
V roce 2006 s přelomovými čipy Conroe začal Intel období své historie, kdy velmi agresivně inovoval architekturu procesorů, nová jádra přicházela co dva roky. Ale kvůli opoždění 10nm procesu se tento vývoj poněkud zasekl. Intel si však nedostatek architektonické inovace nečekaně vynahradil jinde – v úsporné linii procesorů Atom. Zdá se totiž, že architektura Goldmont+ v nyní vydaných čipech Gemini Lake je nakonec přesně takovým „tockem“, jaký chybí procesorům Core. Intel nyní vydal v optimalizačním manuálu podrobnější informace k architektuře Goldmont+ a potvrzuje v nich, že se skutečně jedná o výrazně inovované jádro, byť by označení evokovalo jen drobnou evoluci jádra Goldmont z loňského roku, které už samo bylo výrazným vylepšením proti předchozímu Silvermontu a Airmontu. Překvapivě dobrý výkon v některých uniklých benchmarcích nebyl tedy žádná náhoda, Goldmont+ skutečně má na to, aby přinesl vysoký nárůst IPC (neboli výkonu na 1 MHz).
Vypadá skoro jako „velké jádro“
Jádro Goldmont+ je totiž opět „širší“. Zatímco Silvermont (coby první z out-of-order Atomů) byl stavěn na zpracování dvou instrukcí za takt, původní Goldmont byl rozšířen na tři instrukce. Goldmont+ jde ještě dál a z části už jde o architekturu tzv. „4-issue“, tedy zpracovávající čtyři instrukce za takt. Fáze fetch (načítání instrukcí kódu) a decode sice stále chroustají jen tři instrukce za takt, ovšem dále v procesu zpracování již Goldmont+ zvládne víc – finální fáze retire zpracovává čtyři instrukce za takt a čtyři operace zvládají také výpočetní jednotky.
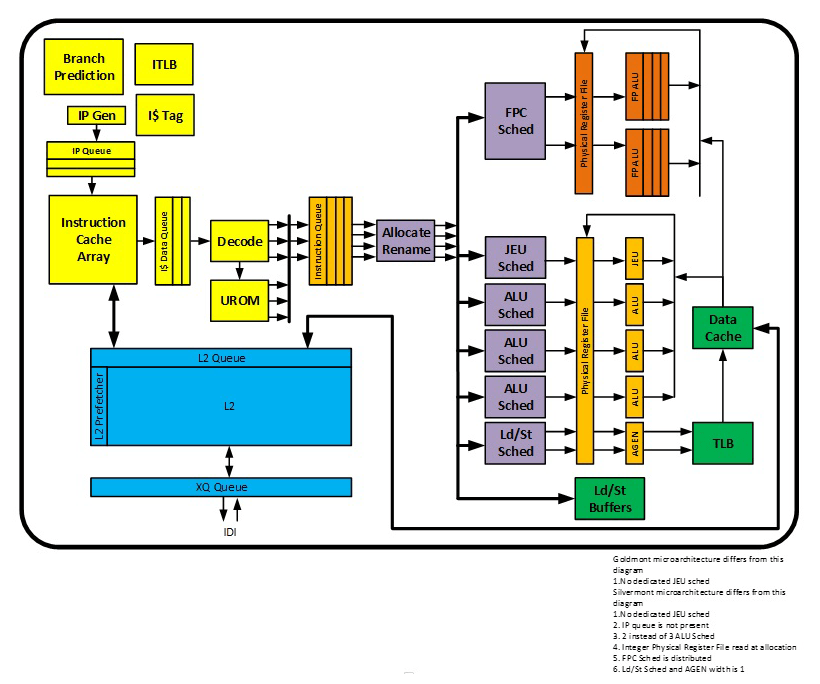 Schéma CPU jádra Goldmont+
Schéma CPU jádra Goldmont+Goldmont+ obsahuje tři ALU pipeline, což měl již Goldmont+ (pro srovnání, velká jádra jako Zen nebo Skylake dnes mají čtyři). Tyto pipeline či lépe řečeno „porty“ nejsou zcela symetrické, některé složitější operace umí zpracovat jen některé porty. Například FPU má pipeline jen dvě, takže instrukce SIMD a x87 provádí jen první dva porty. Intel ale přidal další port/pipeline, na němž se nachází jednotka označená JEU. Ta slouží speciálně pro rychlé zpracování větvení v kódu, což uvolňuje ALU/FPU pipeline pro normální instrukce. Mimochodem, stran větvení by měl být vylepšen také jeho prediktor.
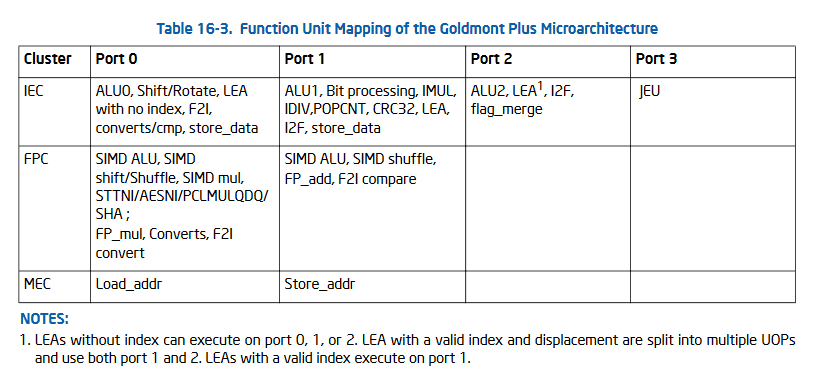 Rozpis schopností, které mají jednotlivé ALU/FPU porty. Jednotka JEU je vyhrazená pro větvení. IEC znamená provádění v celočíselné části jádra (ALU), FPC v FPU, MEC je jednotka load/store
Rozpis schopností, které mají jednotlivé ALU/FPU porty. Jednotka JEU je vyhrazená pro větvení. IEC znamená provádění v celočíselné části jádra (ALU), FPC v FPU, MEC je jednotka load/storeZvýšení IPC by dále mělo být uskutečněno pomocí zvětšení out-of-order bufferů, tedy front, ve kterých procesor může provádět operace mimo pořadí. Obecně platí, že čím jsou tyto buffery větší, tím efektivněji může procesor běžící kód přeorganizovat a tím lépe může práci paralelně rozdělit výpočetním jednotkám. Goldmont+ by měl mít větší frontu reorder buffer a reservation station. Kromě toho má také větší buffery pro operace čtení a zápisu do paměti (které tím také může lépe zoptimalizovat). Také byla snížena latence store-to-load forwardingu, tedy techniky, kdy procesor může přeskočit čtení dat, která předtím na stejné místo zapsal a ještě je má v mezipaměti.
Již z dřívějška víme, že Goldmont+ používá 4MB L2 cache (sdílenou mezi čtyřmi jádry), zatímco Goldmont a předchozí atomová jádra měla poloviční kapacitu. Intel zvětšil také tzv. pre-decode cache druhé úrovně, která má 64KB místo 16KB. Zdá se, že minimálně u části instrukcí by mohlo jádro mít o stupeň hlubší pipeline, jelikož cena za špatně předpovězené větvení je nyní 13 cyklů typicky a v některých případech 12 cyklů, zatímco u Goldmontu byl postih vždy 12 cyklů.
 Přehled inovací v jádře Goldmont+ v optimalizačním manuálu Intelu
Přehled inovací v jádře Goldmont+ v optimalizačním manuálu InteluRychlá dělička, výkonnější AES
Atomy Goldmont+ mají ještě jedno zlepšení ve výpočetních jednotkách, které potěší ty, kdo šifrují a používají tyto SoC třeba v malém domácím serveru nebo NAS. Intel totiž posílil výkon v instrukcích AES-NI. A to jak celkovou propustnost, tak latenci těchto instrukcí. Jádro díky tomu bude moci šifrovat/dešifrovat větší objem dat za sekundu. Vylepšený je také výkon instrukcí dělení v FPU. Dělička je typu radix-1024, což znamená, že proti předchozí implementaci v jednom kroku vypočítá více bitů z výsledku, ovšem za cenu větších vyhledávacích tabulek. Zdá se, že tyto početní operace Goldmont+ provádí až třikrát rychleji než předchozí Atomy. Dělení s dvojitou přesností například má latenci 14 cyklů a jádro zvládá provést jedno každých 10 cyklů. Goldmont pro srovnání potřebuje na jedno takové dělení 34 cyklů.
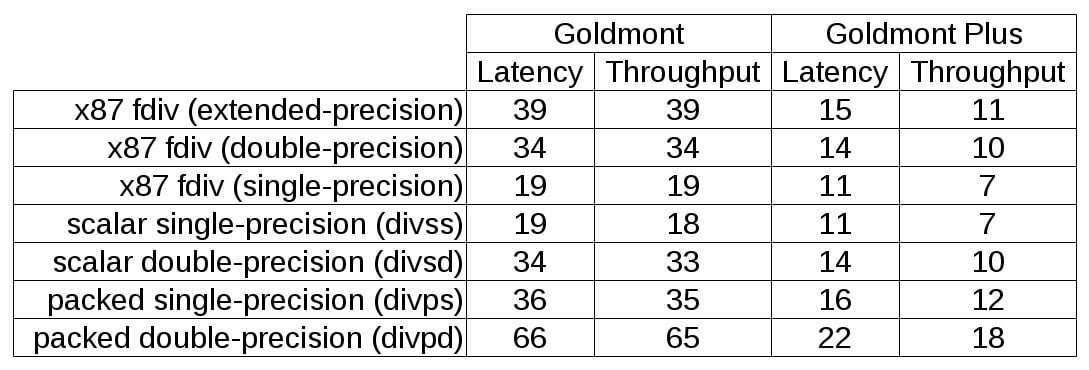 Latence a propustnost (počet cyklů na jednu operaci) děličky v Goldmontu+ (Zdroj: David Schor)
Latence a propustnost (počet cyklů na jednu operaci) děličky v Goldmontu+ (Zdroj: David Schor)Čipy Gemini Lake s jádry Goldmont+ jsou již oficiálně vydány, ale zatím se nedá koupit žádné zařízení, v kterém by se nacházely, a Intel ani žádné neposkytl pro recenze. Momentálně je proto těžké posoudit, o kolik procent se zvýší výkon jader Goldmont+ při stejné frekvenci. Máme zatím jen různá uniklá skóre z testů typu Geekbench, které mohou být ošidné. Zdá se ale, že se výkon nadzvedl o nezanedbatelná dvouciferná procenta a pravděpodobně by měl přímo konkurovat nejvýkonnějším jádrům ARM Cortex. S těmi je ale srovnání vždy dost ošidné kvůli nemožnosti změřit výkon v identickém kódu.

Zaryté mlčení o malých jádrech
Je zvláštní, jak málo Intel architekturu Goldmont+ prezentuje, přestože se jedná o docela zásadně vylepšenou architekturu. V tiskové zprávě ke Gemini Lake dokonce ani není jméno nové architektury nikde zmíněno. Svádí to k úvahám, zda Intel publicitu nepotlačuje proto, aby moc nevynikal fakt, že nemá novou architekturu ve své hlavní linii výkonných jader. Podle původního předpokládaného harmonogramu tick-tock by totiž nová architektura nahrazující Skylake měla touto dobou pomalu být na trhu, ale místo toho si na ni (10nm čipy Ice Lake) asi počkáme ještě zhruba rok či déle.
 BGA procesor z linie Intel Atom (generace Braswell)
BGA procesor z linie Intel Atom (generace Braswell)Nebo možná jde o to, že firma nyní na jádrech Atom nezakládá žádné mobilní čipy, ale jen lowendové Celerony a Pentia pro desktopy a notebooky. A ty nekonkurují rivalským procesorům ARM, ale hlavně Intelovým výkonnějším a dražším procesorům s velkými jádry (Kaby Lake, Coffee Lake). Tudíž je Intel možná nechce moc vychvalovat, jelikož mu případná popularita lowendových platforem „kanibalizuje“ výnosnější výrobky. Zatímco kdyby bojovaly proti čipům ARM jako před pár lety Bay Trail, asi by se jejich architekturou rád pochlubil.












































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU