
Nedávno vyplynulo na povrch, že Intel podle všeho zrušil svůj program mnohojádrových výpočetních (ko)procesorů Xeon Phi, který vznikl na základě linie čipů Larrabee původně zamýšlených jako hybridní GPU s architekturou x86. Příští 10nm generace Knights Hill již nevyjde, částečně asi proto, že ji zabilo několikeré opoždění tohoto výrobního procesu, dílem se asi Intel rozhodl vůbec změnit architektonickou koncepci, se kterou na sektor HPC bude mířit. Ovšem přes to, že je tím DNA Xeonu Phi asi odsouzena k záhubě, ještě neřekla poslední slovo. Intel nyní potichu vydal čip Xeon Phi „Knights Mill“, jenž je po zrušení Knights Hillu zřejmě finálním výhonkem této evoluční větve.
Čip Knights Mill je stále 14nm, byl totiž do roadmapy přidán později jako specifické řešení pro výpočty umělé inteligence, pro které je speciálně uzpůsoben, zatímco ostatní Xeony Phi mají za účel zejména vědecké výpočty a tradiční HPC úlohy s vysokým výkonem v dvojité přesnosti (F64). Knights Mill vychází z architektury Knights Landing (příbuzné s Atomem Silvermont, ale s velkými úpravami, například čtyřvláknovým HT) a zachovává jejích 72 jader, vysokorychlostní 16GB integrovanou paměť MCDRAM a šestikanálový řadič pro paměti DDR4. Má však výpočetní jednotky a instrukční sadu AVX-512 přepracovánu pro operaci s 16bitovými hodnotami a podstatně vyšším výkonem v těchto operacích, zatímco výkon v FP64 byl okleštěn.

Modely: 250–320W spotřeba
Xeon Phi Knights Mill byl vypuštěn na trh poněkud zvláštně. Intel k němu ani nevydal tiskovou zprávu, čipy se místo toho jen potichu objevily v databázi ARK. Měly by ale tímto být oficiálně vydány, partnerům jsou již dostupné. V sestavě jsou celkem tři modely: základní Xeon Phi 7235 začíná s 64 jádry, 32 MB L2 cache a taktem 1,30–1,40 GHz. Jeho omezením je kromě toho ještě podpora jen 2133MHz pamětí DDR4. Druhý model Xeon Phi 7285 má jader aktivních 68 (34 MB L2 cache) a stejné frekvence, ale již umí i 2400MHz paměti DDR4. Oba tyto čipy mají TDP 250 W. Nejvyšší model Xeon Phi 7295 se všemi 72 jádry aktivními má 36 MB L2 cache, frekvenci už 1,50–1,60 GHz, avšak jeho TDP se zvýšilo na 320 W. Mělo by asi jít o procesor se zatím nejvyšší hodnotou spotřeby na výchozích taktech, jaký kdy Intel vydal.
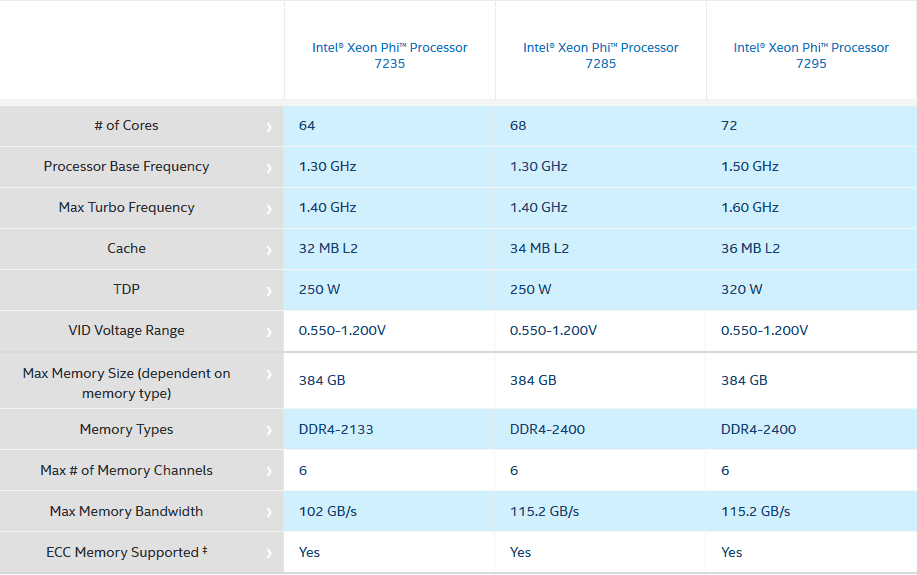 Modely Xeonu Phi Knights Mill
Modely Xeonu Phi Knights MillTěmito modely se zatím řada Knights Mill vyčerpává. Jsou všechny určené do socketu LGA 3647 jako samostatné procesory. Zda Intel uvede koprocesorovou verzi ve formě karty pro slot PCI Express (která by se hodila pro nahuštění více těchto akcelerátorů, jak se to v serverech pro strojové učení dělá), není známo, pro Knights Landing totiž tyto modely náhle zrušil. Žádný ze známých modelů také nemá integrovánu podporu pro propojovací logiku Intel OmniPath.
Změny vektorové jednotky
Již jsme zmínili, že ona adaptace čipu Knights Mill pro strojové učení („umělou inteligenci“) spočívá v úpravě vektorových výpočetních jednotek. A ta je docela zásadní. Knights Landing měl pro každé ze svých jader vektorovou jednotku s dvěma porty, které dokázaly za takt provést po jedné 512bitové instrukci FMA (512bitový vektor pracuje najednou s osmi 64bitovými hodnotami či šestnácti 32bitovými).
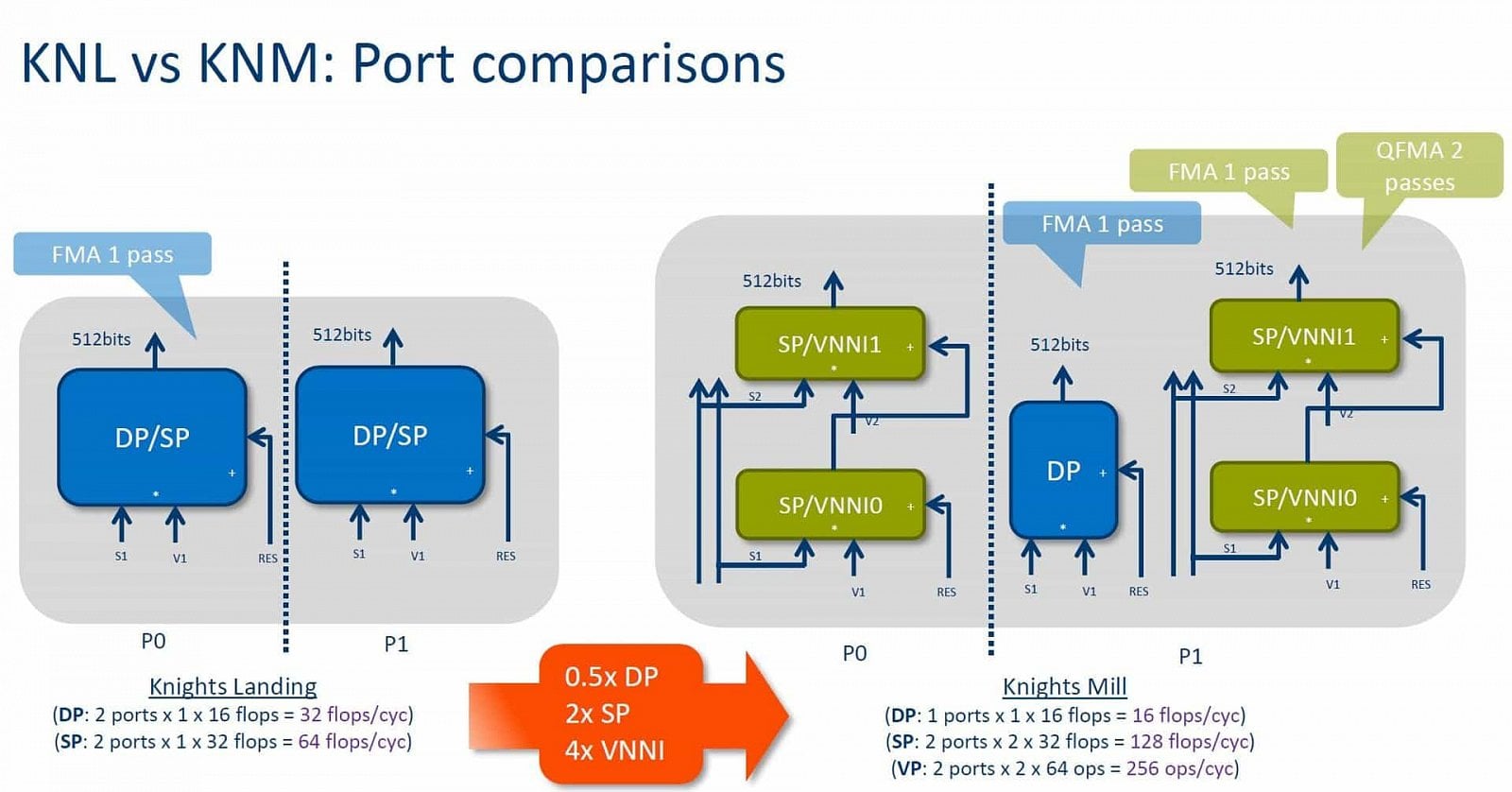 Organizace vektorové jednotky u architektury Knights Landing (vlevo) a Knights Mill (vravo)
Organizace vektorové jednotky u architektury Knights Landing (vlevo) a Knights Mill (vravo)Quad FMA
Čip Knights Mill má stále dvouportovou jednotku ACX-512, ale její schopnosti jsou značně odlišné. Jen na jednom z portů je FPU/ALU pro operace FMA s dvojitou přesností (proto poloviční výkon v FP64). Hlavními klienty těchto dvou portů jsou totiž dvě jednotky pro instrukce AVX-512 nad 32bitovými a 16bitovými hodnotami. V FP32 byl výkon při stejném počtu jednotek naopak zdvojnásoben. Používá se k tomu operace, které Intel říká QFMA (Quad FMA) a jde vlastně o zřetězení čtyř FMA za sebou, kdy se výsledek jedné FMA hned použije jako činitel pro následující FMA (vstupy pro její součtovou část jsou ale nezávislé). Vykonávání je rozděleno do dvou průchodů jednotkou (v každém jsou zřetězené dvě operace FMA), což Intel označuje jako „double-pumping“ jednotek AVX-512.
 Instrukce QFMA: čtyřnásobné zřetězené FMA v rámci AVX-512
Instrukce QFMA: čtyřnásobné zřetězené FMA v rámci AVX-512Tuto operaci přitom jednotka dokáže stále provádět rychlostí jedna instrukce za každý druhý takt (kvůli doble-pumpingu), čímž je dosaženo dvojnásobného celkového výkonu proti jednotlivým FMA. Operace QFMA má však kvůli dvěma průchodům výrazně delší latenci než standardní FMA, takže kód vyžaduje určitou úroveň paralelizovatelnosti skrze vykonávání instrukcí mimo pořadí (tzv. „ILP“), aby nedocházelo k prostojům. K využití výpočetních prostředků ovšem pomáhá i onen čtyřcestný Hyper Threading – čtyři vlákna naráz dokáží jednotky saturovat i při poměrně velkém množství „bublin“ způsobených datovými závislostmi v kódu.

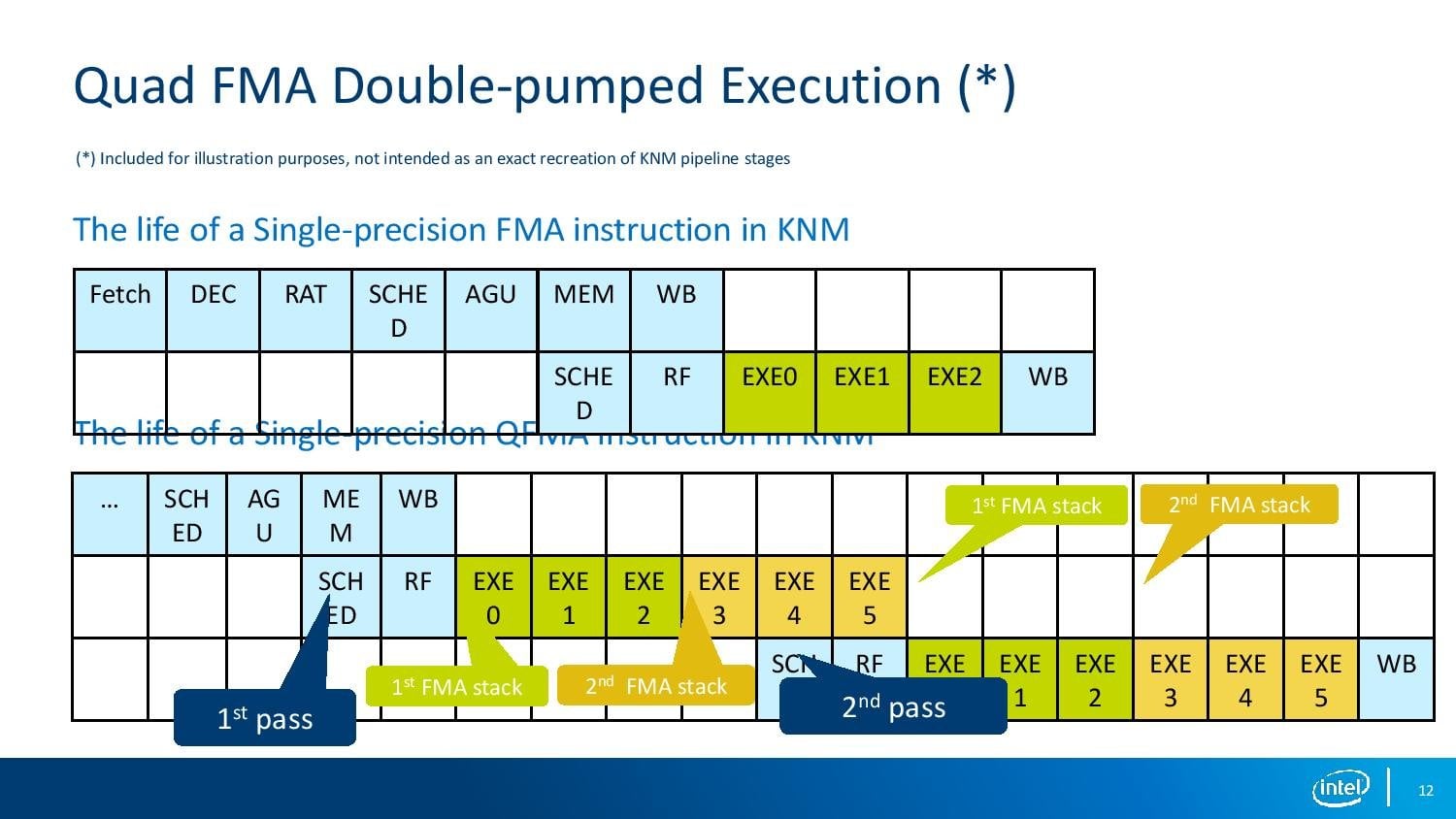 Srovnání pipeline pro výpočet běžné FMA a QFMA. QFMA je provedeno ve dvou průchodech jednotkou
Srovnání pipeline pro výpočet běžné FMA a QFMA. QFMA je provedeno ve dvou průchodech jednotkouJelikož jde ale o čip pro strojové učení, není výkon v FP32 to hlavní, neboť pro tyto operace se využívají menší datové typy. Knights Mill proto podporuje výpočty s 16bitovými hodnotami, kterých se do 512bitového vektoru vejde dvojnásobek (tedy 32) a tím pádem s nimi čip dosahuje dvojitého teoretického výkonu. V kombinaci s instrukcemi QFMA by tedy výkon měl být čtyřnásobný proti čipu Knights Landing – který dosahuje v jednoduché přesnosti něco přes 6 TFLOPS. Pokud dobře počítám, pak při maximální frekvenci by nejrychlejší Knights Mill, model Xeon Phi 7295, měl dosahovat okolo 1,63 TFLOPS v FP64, ve výpočtech se standardní přesností FP32 při použití QFMA pak 13 TFLOPS (běžné AVX-512 FMA dává 6,5 TFLOPS). V 16bitových výpočtech by to tedy mělo být 26 T(FL)OPS. Jde o čísla zhruba srovnatelná s Radeonem Instinct 25 od AMD (výkon je o něco vyšší, spotřeba ale také), ale horší než u Tesly V100 od Nvidie, která může vyvinout podstatně vyšší výkon při použití speciálních bloků Tensor Core.
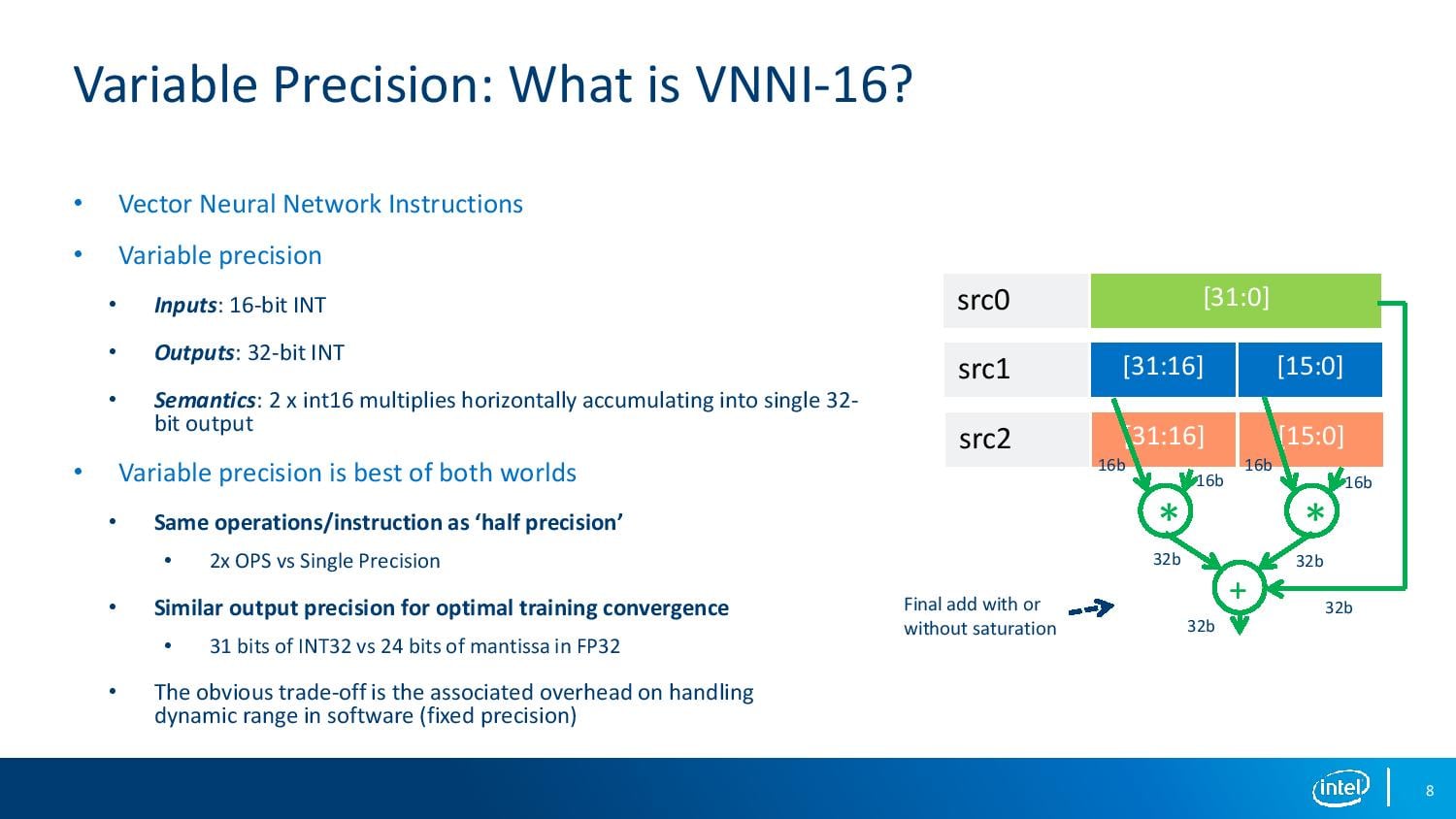 Slajd k instrukcím VNNI-16
Slajd k instrukcím VNNI-16Instrukce VNNI-16
Pro 16bitové výpočty však Knights Mill nepoužívá přesnost FP16 (floating point), ale celočíselné 16bitové hodnoty (INT16). Výpočty s nim jsou implementovány v instrukcích VNNI-16, což je opět nový subset AVX-512 („AVX512_4VNNIW“). Jejich specialitou je, že výsledky jsou ukládány s přesností INT32, případně lze INT32 použít také pro násobící člen v operaci FMA s 16bitovými sčítanci. Tento subset instrukcí bude ale zřejmě čistě specialitou Knights Millu, Intel jej alespoň zatím nehodlá přenést do ostatních architektur. Totéž platí pro QFMA (tento subset má označení AVX512_4FMAPS).






































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU