Intel jako výrobce GPU
Intel – staronový hráč na poli grafické akcelerace
 Intel a grafické akcelerátory, to je velmi zajímavá kapitola. Po neúspěchu s kartami Intel 740 společnost tento trh opustila, ale vlastně neopustila, protože se stáhla do segmentu integrovaných grafických jader. Ačkoliv jen málokdo by o Graphics Media Acceleratoru uvažoval jakožto o řešení pro hry, v hrubých číslech je Intel se svými IGP největším dodavatelem grafických adaptérů (i když Nvidia tvrdí, že přes 70 milionů jich je „mrtvých“, a tak je jedničkou ona).
Intel a grafické akcelerátory, to je velmi zajímavá kapitola. Po neúspěchu s kartami Intel 740 společnost tento trh opustila, ale vlastně neopustila, protože se stáhla do segmentu integrovaných grafických jader. Ačkoliv jen málokdo by o Graphics Media Acceleratoru uvažoval jakožto o řešení pro hry, v hrubých číslech je Intel se svými IGP největším dodavatelem grafických adaptérů (i když Nvidia tvrdí, že přes 70 milionů jich je „mrtvých“, a tak je jedničkou ona).
Přesto je však Larrabee z velké části výlet do neprobádaných končin. A to nejen z toho důvodu, že prosazení samostatného grafického akcelerátoru vyžaduje daleko vypilovanější ovladače, spolupráci s herními vývojáři a marketing, než to, co Intel zatím předvádí u svých integrovaných GMA. Druhým důvodem je architektura Larrabee, která má s dnešními IGP pramálo společného.
Intel vyvíjí Larrabee už poměrně dlouho – během té doby postupně zveřejňuje informace a přísliby, na což Nvidia s oblibou reaguje tak, že Larrabee je snímek z prezentace, a proto nemá důvod se jej bát. Mají se Kaliforňané obávat, nebo ne? Na jednoznačnou odpověď je ještě příliš brzy, ale snad budete po přelouskání článku o něco moudřejší. Intel byl poměrně sdílný, pamatujte ale, že mnoho dílků do skládačky ještě chybí. Některé se dozvíme už 12. srpna na konferenci SIGGRAPH 2008.
CPU, nebo GPU?
Intel si sám je dobře vědom toho, že snažit se o výkonné grafické jádro by pro něj bylo bruslení po tenkém ledu. Proto u Larrabee využil svých zkušeností z toho, co umí nejlépe. Larrabee má tedy narozdíl od klasických GPU velmi blízko k mnohojádrovému procesoru. Jelikož výpočetní jednotky staví na architektuře x86, bude na Larrabee možno provozovat softwarové renderovací enginy. Zároveň ale čip podporuje Direct3D a OpenGL.

Intel si zavčasu všiml, že shadery grafických čipů dosahují při schůdných výrobních nákladech daleko lepšího teoretického výkonu, než jaký je schopen poskytnout obyčejný dvou- nebo čtyřjádrový procesor. A také, že od vysoce specializovaných jednotek se vývoj ubírá k unifikaci a univerzálnějším „stream procesorům“. A zatímco ATI a Nvidia postupně vytváří ze specializovaných čipů univerzální, Intel se rozhodl jít opačnou cestou a vyjít z vysoce univerzálního základu mnohojádrového x86 procesoru.
Paralelizace se tedy stala základní ideou Larrabee. Je však velmi těžké využít potenciál grafického jádra pro jiné výpočty, i když jejich hrubá síla dokáže často divy i s nepříliš dobře optimalizovanou aplikací. Tento problém chce Intel alespoň částečně ošetřit právě tím, že jednotky Larrabee zvládají instrukční sadu x86.
Od Pentia kolem Atomu k Larrabee
Larrabee aneb pravnuk původního Pentia
Jako základní stavební kámen Larrabee Intel oprášil staré Pentium (jádro označené P54C). Nejen s přihlédnutím k jinému zaměření Larrabee ale musela patnáct let stará koncepce doznat jistých změn.
 Ilustrace vlevo ukazuje, jak vypadá (velmi zjednodušeně) každá výpočetní jednotka grafického čipu z rodiny Larrabee. Co původní Pentium nemělo, byla vektorová jednotka. Ta dokáže provádět jednu instrukci na až 16 hodnot zároveň (pro srovnání, superskalární jednotky GPU ATI jsou pětisložkové). Larrabee si také poradí s 64bitovým rozšířením instrukční sady x86. Možná se dočkáme i podpory instrukcí SSE.
Ilustrace vlevo ukazuje, jak vypadá (velmi zjednodušeně) každá výpočetní jednotka grafického čipu z rodiny Larrabee. Co původní Pentium nemělo, byla vektorová jednotka. Ta dokáže provádět jednu instrukci na až 16 hodnot zároveň (pro srovnání, superskalární jednotky GPU ATI jsou pětisložkové). Larrabee si také poradí s 64bitovým rozšířením instrukční sady x86. Možná se dočkáme i podpory instrukcí SSE.
Anandtech také spekuluje, že jádra Larrabee a procesor Atom mohly vzejít z jednoho projektu. Atom je taktéž primitivní x86 procesor s in-order vykonáváním příkazů, leč s modernější instrukční sadou: Atom obsahuje SSE jednotku a podporuje instrukce AMD64 (Intel je nazývá EM64T).
Instrukční pipeline Atomu má 16 stupňů (jádro Yonah, architektura Core i AMD K8/K10 mají podobně dlouhé pipeline). Pentium P54C má pětikrokovou pipeline a dle vyjádření Intelu je Larrabee blíže právě tomuto číslu (přesnou délku výrobce neprozradil).
Pentium, Atom a Larrabee se rozcházejí také v počtu vláken, která je procesor schopen vykonávat současně. Pentium si o HyperThreadingu mohlo nechat jen zdát, Atom je díky této technologii schopen zpracovávat dvě vlákna naráz, jednotka Larrabee ale zvládne až čtyři vlákna zároveň. Anandtech sestavil tabulku srovnání dvou existujících procesorů a jednoho zatím hypotetického jádra v čipu Larrabee:

Jednotka v Larrabee má k dispozici 2× 32 kB L1 cache (pro data a instrukce), L2 cache má velikost 256 kB. Anandtech vysvětluje, že tato velikost je vhodná zejména díky tomu, že Larrabee bude standardně používat tile-based (dlaždicový) rendering. L2 cache by pak plnila mimo jiné roli „malého framebufferu“ a lze snadno spočítat, že blok 128 × 128 px, každý s 32bitovou informací o barvě, se vejde do 128 kB. Pro ostatní data by tak zbyla přesně zbývající polovina cache. (Případně blok 64 × 64 pixelů, každý s 32bitovou informací o barvě a 32bitovým Z bufferem; takový zabere 64 kB.)
Oproti Pentiu a snad i Atomu by jednotky Larrabee měly mít vylepšené tzv. prefetchery – zjednodušeně řečeno algoritmy, které procesoru předem připravují data, se kterými bude pracovat. Předpokládá se, že prefetchery Larrabee budou optimalizovány pro silně paralelizované výpočty, detaily však známy nejsou.
Článek byl inspirován a napsán podle článku serveru Anandtech Intel's Larrabee Architecture Disclosure: A Calculated First Move, části o renderingu a mnoho ilustrací vzniklo díky materiálům společnosti Intel.
Larrabee versus ATI a Nvidia
Vektorová jednotka proti stream procesorům
Zatím jsme na Larrabee pohlíželi jako na procesor a srovnávali s jinými procesory. Nyní jej pojďme porovnat s dnešními architekturami grafických čipů od ATI a Nvidie. Lépe řečeno budeme porovnávat jednotky Larrabee se stream procesory.

Už jsme nakousli, že Larrabee nemá být pouze grafický akcelerátor. Velký důraz je kladen také na GPGPU nasazení. U Nvidie a ATI se do teoretického výpočetního výkonu ve FLOPS počítají shadery, u Larrabee se na tomto čísle největším dílem podepíší 16složkové vektorové jednotky.

Jedna vektorová ALU umí pracovat s až 16 hodnotami naráz, to ovšem pouze v případě, že se jedná o výpočty s jednoduchou přesností (FP32, single precision). Ve výpočtech s 64bitovou přesností (double precision) jednotka pracuje pouze s osmi čísly. To zní velmi dobře, je ale dost možné, že FP64 operace se budou provádět na dva nebo více průchodů, takže výkon v double precision bude oproti single precision nižší než poloviční.
Pro srovnání, superskalární jednotky ATI dokáží v 64bitové přesnosti pracovat s jednou hodnotou namísto pěti v FP32 (teoretický výkon je tedy pětinový). Stream procesory Nvidie double precision neumí.

Mnozí z vás se jistě ptají, jak je to s využitelností tak široké jednotky. Je pravda, že Larrabee bude v tomto ohledu velmi závislý na kompilátoru, více než čipy ATI. Na druhou stranu, jedny z nejlepších kompilátorů vytváří právě Intel. Takže zatímco pro Nvidii nebo ATI by vec16 jednotka byla příliš velký risk, Intelu to jako jedinému může projít.
Záhadou také zůstává, jak si Larrabee poradí s dynamic branchingem. Už jsme si řekli, že čip rozsekává scénu na vlákna – bloky po 64 × 64 nebo 128 × 128 px a na každé takové „dlaždici“ pracuje jedno jádro. Dynamic branching, postup standardizovaný v Shader Modelu 3.0 (DirectX 9.0c) je tím efektivnější, čím je počet pixelů v jednom vlákně nižší. Pokud by tedy větvení mělo probíhat na úrovni celých jader s vlákny o 4096/16384 pixelech, efektivita by byla velmi špatná. Anandtech ale spekuluje, že by další rozdělování na vlákna mohla provádět vektorová jednotka, čímž by byl problém vyřešen.
Ring-bus a paměťový řadič
Na diagramu na předchozí stránce jste si mohli všimnout, že každé jádro je připojeno k ring-busu. Ten má u Larrabee šířku 1024 bitů (stejně jako u ATI R600), každým směrem vede 512 bitů. ATI, která tuto interní sběrnici začala používat jako první, od ní u RV770 upustila. Ring-bus je sice velmi rychlý, ale také pochopitelně zabírá nějaké místo v čipu. Protože zdaleka ne všichni klienti na ring-bus napojení jeho luxusní propustnost využijí, je rychlá sběrnice místy zbytečná.
Jelikož se očekává, že Larrabee bude pracovat na frekvenci vyšší než 2 GHz, bude ring-bus ještě více než dvakrát rychlejší, než ten v R600. Larrabee má ale předpoklady jej využít smysluplněji. Dobrým základem je, že všechny jednotky jsou stejné. Ring-bus nebude sloužit pouze k propojení výpočetních jednotek a řadičů pamětí, ale také pro komunikaci mezi jádry a udržování cache coherency (synchronizace vyrovnávacích pamětí).

Jednoduché schéma rozložení částí čipu zobrazuje dva paměťové řadiče, každý fyzicky na jedné straně čipu. ATI a Nvidia používají zpravidla řadiče (kanály) o šířce 64 bitů, které jsou vázány na bloky RBE jednotek. Pokud by i Intel použil 64bitové kanály, Larrabee by měla pouze 128bitovou sběrnici. Pro nejvyšší model to není příliš pravděpodobné, nicméně Larrabee bude mimo jiné díky již zmíněnému tile-based renderingu s pamětí nakládat efektivněji, než to umí její kalifornští a kanadští soupeři. Krom toho Qimonda slibuje, že technologie GDDR5 pamětí je škálovatelná na vysoké frekvence, takže nelze vyloučit ani možnost, že v roce 2009 bude 128 bitů stačit.
Počet jader, bližší pohled na cache
Kolik jader bude mít Larrabee?
Zatím jsme se věnovali téměř výhradně pouze samotným jádrům, které tvoří základ Larrabee. Kolik jich ale bude? Intel poskytl pouze tento graf škálování výkonu:
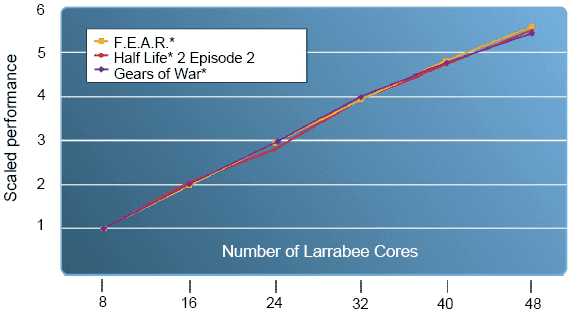
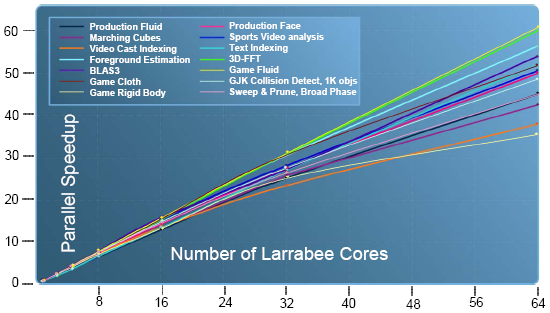
Anandtech uvažoval, kolik jader by se vešlo na jeden čip, uvažujíc 45nm výrobu. TSMC vyrábí pro Nvidii čipy s plochou 576 mm2, pokud by i Intel měl podobný „rozpočet“ (a jeho továrny jsou považovány za kvalitnější, než TSMC), mohl by na jeden čip vtěsnat možná až 64 jader. Hrubý výpočet podle plochy ale nebere v úvahu spotřebu, jakou by takový čip měl a je docela možné, že Intel dříve narazí na strop spotřeby než na strop plochy čipu.
Cache a jejich hierarchie
Připomeňme si tabulku z druhé stránky a schéma ze stránky předchozí:

Jedno jádro Larrabee má celkem 64 kB L1 cache, čtyřnásobek toho, co mělo k dispozici staré Pentium. Larrabee ale dokáže zpracovávat čtyři vlákna naráz, takže čtyřnásobná velikost dává smysl. Původní Pentium také nemělo integrovanou L2 cache. Každé jádro Larrabee má této k dispozici 256 kB.
Ne nadarmo je ale L2 znázorněna jako jeden velký obdélníček, tak nějak to v hotovém čipu skutečně bude vypadat. Jádra ale budou mít přístup pouze ke svým vyhrazeným 256 kilobajtům a budou-li vyžadovat data uložená v cache jiného jádra, budou si je muset nechat přinést ring-busem. Architektura vyrovnávacích pamětí v Larrabee se obecně vyznačuje velmi nízkými latencemi.
Dalším specifikem Larrabee oproti běžným grafickým čipům je, že jednotlivé úseky cache jsou plně koherentní, laicky řečeno se chovají tak, jako cache u vícejádrových CPU. Význam to může mít zejména u multi-GPU konfigurací, se kterými by Intel dle svých vlastních slov měl mít méně problémů, než Nvidia a ATI se SLI a CrossFire.
Zachovat koherenci cache u dvou čipů je teoreticky možné, limitujícím faktorem je ale propustnost, které lze mezi nimi dosáhnout. Ohledně Larrabee a možností pro multi-GPU nemáme příliš mnoho informací, očekává se ale, že Intel v tomto směru udělá nějaké pokroky vůči současným řešením.
Článek byl inspirován a napsán podle článku serveru Anandtech Intel's Larrabee Architecture Disclosure: A Calculated First Move, části o renderingu a mnoho ilustrací vzniklo díky materiálům společnosti Intel.
Programování pro Larrabee, efektivita ve hrách
Lepší než CUDA?
Co se GPGPU využití týče, udělala Nvidia vstřícný krok s platformou CUDA. Díky ní lze na jejích grafických akcelerátorech provozovat aplikace napsané v populárním jazyce C. Larrabee má pochopitelně ambice být ještě lepší. Jelikož to ve své podstatě je mnohojádrový x86 procesor, přesně tak jej programátor může chápat a použít. Jádra Larrabee samozřejmě neuvidíte ve správci úloh jako další systémové procesory, nicméně v některé z dalších generací, bude-li pro to uzpůsoben operační systém, je to teoreticky možné.
Pro Larrabee lze psát programy také ve standardním C nebo C++. Narozdíl od platformy CUDA, zde bude možno využít osvědčené kompilátory třeba od Intelu nebo Microsoftu. Takové programy lze pro Larrabee psát přímo, což poskytuje programátorovi větší flexibilitu než například právě CUDA a výsledek by měl běhat rychleji. Což zní hezky a takto napsáno to nevrhá na současná GPU dobré světlo, jenže…
…jakmile přijde na grafiku, tedy Direct3D a OpenGL kód, pozice se obracejí. Grafické čipy ATI a Nvidia jsou přímo stavěny pro tato grafická rozhraní: instrukce D3D nebo OGL se při běhu aplikace rovnou převádějí na interní instrukce čipu. U Larrabee ale toto „přemapování instrukcí“ probíhá softwarově. Softwarová mezivrstva překládá instrukce D3D a OGL do vlastního rozhraní a Larrabee pak provádí softwarový rendering.

Tento „překladač“ prý pracuje velmi efektivně, stále toto řešení ale vyvolává dojem nutného zpomalení, nebo minimálně vyšších nároků na CPU. To se ale Intelu docela hodí, protože kdyby se vize Nvidie stala skutečností, Intel by své výkonné procesory prodával jen těžko. Zvolený přístup má ale i praktické výhody. Pokud vývojář postrádá nějakou funkci v Direct3D nebo OpenGL, může si ji sám napsat přes Larrabee C/C++. Softwarová mezivrstva prý také sníží nároky grafického čipu na paměťovou propustnost. Že by tedy Larrabee přeci jen stačila 128bitová sběrnice?
Co má s Larrabee společného Michael Abrash?
Přesně tuto otázku jsem si kladl při pročítání článku na Anandtechu, z nějž čerpá text, který právě čtete. Pokud jste výše zmíněné jméno nikdy neslyšeli (jako já), vězte, že Michael Abrash je světem protřelý programátor, který mimo jiné u id Software pracoval na vývoji hry Quake a napsal několik knih o programování grafiky a optimalizaci software. Intel si jej přizval jako poradce při vývoji Larrabee, aby mohl předem uzpůsobit instrukční sadu čipu vývojářům přesně na míru. Pregnantně řečeno vývojářům ze staré školy, pro které softwarový rendering býval denní chléb.
To alespoň částečně vyvažuje kostrbatost Direct3D a OpenGL renderingu na Larrabee, nicméně nesmíme zapomínat na to, že vývojáři nemají příliš v lásce specifické technologie a postupy, které lze uplatnit pouze na hardware jednoho výrobce. Bez opravdu masivní spolupráce s herními studii se tedy vlastní speciality prosazují těžko. Dle mého názoru jediná firma, komu by něco takového mohlo projít, je Nvidia.

MJ: Jeden z velmi zajímavých průzkumů, kterými Intel motivuje k řešení typu Larrabee (vícero naprosto univerzálních jednotek namísto specializovaných). Tvrdí, že neexistuje typické rozložení náročnosti operací a každá hra si klade zcela různé požadavky na různé jednotky. Pak logicky nemůže existovat grafický čip (mluvíme o typické konstrukci GPU), co by měl pro všechny hry ideální architekturu

MJ: Intel se ve své tezi pojišťuje a ukazuje dokonce velkou rozkolísanost nároků v rámci střídání scén v jediné hře.
Slepá ulička, nebo potenciál do budoucna?
Zatím jsme porovnávali jednotky Larrabee s procesory a stream procesory grafických čipů. Ale jak jste si pravděpodobně všimli, zatímco stream procesory tvoří pouze část klasického grafického čipu, Larrabee nemá žádné texturovací ani rasterizační jednotky.
=> doplněno: podle oficiálních dokumentů Intelu jsou v čipu přítomny specializované jednotky pro filtrování textur. Ty ale vyžadují asistenci hlavních výpočetních jednotek. Rasterizační jednotky pak opravdu chybí, tato funkce je nahrazena softwarově.
Je to mnohojádrový x86 procesor s širokými vektorovými SIMD jednotkami, provádí softwarový rendering (přes který emuluje Direct3D a OpenGL) a de facto je to přístup hrubé síly.
Obecně přitom platí, že specializované jednotky s pevnou funkcí dokáží svou úlohu provádět rychleji a energeticky úsporněji, než univerzální procesor. Současný trend ale spěje k větší univerzálnosti grafických jader. Otázkou tedy je, zdali bude Larrabee považována za technologicky vyspělejší, nebo se o ní bude říkat, že příliš předběhla dobu.
Díky této univerzálnosti bude alfou a omegou schopností čipu pouze jeho výkon. Larrabee nebude možno označit za čip s podporou Direct3D 10 nebo 11. Emulovat lze cokoliv, vývojáři se navíc nemusí držet v hranicích standardních API a napsat si takové funkce, které se jim zrovna hodí. Jedinou hranicí je výkon.
Je to právě tato flexibilita, která může – a samozřejmě také nemusí – navždy změnit podobu trhu grafických akcelerátorů. Už nikdy bychom nemuseli hledět na podporovanou verzi Direct3D, nemuseli bychom se hádat, je-li 10.1 více než 10. Neplatilo by, že jedna architektura je pro určitou hru vhodnější, než jiná. Grafickou kartu bychom měnili v době, kdy by nám přestal dostačovat výkon té staré.
Úspěch Larrabee tedy bude záležet z velké části na tom, jaký výkon se Intelu podaří vykřesat s jeho přístupem.
Práce s vlákny, tile-based (binning) rendering – jak Larrabee vykresluje
Jak Larrabee rozplétá nitky
Už jsme si řekli, že každé jádro Larrabee dokáže pracovat na čtyřech vláknech zároveň. Ta se ovšem uvnitř jednotky dále rozplétají na menší vlákna. V češtině se mi nedostává potřebného množství ekvivalentních pojmů, převezmu tedy anglickou nomenklaturu, kterou používá Anandtech.
Čtyři vlákna zpracovávaná jednou jednotkou jsou tedy jednoduše threads. Každý thread si pak své úkoly rozdělí do „fibers“, těch může být až osm. Každý fiber má tedy nějaká data a nějaké instrukce, které na nich má provést; to zajistí tak, že vytvoří jednu nebo více skupin „strands“. Každá taková skupina má vždy 16 strands, pochopitelně proto, že vektorová jednotka pracuje s 16 hodnotami.

Nebudeme zabíhat do podrobností a namísto „jak to dělá“ si rovnou povíme, co to dělá. Tento systém má za úkol eliminovat vlivy latencí, které nevyhnutelně vznikají například když je potřeba jednotce doručit data z paměti. Mějme na paměti, že jednotky Larrabee jsou in-order jádra, neumí si tedy příkazy uspořádat do efektivnějšího sledu. Latence by za normálních okolností způsobia, že jednotka by téměř stále na něco čekala a nemohla pracovat.
K tomu by u Larrabee docházet nemělo, na druhou stranu ale také není dobře, pokud bude čip zahlcen příliš velkým počtem vláken a podvláken. Stále platí, že vyždímat z Larrabee maximum nebude procházka růžovým sadem.
Tile-based rendering
O něm už jsem se také zmínil, ale teprve nyní si povíme, v čem se přesně liší od způsobů používaných Nvidií a ATI a jaké jsou jeho výhody.

MJ: Intel své obdobě tile-based renderingu říká binning rendering a opravdu se přístupu známenu z PowerVR Kyro (viz níže) podobá. Dělí se na Front End a Back End, přičemž Front End zpracovává několik primitiv paralelně a ukládá množinu binů (zásobníků) pro každé z nich do paměti. Ve fázi Back End se stejně paralelně stará o vykreslení do frame bufferu a to právě po dlaždicích (tiles).
Již zaznělo, že obraz bude rozdělen na části, zřejmě na čtverce 64 × 64 nebo 128 × 128 px. Pro každý čtverec se uloží geometrická data, tedy souřadnice vrcholů trojúhelníků, které do něj zasahují. Na každém čtverci zvlášť se pak provádí Z culling (tedy vyřazení objektů, které jsou zakryty jinými) a operace shaderů. Flexibilita Larrabee umožňuje provádět Z culling prakticky kdykoliv. S nepotřebnými daty se tak čip zdržuje co možná nejméně.
Stojí za zmínku, že akcelerátory řady PowerVR Kyro, které před lety nabízel čip vyráběný společností STMicroelectronics, taktéž používaly tile-based rendering. Tyto grafické karty se neprosadily a byly převálcovány zejména Nvidií; ani ona, ani ATI, si tile-based přístup neosvojily a stále se drží koncepce „okamžitého renderingu“ (immediate mode rendering). Ten je obecně považován za rychlejší a některé postupy se pro něj implementovaly snáze, ale často zbytečně počítá zakryté části scény a má proto větší nároky na paměťovou propustnost. Právě kvůli tomu přežívá tile-based rendering u akcelerátorů pro handheldová zařízení.
MJ: Abychom byli přesní, rivalem immediate mode renderingu (okamžitého vykreslování) je deferred (odložené) či display list (seznamem řízené) vykreslování. Tento přístup se diametrálně liší od okamžitého vykreslování (schéma: načti grafické primitivum, zpracuj, vykresli) a díky tomu, že jsou grafická primitiva nejprve načtena do seznamu všechna a poté zpracována a vykreslena, se mnohem lépe řeší ideální „počítej jen to, co je nakonec vykresleno“. Čip PowerVR Kyro pak ve scénách s vysokou mírou překreslení (demonstrováno třeba v demo-benchmarku PowerVR VillageMark) dokázal držet krok s o generaci novějšími kartami jako GeForce 3 nebo předčit i papírově silnější (a na výrobu třeba díky DDR pamětem) daleko dražší řešení jako GeForce 2 GTS s dvojnásobkem pixel pipeline. Tile based rendering (či zone rendering u Intel GMA) je variací na tento pro běžná GPU typu Radeon či GeForce neznámý postup. Při dnešním stavu křemíku už možná není chytrý přístup jako tile based rendering u GPU tolik potřeba, ale kombinace lepšího hardware, zabudování podpory alespoň pro DirectX 8 (pixel a vertex shader 1.x) a tile based renderingu mohla z nakonec nikdy nevydaného PowerVR Kyro III (či Series 5) udělat ještě větší štiku než jakou bylo Kyro II.
Kdybychom se vrátili ještě dále, dostaneme se až k projektu Talisman. Pod tímto kódovým jménem se Microsoft chystal uvést dostatečně rychlé grafické řešení za velmi dostupnou cenu (hranice 100 USD). Vykreslování se jmenovalo tiled rendering a vůbec se nejednalo o odložený rendering a vlastně ani o nic podobného dnešku. Microsoft chtěl neotřelým přístupem rychlého skládání 2D podobrazů (dlaždic) zkomponovat 3D scénu a dramaticky tak šetřit propustnost.
Shading
Jádra v Larrabee provádějí také operace, které u klasických GPU zajišťují shadery. Vypadá to přibližně následovně:

Back End zpracování probíhá tak, že jednotka založí jedno řídící vlákno (načtením dat ze zásobníku dlaždice (tile)), které rozparceluje přidělený čtverec na fragmenty. Ty pak předává zbývajícím třem threadům, které provedou testy hloubky (Z), potáhnou geometrické modely texturou, provedou pixel shading, anti-aliasing (pokud je vyžadován) a alpha blending. Dlaždice je uložena v L2 cache a do paměti (řádově pomalejší) se tak sahá jen jednou.
Vraťme se ještě k výhodám, které poskytuje volnost softwarového renderingu. Příklad funkce, která se na klasických GPU implementuje ne zrovna pohodlně, je průhlednost objektů. Vysvětlujte totiž algoritmům Z cullingu, že některé polygony stíní a jiné ne! U Larrabee bude možné nastavit, které části geometrie mají být vidět, i když jsou zakryty jinými polygony – bez nutnosti složitého obcházení limitací klasických 3D adaptérů.
Je více technik, které se na klasických GPU buď složitě implementují, nebo jsou neefektivní, a na Larrabee poběží rychleji. Všechno bude ale záviset na tom, do jaké míry bude vývojář ochotný odklonit se od univerzálně použitelného D3D/OGL kódu k programovacímu modelu blízkému Larrabee.

MJ: Intel ilustruje výhody binning renderingu oproti běžnému (immediate mode) ušetřením paměťové propustnosti. To je ve hře typu F.E.A.R. dramatické, v Gears of War stále velmi velké a v Half-Life 2: Episode 2 už zdánlivě ne tak významné. Intel zdůraňuje, že u immediate mode renderingu je předpokládán perfektní hierarchický Z cull (odstřelení neviděného) a 1 MB jak pro cache hloubky, tak barvy
Larrabee a Tera-scale
Předzvěst budoucnosti procesorů?
Pamatujete ještě na projekt Tera-scale? Jeho ambiciózním cílem bylo vyvořit (monolitický) procesor s teoretickým výkonem přes 1 TFLOPS a na jedné z akcí seriálu IDF byl předváděn prototyp čipu s 80 jednoduchými jádry – tedy něco podobného, jako bude Larrabee. Ale jaké implikace vlastně Larrabee přináší pro budoucnost procesorů?

Zdá se, že Intel opustil koncepci mnoha jednoduchých jader a přijal přístup, jehož soudobým příkladem je procesor Cell. V procesorech bude několik málo „velkých“ jader, která si zachovají vysoký výkon v jednovláknových úlohách, a vedle toho desítky až stovky jednoduchých a úsporných jader, které z čipu udělají drtiče v silně paralelizovaných aplikacích. Takový procesor by pak mohl počítat třeba i grafiku. Koncepce tile-based renderingu by přitom zajistila, že propustnost pamětí (která se u procesorů nemůže rovnat propustnosti u samostatných grafických akcelerátorů) nebude tak velkým limitem, jako by byla dnes.
Co se může pokazit?
Na papíře vypadá Larrabee velmi slibně, mimo jiné také proto, že jsme na předchozích stránkách srovnávali produkt, který bude vydaný koncem roku 2009, s technologiemi let 2006 a 2007. Úspěch Larrabee bude pochopitelně záviset na více faktorech. Co konkrétně by Intelu mohlo činit problémy?
Výroba. 45nm proces bude koncem roku 2009 už zavedený a problémy vychytané, přesto s každým čipem je to loterie. Může se stát, že čip nedosáhne původně očekávaných taktů (jak se to stalo Nvidii s G200), nebo že v návrhu čipu bude chyba způsobující snížení výkonu nebo částečnou nefunkčnost (o tom by naopak mohly vyprávět AMD a ATI).
Výkon. Bude Larrabee schopen držet krok s řešeními, které budou v době jejího vydání nabízet Nvidia a ATI? Jak se vyrovná s tím, že rendering přes standardní grafická API musí emulovat?
Ovladače. Špatné ovladače pohřbily již mnoho nadějného hardware. V tomto ohledu nevíme, co můžeme od Intelu čekat; mnoho z vás má pravděpodobně zkušenosti s ovladači pro integrovaná grafická jádra, ovladače pro Larrabee ale vyvíjí jiný tým, ve kterém působí mnoho bývalých zaměstnanců 3DLabs.
Spolupráce s vývojáři. Když se mluví o ATI a Nvidii, často se jako důvod absence programu spolupráce s vývojáři u ATI zmiňuje nedostatek financí. Intel rozhodně nepatří ke společnostem, které by tento problém trápil, nicméně se bude muset vyrovnat se silnou pozicí Nvidie v tomto odvětví a jak se mu to podaří, je zatím ve hvězdách.
Pár slov závěrem
Pokud jste článek poctivě přečetli až do konce, možná máte více otázek, než jste měli před jeho přečtením. Vězte však, že s ohledem na to, že Larrabee bude vydána nejdříve za rok, je Intel o její architektuře nevídaně sdílný.

Dá-li se něco říci závěrem, pak je to asi to, že Intel pojal svůj vstup na trh samostatných grafických akcelerátorů poměrně odvážně, a to i přesto, že snaha udělat něco jinak nakonec byla základem neúspěchu akcelerátoru Intel 740. Larrabee se téměř vůbec nepodobá dnešním grafickým čipům. Nemá texturovací ani RBE jednotky, vše provádí x86 jádra a jejich vektorové jednotky. Zaměření na GPGPU je velmi čitelné; pokud se ale Larrabee neprosadí jako 3D akcelerátor, samotný GPGPU trh vývoj nezaplatí.
O Larrabee zcela jistě ještě mnoho uslyšíme, jak se bude blížit její vydání. Po dlouhých letech, kdy se o převahu přetahovaly pouze Nvidia a ATI, vstoupí na trh nový hráč. Hráč, který má ambice a (narozdíl od S3 Graphics) také finanční možnosti soupeřit i v high-endu. Na otázku položenou na začátku, tedy zdali se ATI a Nvidia mají obávat, ale neznáme a ani nemůžeme znát odpověď. I kdybychom tušili, jaký výkon bude mít Larrabee, ohledně technologií a architektury budoucích GPU z červeného a zeleného tábora pořád tápeme.

MJ: Intel ukázal malé přísliby toho, že by navzdory současnosti mohl být průkopníkem v lepší kvalitě obrazu. Malý drak v mlze vlevo není vykreslen korektně, protože není použit postup s mnoha vrstvami jako vpravo. Nepřesnost se týká právě místa, kde je menší drak zakryt nejen mlhou, ale i křídlem většího draka (či draka v popředí). Právě mlha už není pod křídlem správně spočítána.


MJ: Vlevo je stín vypočítaný podle dnes běžného postup shadow maps, vpravo pomocí IZB (irregular Z-Buffer).
Článek byl inspirován a napsán podle článku serveru Anandtech Intel's Larrabee Architecture Disclosure: A Calculated First Move, části o renderingu a mnoho ilustrací vzniklo díky materiálům společnosti Intel.







































