekturu. A to budou 10nm Xeony Sapphire Rapids a právě GPU Ponte Vecchio. Ta ovšem už mají být 7nm (patrně to bude vůbec první 7nm produkt Intelu), kdežto první generace GPU je plánované ještě pro 10nm proces.
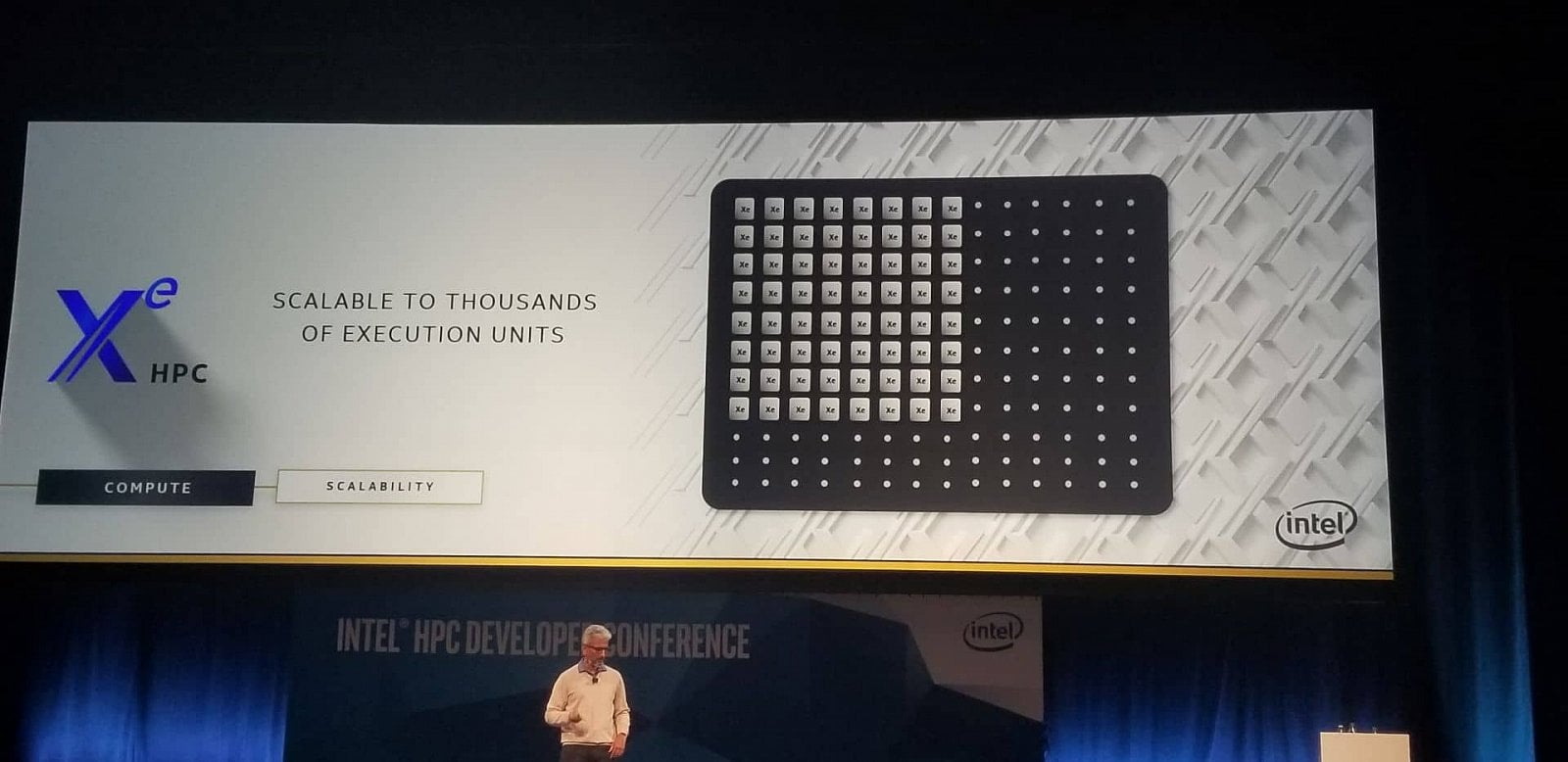
Intel uvádí, že jeho GPU od integrovaných pro nejvýkonnější budou vycházet ze společné architektury Xe, ovšem nebudou zcela stejná, protože Intel ji bude pro jednotlivé segmenty upravovat, byť bude zachovaný společný programovací model. Plánovány jsou tři různé podtypy. Xe „LP“ budou znamenat integrovaná GPU v procesorech s relativně nízkými spotřebami. Nad tím bude Xe HP, které bude výkonnější, budou na něm založená samostatná GPU včetně těch pro spotřebitelské trhy (tedy hráčské grafiky). Ovšem od stejné architektury HP budou odvozená také GPU pro datacentra a pro umělou inteligenci/strojové učení.

Nyní ale Intel nově přidal ještě třetí úroveň označenou HPC, která bude určená pro superpočítače. Od běžného HP se bude lišit, možná by se dalo říct, že Xe HPC bude představovat cosi jako „big iron“ přístup ke GPU, zatímco Xe HP budou asi pořád vcelku běžné karty PCI Express.
FP64, SIMT, SIMD a AI výpočty
Ponte Vecchio pro superpočítač Aurora (ale poté zřejmě i další nasazení) by měl představovat právě onu highendovou „big iron“ verzi HPC. Bude to GPU akcelerátor určený jednak pro klasické vědecké či fyzikální simulace a výpočty, ale také pro nově vzniklý sektor strojového učení (umělé inteligence).

Ponte Vecchio v sobě proto bude kombinovat klasické shaderové jednotky zřejmě vycházející z architektury EU v dnešních integrovaných grafikách, ovšem mělo by už asi jít o architekturu Gen13 (Xe druhé generace) s jednotkami s vysokým výkonem ve výpočtech FP64, v kterých by mohl mít poloviční výkon proti FP32.
Tip: Tiger Lake/Gen12 zásadně inovuje architekturu GPU Intel. Největší změna od roku 2006
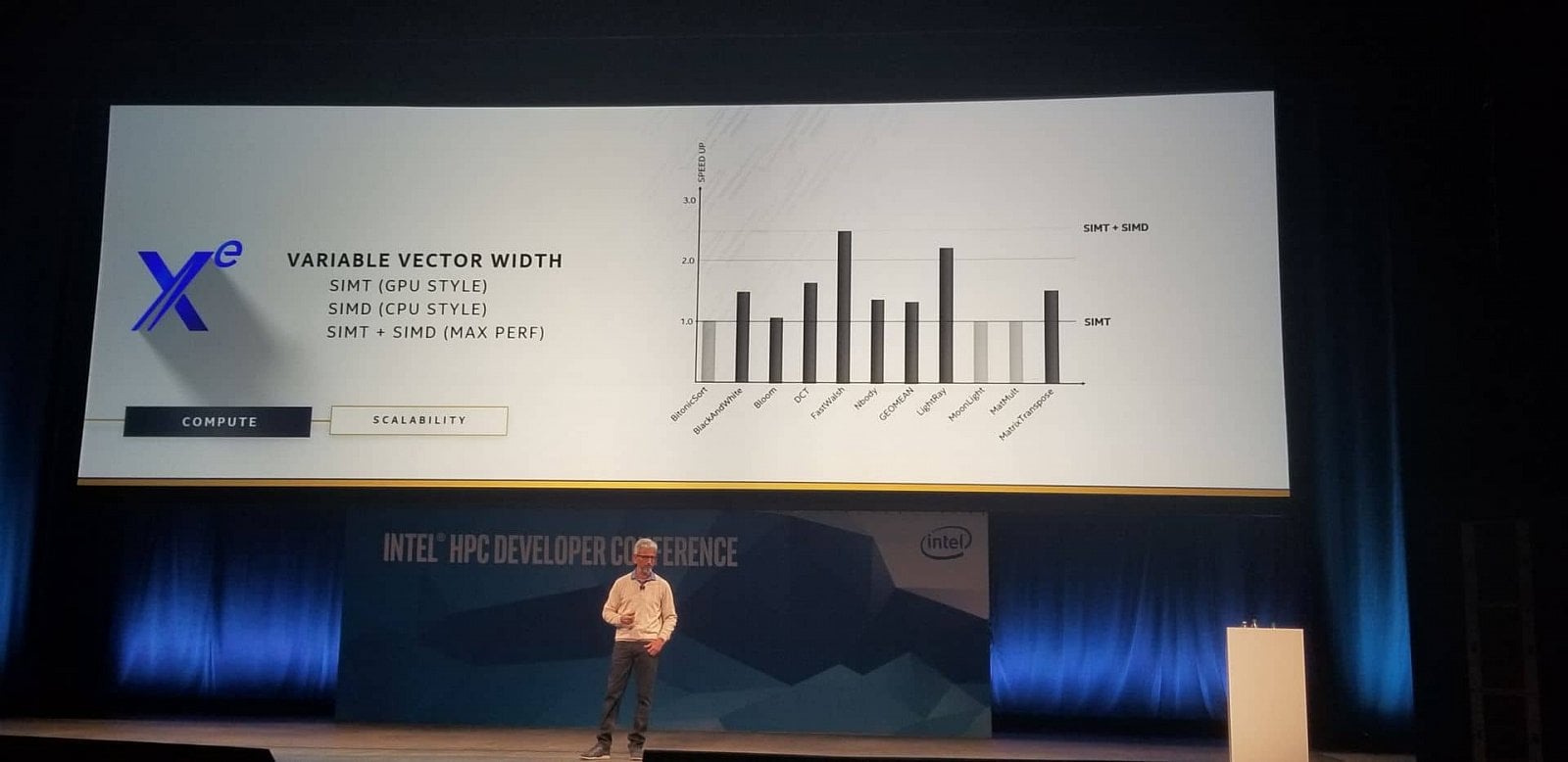
Zajímavé je, že toto GPU bude umět zpracovávat kód různými způsoby. Buď jako je v GPU běžné stylem SIMT, kdy je prováděna jedna operace nad mnoha různými vlákny, ale bude možné i programování podobnější CPU pomocí instrukcí SIMD, kdy místo toho jedno vlákno bude počítat s mnoha hodnotami naráz, přičemž šířka tohoto vektoru se bude dát nastavovat. Pro maximální výkon pak má být použitelná i kombinace obojího.

Zároveň bude Xe HPC obsahovat i „Vektorový Matrix Engine“, který bude ekvivalentem tensor jader v GPU od Nvidie. Půjde a vysoce paralelní jednotky pro maticové násobení používané v operacích neuronových sítí, jenž bude pracovat s datovými typy INT8, FP16 a BFloat16. Třetí složkou architektury pak mají být vysoce výkonné paměti – a to jak klasická „grafická“ paměť RAM, tak i cache, které mají mít obě „ultra vysoké propustnosti“.
Čipletová konstrukce
Velmi zajímavá bude ale fyzická implementace těchto GPU. Nemá jít o tradiční monolitické čipy, ale o čiplety, kde GPU bude složeno z několika kusů křemíku. Tedy trochu jako u Epyců Rome od AMD. Intel použije svoji pokročilou technologii heterogenního 3D kombinování čipletů Foveros a také pouzdření pomocí technologie EMIB, která nahrazuje křemíkové interposery a poprvé byla vyzkoušená u procesorů Kaby Lake-G s integrovanou grafikou Radeon. Čip by například mohl mít 7nm výpočetní vrstvu spojenou s 14nm či 22nm IO vrstvou ve štosu pod ní a pomocí EMIB by mohly být připojené paměti HBM.

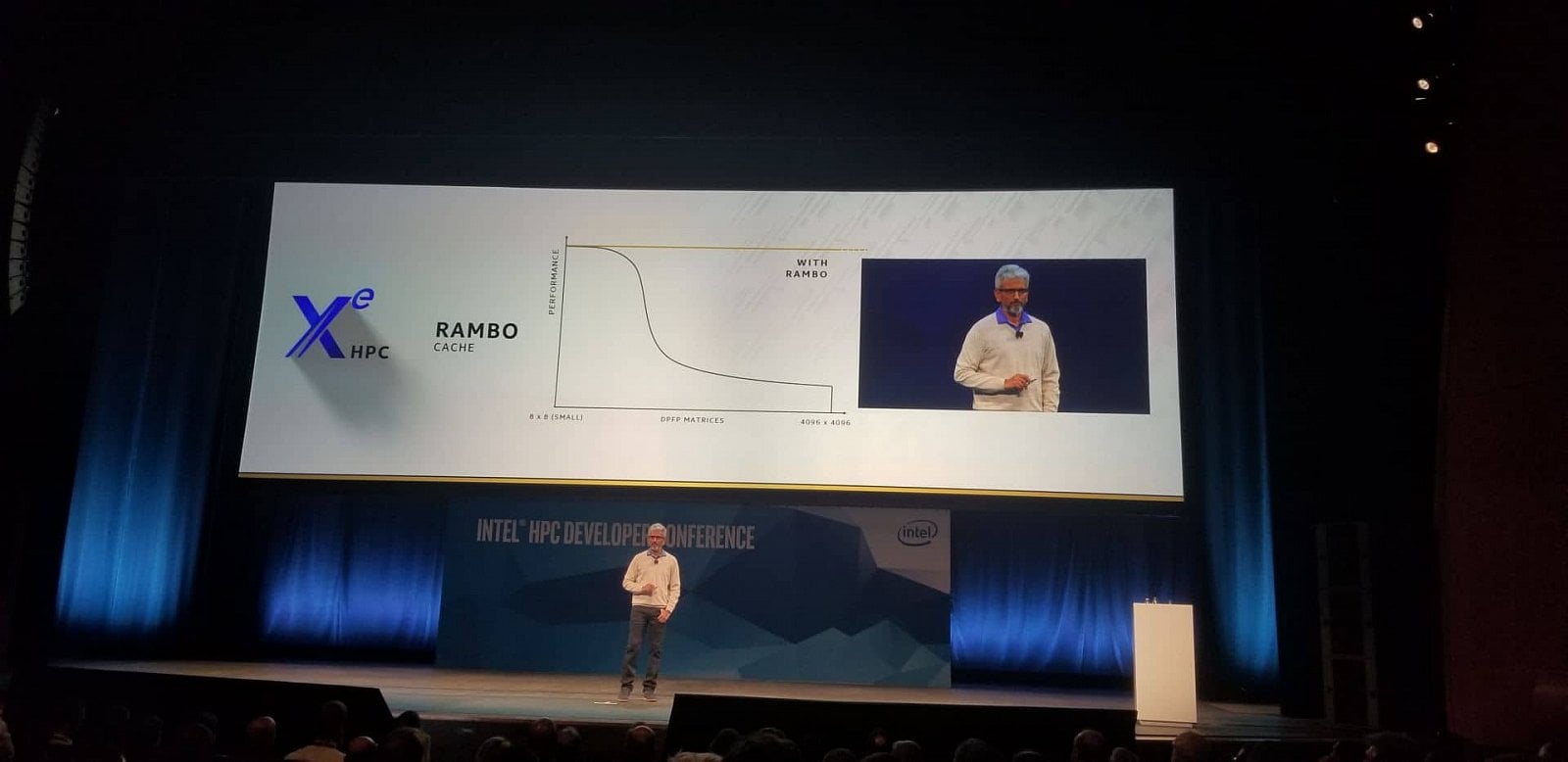
„Rambo Cache“
Respektive, paměti HBM by asi měly být připojené externě k centrálnímu čipu, který by propojoval výpočetní čiplety jako IO die u Epycu. Intel hovoří o velké „Rambo Cache“, která by asi měla být v tomto centrálním čipletu nebo čipletech, které s výpočetními čiplety komunikují propojovací logikou nazvanou XEMF.

K centrálnímu čipletu by HBM asi byla připojená jako externí paměť, zatímco integrovaná Rambo Cache by měla sloužit ke zvýšení výkonu a jako bližší paměťový prostor pro práci GPU čipletů. Je možné, že centrální čiplety XEMF budou ve skutečnosti spojené s výpočetními čiplety v 3D vrstveném stacku a nebude to vypadat vůbec tak, jako na slajdech.

Jak přesně bude Ponte Vecchio stavěné, není řečeno, ale na ilustracích Intelu vypadají jednotlivé součásti GPU jako konvenční pouzdra BGA s kovovým rámečkem, ovšem pak je ještě osm těchto čipů osazeno na jeden substrát do společného pouzdra překrytého rozvaděčem tepla, což je teprve zřejmě výsledné GPU Ponte Vecchio. Opravdu by to tedy mohlo být cosi jako grafický Threadripper či Epyc. Ovšem tyto ilustrace nemusí nutně odpovídat tomu, jak bude vše ve finále implementováno.
Myslím, že může jít spíš o ilustraci a ve skutečnosti by třeba ony jakoby BGA pouzdra mohla být mnohem blíže holým kusům křemíku bez substrátu a kovových rámečků, XEMF čiplet možná bude pod nimi připojený pomocí TSV kontaktů a hned vedle toho budou na substrátu čipy HBM, připojené po okrajích můstky EMIB v substrátu. Pokud by totiž GPU mělo vypadat jako to na ilustracích, byla by například HBM ležela mimo na PCB substrátu jako čip GDDR a navíc ještě hrozně daleko s jakýmsi neidentifikovaným prvkem mezi ní a čipletem XEMF. Toto nevypadá moc reálně.

Propojení s CXL
Podle Intelu budou GPU Ponte Vecchio komunikovat pomocí koherentní propojovací logiky Xᵉ Link, která ovšem má být založená na technologii CXL, kterou vymyslel Intel, ale poté pro ní založil standardizační konzorcium, v kterém sedí minimálně formálně už také třeba ARM nebo AMD. Jde v podstatě o PCI Express 5.0, ale rozšířený o koherentní fungování, takže se jím mohou propojovat procesory a koprocesory s vlastní pamětí tak, aby byla mezi oběma sdílená a synchronizovaná jako v NUMA víceprocesorové sestavě.

Aurora: dva Xeony Sapphire Rapids + šest GPU Ponte Vecchio
Superpočítač Aurora rovněž má být uveden do provozu v roce 2021 a má být složen z uzlů, tvořených deskou s dvěma 10nm Xeony generace Sapphire Rapids (ty mají vyjít také v roce 2021, jde o generaci následující po serverových Ice Lake, jež bude ale asi už používat nový socket). Ty pak budou pomocí CXL obsluhovat šest GPU Ponte Vecchio – oněch pouzder s osmi čipy/čipletovými slepenci uvnitř. Zřejmě i samotná jednotlivá GPU budou propojená pomocí CXL, a to stylem každý s každým.

 Stavba uzlu pro superpočítač Aurora
Stavba uzlu pro superpočítač AuroraOneAPI: jednotné programování CPU, GPU, FPGA i dalších koprocesorů
Důležitá stránka bude jako vždy při používání GPU v roli obecného výpočetního koprocesoru ta softwarová, protože kód nepoběží na čipu přímo jako na procesoru, ale přes vrstvu ovladačů, kompilátoru a programovacích API. Intel přichází pro superpočítač Aurora ale i obecně pro svá GPU a další akcelerátory s technologií OneAPI, což je společné programovací rozhraní, které má umožnit cílit jedním kódem na procesory, GPU, ale i FPGA a ASICy pro umělou inteligenci, tedy celé budoucí portfolio výpočetních čipů Intel.
Intel OneAPIPoněkud to připomíná projekt HSA, který kdysi silně tlačilo AMD, ale mezitím se zájem o něj zdá se vytratil. Intel bude mít díky své velikosti ale o dost větší páky na to, aby ho prosadil a vývojáře do něj natlačil. Mohl by proto přinést potřebný pokrok do heterogenního programování a jeho využití v širší řadě úloh.

















































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU