
Nedá se říct, že by „umělá inteligence“ ve smyslu různých algoritmů založených na trénovaných neuronových sítích před pár lety neexistovala, ale rozhodně kolem ní v IT a hardwarovém průmyslu nebylo takové haló. Dnes je ovšem z „deep learning“ skoro nejdůležitější část marketingových prezentací a zdá se, že například Nvidia na toto použití začíná přeorientovávat svá výpočetní GPU. Právě trénování a běh neuronových sítí se stává velkým trhem pro všemožné akcelerátory, tudíž i GPU. Intel nedávno oznámil, že pro oblast strojového učení vydá speciální procesory Xeon Phi generace Knights Mill, to ale nebude jediné želízko, které v tomto ohni má.
Nyní na listopadové konferenci
Supercomputing 2016 Intel oznámil druhou větev svého programu
akcelerátorů pro strojové učení (nebo možná i třetí,
svou roli by zde totiž mohly sehrát i FPGA Altera). Knights
Mill bude i přes nárůst výkonu ve výpočtech s nižší
přesností pořád mít nevýhodu v tom, že je standardním
univerzálním CPU, takže specializovanější a hloupější
GPU budou proti němu mít vyšší hrubý výkon. Tento problém
Intel nevyřešil tak, že by sám vytvořil velké výpočetní GPU,
ale ještě větší specializací. Pro oblast strojového učení
totiž chystá zcela na míru vyrobené akcelerátory, uzpůsobené
přímo těmto algoritmům. Díky tomu by při stejné spotřebě
mohly být ještě výkonnější, než GPU.
První z této linie „AI čipů“,
které Intel chystá, má kódové označení Lake Crest a měl
by se začít vyrábět v příštím roce – zatím tedy
ještě reálně neexistuje, nicméně přípravy by měly finišovat. Testovací čipy mají být dostupné v H1 2017 a v druhé polovině roku už mají jít finální kusy prvním zákazníkům.
Tento ASIC, akcelerující operace používané při trénování
neuronových sítí, není původně dílem Intelu, jde o plod
akvizice firmy Nervana z letošního léta. Kvůli tomu je Lake
Crest vyráběn na 28nm procesu v nezávislé továrně, ovšem
příští generace se patrně přesunou na proces Intelu. Přes
starší křemíkovou technologii by ale prý čip měl být díky
specializaci efektivnější než konkurence a podávat vyšší
výkon při stejné spotřebě.
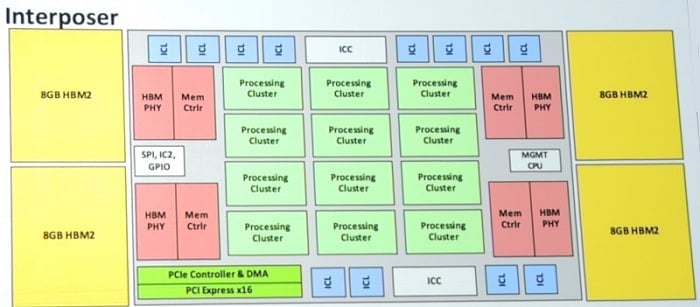
Schéma akcelerátoru Intel (Nervana) Lake Crest (Zdroj: EE Times)
Lake Crest by měl být čipem s velkým
množstvím paralelních jednotek, které sdílejí 32GB paměť HBM2
v 2.5D zapouzdření na interposeru, která celkově dává
propustnost 1 TB/s. Výpočetní jednotky by měly být poměrně
jednoduché, nemají například paměti cache a paměť je
spravována softwarově. Akcelerátor nepočítá s hodnotami
typu floating point, Intel hovoří o aritmetice „flex point“,
ale není úplně jasné, co se tím myslí. V principu bude
akcelerátor zřejmě bližší TPU
od Google, které pracuje s 8bitovými celočíselnými
hodnotami.
Zatímco akcelerátor Lake Crest bude
mít podobu přídavné karty do slotu PCI Express (na první pohled se tedy bude podobat Xeonům Phi v provedení karty), Intel plánuje
také verzi, která by byla integrovaná do procesoru Xeon. Patrně
by šlo o vícečipový modul (socket
LGA 3647 pro platformu Purley používá velmi velké pouzdro,
takže by pro čip navíc i s HBM měl být prostor). Tato
verze má kódové označení Knights Crest a umožní
akcelerátory v serverech více nahustit. Zatím nevíme, zda bude
použita prostá sběrnice PCI Express, nebo nějaké koherentní
linky (QPI), údajně ale má být zjednodušeno programování díky
sdílení pamětí, takže by propojení asi mohlo být
sofistikovanější než u Lake Crest.

Jaký úspěch bude Intel
s akcelerátory Nervana mít, se teprve uvidí. Jejich prosazení
nebude úplně jednoduché, jelikož půjde o specifickou
architekturu a Intel se tedy musí postarat o náležitou
softwarovou a vývojářskou podporu. První generace produktu také ještě vznikly v samostatné Nervaně, takže zatím budou reflektovat spíše její technologické umění a více DNA skutečně pocházející z Intelu se objeví až v následujících generacích.

Nicméně akcelerátor
typu ASIC by měl mít výhodu ve větší efektivitě, což by mu
proti výpočetním GPU mohlo nahrávat. Vzhledem k tomu, že
Intel není jediný, kdo pro tuto oblast specializované čipy
vyvíjí, je možné, že GPU v strojovém učení zase ustoupí
do minoritního postavení, podobně jako je ASICy vytlačily z těžby
kryptoměny BitCoin.
Zdroj: EE
Times










































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU