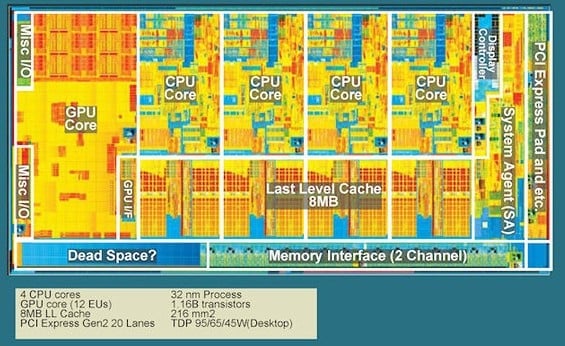
Podívejme se nejprve, čím
Intel procesory zrychlil:
- Jednou z optimalizací je vylepšený HyperThreading, tedy technologie
zpracování dvou vláken na jednom fyzickém jádře za účelem zužitkování
jinak neplodných výpočetních prostředků. V předchozích procesorech byly
při zapnutém HT určité zdroje napevno rozděleny mezi obě vlákna – určitý
buffer se například rozdělil na dvě stejné poloviny. Pokud jedno vlákno
neumělo svůj příděl využít, nemohla být nadbytečná kapacita přidělena
druhému vláknu, byť by ji i dokázalo uplatnit.
Pro výkon je tedy lepší, když jsou prostředky dynamicky rozdělovány podle
potřeby. Což je právě vylepšení, které v Ivy Bridge na určitých místech
Intel zavedl. Zdroje jako konkrétní příklad uvádějí DSB Queue, což je
fronta, ze které jsou dekódované microOPs ukládány do L0 cache.
Jen pro pořádek připomeňme, že tento bonus si užijí pouze procesory Core i3
a i7 (případně Xeony a některé i5), neboť ostatní modelové řady neumožňují HT zapnout. - Ivy Bridge dokáže (podobně jako konkurence u architektury Bulldozer)
využít přejmenování registrů pro eliminaci instrukcí MOV (kopírování
hodnot mezi registry). Tyto instrukce díky tomu vůbec nezatěžují výpočetní
jednotky, jsou totiž eliminovány již ve fázi dekódování. - Značně vylepšena byla dělička, a to jak celočíselná, tak pro práci s
pohyblivou řádovou čárkou. Průměrná propustnost jednotky je u Ivy Bridge
dvakrát větší. Ačkoliv v ručně optimalizovaném kódu by dělení pro svou
pomalost nemělo být příliš častou operací, mnohé programy mohou toto
zrychlení přesto poznat. - Intel v prezentaci z IDF 2011 rovněž zmiňuje výkonnostní zlepšení
paměťového řadiče a L3 cache, k těmto bodům ale (zatím) nejsou k dispozici
podrobnosti. - Na serveru Anandtech se však objevila informace, že došlo k vylepšení
prefetchingu. Zatímco dříve se načítání zastavovalo na hranicích
paměťových stránek, nyní je toto omezení odstraněno.
Tolik tedy
architektonická vylepšení, o kterých jsme se dozvěděli. Redaktoři VR-Zone
změřili několik benchmarků na procesorech Sandy Bridge a Ivy Bridge při stejné
frekvenci a vypnutém Turbo Boost, takže si díky nim můžeme udělat představu,
jak moc tato vylepšení pomáhají.
Zlepšení IPC se pohybuje
někde kolem 4 %: například wPrime 2.07 je rychlejší o 3 %, Cinebench R11.5 o 4 %,
x264 však až o 7 % (měřeno pomocí x264 FHD Benchmarku). Zdá se tedy, že Intel
opět zvýšil laťku ve výkonu SIMD operací, což potvrzuje kódování do formátu VP8
(benchmark v programu AIDA64), kde je zlepšení 6,5%. Podle dalších testů lze
vyvodit, že se naopak nezvýšil výkon v x87 FPU kódu (s možnou výjimkou dělení,
jak už bylo zmíněno). VR-Zone se jinak pohříchu soustředilo spíše na syntetické
benchmarky.

Přehled modelů Core i5 (Ivy Bridge v horní části, Sandy Bridge v dolní)
V reálném použití bude ovšem
nárůst výkonu procesorů o stejné základní frekvenci patrně ještě vyšší než by
plynulo ze zvýšení IPC, neboť je vysoce pravděpodobné, že procesory Ivy Bridge budou
schopné častěji přecházet do Turbo Boost.
Testy serveru AnandTech
se zapnutým tubem skutečně vykazují mezi modely i7-2600K a i7-3770K na
frekvenci 3,4 Ghz ještě větší rozdíly (až nad 10 %). Že je část výkonnostního
nárůstu realizována jen agresivnějším dynamickým přetaktováním nás ovšem nemusí
mrzet, neboť jde o integrální součást dnešních procesorů a výkon takto nahnaný
je stejně reálný jako ten, o který se zasloužila architektonická vylepšení.

Na nové procesory se tedy
máme proč těšit. Intelu patří chvála za to, jak posouvá výkon procesorů i během
menších upgradů jako je Ivy Bridge nebo dříve Penryn (který přinesl zajímavé
zvýšení výkonu například v multimédiích). Doufejme, že AMD bude v budoucnu
tlačit na pilku podobným způsobem; už brzo uvidíme, jak (zda) se pochlapí s
architekturou Piledriver, která by měla být takovým menším upgradem, podobně
jako Ivy Bridge. U AMD to ovšem budeme mít na stejném výrobním procesu, zatímco
Intel si pomůže přechodem z 32 na 22nm.