
Žádný OCR software nezaručí stoprocentní přesnost a každý převedený text musí následně projít důkladnou kontrolou
Nejvýznamnějším parametrem OCR nástrojů bývá obvykle accuracy - přesnost. Přesnost rozpoznání znaků je nejvyšším identifikátorem kvality OCR a každý výrobce se ji snaží vylepšit co nejvíce. Zlepšování jde v této oblasti přitom hned několika směry - od zdokonalování samotného rozpoznávacího mechanismu až po zabudované slovníky, ve kterých se každé převedené slovo porovnává a zpřesňuje.
Zcela na úvod je však potřeba si přiznat jednu důležitou věc: žádný OCR software nezaručí stoprocentní přesnost a každý převedený text musí následně projít důkladnou kontrolou. Navíc nesmíte zapomenout, že čím složitější je vstupní materiál (počínaje ručně psanými poznámkami), tím méně přesný je výsledek převodu.
Další nezanedbatelnou funkcí, na kterou je vhodné se při výběru OCR nástroje zaměřit, je schopnost udržet strukturu převedeného dokumentu v co nejvěrnější podobě vůči originálu. U levnějších nástrojů se často stává, že si nejsou schopny poradit s výrazněji členitým textem, takže na výstupu obdrží nespokojený uživatel nesrozumitelnou směs sesypaných odstavců a obrázků.
Za kvalitu si připlatíte
Vyzkoušet si trialverze placených OCR nástrojů už není tak jednoduché jako kdysi - jejich výrobci zareagovali na vysokou míru pirátství svého softwaru opuštěním modelu třicetidenních zkušebních verzí a u svých produktů nabízejí, v tom lepším případě, jen videoukázky práce aplikací. Mezi takové patří dva z lídrů OCR trhu: OmniPage, dostupný za 116 ‚Ǩ s podporou 123 jazyků, a Readiris s podporou sto dvaceti jazykových sad a cenou 129 ‚Ǩ. Jednou z mála aplikací, kterou si v nejnovější verzi můžete vyzkoušet na vlastní kůži, je ABBYY Fine Reader. Za 139 ‚Ǩ nabízí podporu celých 186 jazykových sad.
Testovat schopnosti známých komerčních aplikací v převodu naskenovaných tištěných dokumentů nebo dokumentů psaných na stroji by asi nemělo smysl, vyzkoušeli jsme je proto v oblasti, která nás lákala nejvíce - rozpoznávání ručně psaného textu.
Některé OCR aplikace tuto možnost nemají (ABBYY Fine Reader), jiné však funkce k převodu ručního písma nabízejí. Závěr je jednoznačný - fungují, ale s velkými obtížemi. Např. Readiris 11 Pro byl ale tak nepřesný, že tištěnou sedmičku převedl jako jedničku. Uznáváme, že vstupní tabulka, ve které každou položku psala ruka jiného člověka, byla asi příliš tvrdým oříškem, nástroj však zklamal i v převodu tištěné numerické části.
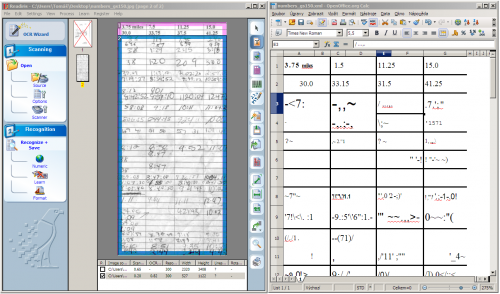
Nic to samozřejmě nemění na faktu, že se ve všech třech případech jedná o kvalitní a dostačující nástroje, u kterých je jedinou vadou na kráse snad jen příliš vysoká cena. Na trhu ale můžete narazit i na jednodušší, takzvané home verze, jejichž cena se většinou pohybuje pod hranicí tisíce českých korun.
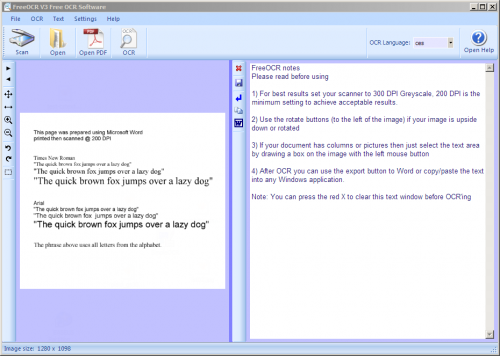
Pokud digitalizaci a převod naskenovaných dokumentů využíváte často, vyplatí se do komerčních nástrojů investovat, jestli vás ale nutnost použít OCR obvykle přepadne jen několikrát do roka, pravděpodobně sáhnete po některém z bezplatných nástrojů, jako je např. aplikace FreeOCR.
FreeOCR, převodník textu zdarma
I když existuje spousta online nástrojů (viz OCR na webu), nejpohodlnějším řešením je stále aplikace instalovaná přímo v počítači. Skenujete-li jen občas, pak jsou veškeré investice zbytečné a vyplatí se vyzkoušet zdarma dostupnou aplikaci FreeOCR (ke stažení na adrese www.paperfile.net). Nejenže přináší plnohodnotné možnosti převodu při zachování struktury textu a podporuje rozsáhlou škálu vstupních i výstupních formátů, ale především disponuje podporou jednoduše doinstalovatelných jazykových sad.
Česká jazyková sada v základním balíčku není k dispozici, patří tedy k těm, které je nutné doplnit. Pro její instalaci si stáhněte příslušný archiv ze seznamu podporovaných jazyků (soubor ces.traineddata.gz najdete na www.tinyurl.com/seznamjazyku), v programu zvolte Settings | Open Language Folder a do složky, kterou vám program otevře, jazykovou sadu jednoduše rozbalte. Po restartu aplikace pak vyberte v pravé části horního panelu češtinu.
OCR na webu
Nechcete-li si do počítače instalovat další aplikace, využijte pro převod dokumentů na citovatelný text některou z na webu dostupných aplikací.
OnlineOCR (www.onlineocr.net)
Asi nejlepší online OCR převodník, na který můžete narazit (ačkoliv se pro zpřístupnění kompletní škály funkcí budete muset zdarma zaregistrovat - jako neregistrovaného uživatele vás bude svazovat maximální limit patnácti převedených dokumentů za hodinu, omezení velikosti obrázků a možnost převádět pouze jednostránkové PDF soubory).
OnlineOCR podporuje 32 jazyků včetně češtiny - vyzkoušeli jsme ho s mírně strukturovaným tištěným českým textem a byli jsme překvapeni výbornou přesností, rychlostí i schopností udržet strukturu dokumentu.
NewOCR (www.newocr.com)
NewOCR podporuje 29 jazyků a analýzu struktury textu (což zjednodušeně znamená, že pochopí případné členění textu do sloupců a převedené odstavce seřadí správně za sebe). Opravdové zachování struktury však nečekejte, jediným výsledkem převodu je čistý text přímo v aplikaci, možnost přímého uložení do DOC nebo RTF chybí - text si tak do Wordu budete muset ručně překopírovat.
Na rozdíl od OnlineOCR se není potřeba registrovat, limit velikosti obrázků je nastaven až na 5 MB a poradí si i s vícestránkovými PDF do 20 MB. Zásadní problém ovšem nastává při vyhodnocování přesnosti přepisu. V něm totiž NewOCR trochu kulhá.

Free OCR (www.free-ocr.com)
Další zdarma a online dostupnou OCR službou je Free OCR. Umožňuje převádět obrázky do velikosti 2 MB a jednostránková PDF, maximálně však 10 za hodinu. Podporuje 29 jazykových sad, je bez registrace a přináší nesrovnatelně vyšší přesnost než předchozí služba NewOCR. Strukturu textu však také nezachovává a umožňuje export pouze do čistého textu (tedy bez jakéhokoliv formátování).









































