Protože mě sledování hardwaru a různých výkonnostních srovnání dlouhodobě baví, vycházel jsem samozřejmě z těchto údajů. Zastával jsem názor víceméně shodný s úvodními větami a občas používaný freewarový benchmark Euler 3D mi dával za pravdu – ukazoval takřka ideální škálování s počtem jader. Na vlastní měření nebyl příliš prostor – výpočty musí běžet, nejlépe na co nejvíce jader, nárůsty výkonu při přechodu na novou architekturu byly znatelné, jednoduše nebyl důvod nevěřit předpokladům.
Jednoho dne se nám na konferenci naskytla možnost mluvit s jedním z programátorů, zodpovědných za vývoj CFX, a samozřejmě přišla řeč i na otázky GPU výpočtů a jak se projeví AVX2 u Haswellu. Odpovědí nám byl chápavý úsměv a prohlášení ve smyslu, že „GPU zkoušeli a zatím se nevyplatí“ a „AVX nic nezmění, úzká hrdla jsou jinde“. Nechápal jsem tehdy, o čem je řeč, všude se přece mluví o vyšším výkonu pro matematické operace. Celá věc mi od té doby vrtala v hlavě, a nakonec jsem se rozhodl použít jeden z rutinních případů jako standardní test a začal jsem měřit. A nestačil jsem se divit… Ale napřed ještě krátké povídání k výpočtům jako takovým a použitému testu:
Použitý benchmark a CFD
V tuto chvíli by možná nebylo od věci, popsat stručně numerické výpočty, tj. oč běží a k čemu jsou vlastně dobré, pro touto problematikou nedotčené čtenáře. (Případní v oboru vzdělanější jedinci mi nepřesnosti v rámci zjednodušení jistě odpustí.)
Velké množství známých fyzikálních a jiných jevů (hoření, deformace těles, proudění kapalin atd.) lze popsat diferenciálními rovnicemi. Neboli, máte rovnici, a pokud ji dokážete správně vyřešit, máte i přesný popis děje, který jste ani nemuseli vidět. Proč řešit problémy takto oklikou? Protože reálné děje bývají často nedostupné, nebo nákladné. Představte si třeba automobilku, která by ladila karoserii auta pro crash testy pouze na základě zkoušek. Nabourat, vyhodnotit, upravit, nabourat…
Aby věc nebyla tak jednoduchá, většinu takovýchto rovnic neumíme vyřešit přímo – tj. není znám žádný postup, kdy by stačilo rovnici dosadit do nějakého výrazu a „vypadl“ přesný výsledek. Naštěstí existují numerické metody, přibližné, povětšinou spočívající v tom, že se vezme trojrozměrný model oblasti, ve které probíhá sledovaný děj, tato oblast se vhodně rozdělí na menší podoblasti (takzvanou výpočetní síť) a místo „skutečného“ řešení se hledá přibližné ve tvaru polynomů na každé podoblasti. Takovou úlohu řešit umíme, a při dostatečně podrobné síti se v rozumné míře shoduje s realitou. Vyžaduje ovšem řešení velkých soustav rovnic, s maticemi řádově klidně až 108 ×108. Což je také důvod, proč rozvoj těchto metod nastal až s nástupem výkonných počítačů. A na rozdíl od „běžných uživatelských činností“, na které stačí v podstatě jakýkoliv dnešní stroj, není v případě numeriky výkonu nikdy dost.
CFD (z anglického Computational Fluid Dynamics) je zkratka pro numerické modelování proudění tekutin. Například návrhy tvarů letadel, karoserií Formulí 1 a zčásti také meteorologie, to všechno je oblast využití CFD. V naší firmě tvoří hlavní náplně práce výpočet charakteristických (závislost dopravní výšky na průtoku) a strhávacích křivek čerpadel. Pro představu, na dnešním čtyřjádrovém procesoru trvá kompletní výpočet čerpadla klidně i měsíc, počítače u nás tudíž rozhodně nezahálejí…
Klepněte na náhled pro zobrazení v plné velikosti
Testovaný příklad sestavoval kolega, takže podrobnější popis přenechám jemu:
Geometrie, následně opatřená výpočetní sítí, na které bylo testování uvedených procesorů provedeno, vychází z odstředivého diagonálního čerpadla s axiálním rozvaděčem. Původní geometrie byla opatřena savkou u vstupu do oběžného kola a na výstupu se nacházelo 90° koleno, které dále ústí do potrubního systému. Vzhledem k tomu, že takto definovaná oblast je již značně rozsáhlá a pro testování výpočetního výkonu i zbytečná, byla geometrie zredukována s ohledem na splnění podmínky rotační symetrie. Rotačně symetrické úlohy lze totiž řešit se zahrnutím podmínek rotační symetrie na vybraném výřezu z kompletní geometrie. S ohledem na fakt, že oběžné kolo v tomto provedení má osm lopatek a axiální rozvaděč má devět lopatek, byl pro testovací výpočet nakonec uvažován jeden kanál oběžného kola a jeden kanál axiálního rozvaděče, z důvodu, že vzájemný poměr počtu kanálů se blíží 1. Představu o výsledné podobě geometrie použité pro testovací úlohu vzhledem k původní celkové geometrii ukazuje následující obrázek.
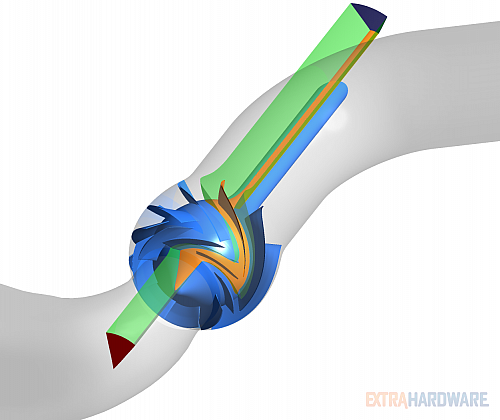
Geometrie výpočetní oblasti
Jakmile je známa podoba výpočetní oblasti, nelze ještě začít s modelováním proudění. Výpočetní oblast je totiž ještě nutné opatřit výpočetní sítí. Ta je tvořena na sebe navazujícími nepřekrývajícími se elementy, na které jsou pak v průběhu řešení aplikovány nástroje pro numerické modelování. Pro ilustraci je na následujícím obrázku vyobrazena podoba výpočetní sítě na vybraných plochách použité geometrie. Konečný počet uzlů na výpočetní síti dosáhl počtu 453933. Pro samotné řešení proudění je ještě nutné nastavit tzv. okrajové podmínky atd., o těch zde ale není třeba dále pojednávat.

Podoba výpočetní sítě na vybraných plochách
Pro úplnost ještě dodám, že výsledný čas zapisuje CFX přímo do log souboru, dá se tudíž snadno odečíst. Výpočet běží celou v operační paměti a vytěžuje daný počet jader na sto procent, výsledky jsou zároveň velice stálé (vychází pořád stejně, s odchylkou v rámci přesnosti měření) a nezávislé na čemkoliv jiném, než je procesor, základní deska a paměť, tj. pevný disk nebo grafická karta nehrají roli. Zkoušel jsem i jiné úlohy, a výkonnostní poměry mezi různými počty jader a různými sestavami se nelišily. Jako výkonnostní benchmark je tedy zvolený případ v podstatě ideální.
Měřené sestavy
1. Xeon E3-1230v2 Ivy Bridge-WS, 3,3GHz (3,7GHz Turbo), 8 MB cache, Hyper-Threading
- Intel DQ77MK
- 32 GB DDR3 Kingston HyperX, 1600 MHz, CL10-10-10-24
- Windows 7 Professional 64-bit SP1
2. Core i5-3550P Ivy Bridge-DT, 3,3GHz (3,7GHz Turbo), 6 MB cache
- Intel DH77DF
- 32 GB DDR3 Corsair Vengeance LP, 1600 MHz, CL10-10-10-27
- Windows 7 Home Premium 64-bit SP1
3. 2× Xeon E5450 Harpertown, 3,0 GHz, 12 MB cache
- Intel S5000XVN
- 16 GB ECC DDR2 667MHz, CL5-5-5-15
- Windows Vista Business 64-bit SP2
4. 2× Xeon X5550 Nehalem-EP, 2,67 GHz (3,067 GHz Turbo), 8 MB Cache, Hyper-Threading
- Intel S5520HC
- 24 GB ECC DDR3, 1333 MHz, CL9-9-9-24
- Windows 7 Professional 64-bit SP1
5. Dell T7600, 2xXeon E5-2687W Sandy Bridge-EP, 3,1 GHz (3,8 GHz Turbo), 20 MB cache, Hyper-Threading
- 64 GB ECC DDR3, 1600 MHz, CL11-11-11-28
- Windows 7 Professional 64-bit SP1
Předmluva, použitý benchmark a testované sestavy
Výsledky a závěr
Výsledky
První přišla na řadu nejnovější sestava s Xeonem řady Ivy Bridge a porovnával jsem různé konfigurace.
| Tab. 1 - Xeon E3-1230v2, HT on, 1333 MHz, Turbo off | |||
| počet jader | čas (s) | výkon | výkon/jádro |
| 1 | 1345 | 100% | 100% |
| 2 | 774 | 174% | 87% |
| 3 | 649 | 207% | 69% |
| 4 | 637 | 211% | 53% |
| 5 | 675 | 199% | 40% |
| 6 | 682 | 197% | 33% |
| 7 | 688 | 195% | 28% |
| 8 | 700 | 192% | 24% |
| 2 + 2 | |||
| 2 | 1057 | 127% | 64% |
| 2 | 1069 | 126% | 63% |
| Tab. 2 - Xeon E3-1230v2, HT on, 1333MHz, Turbo on | |||
| počet jader | čas (s) | výkon | výkon/jádro |
| 1 | 1255 | 100% | 100% |
| 2 | 746 | 168% | 84% |
| 3 | 636 | 197% | 66% |
| 4 | 617 | 203% | 51% |
| 2 + 2 | |||
| 2 | 1037 | 121% | 61% |
| 2 | 1053 | 119% | 60% |
| Tab. 3 - Xeon E3-1230v2, HT on, 1600MHz, Turbo on | |||
| počet jader | čas (s) | výkon | výkon/jádro |
| 1 | 1250 | 100% | 100% |
| 2 | 726 | 172% | 86% |
| 3 | 595 | 210% | 70% |
| 4 | 562 | 222% | 56% |
| 2 + 2 | |||
| 2 | 951 | 131% | 66% |
| 2 | 955 | 131% | 65% |
| Tab. 4 - Xeon E3-1230v2, HT off, 1600MHz, Turbo on | |||
| počet jader | čas (s) | výkon | výkon/jádro |
| 1 | 1213 | 100% | 100% |
| 2 | 712 | 170% | 85% |
| 3 | 582 | 208% | 69% |
| 4 | 549 | 221% | 55% |
Z tabulky 1 je vidět, že využití virtuálních jader při zapnutém HT nedává smysl, výkon klesá. Což nebylo žádné překvapení, výpočet plně vytěžuje FPU jednotky procesoru a žádná volná kapacita nezbývá, zato roste režie na paralelizaci.
Překvapilo mě, že úloha relativně špatně škáluje s počtem jader, z toho důvodu jsem zkusil ještě dva testy současně, oba po dvou jádrech. Výsledek byl o něco lepší. Nicméně výkon má do dvojnásobku z jediného výpočtu na dvou jádrech daleko, z čehož se dá usuzovat, že omezení je hlavně na straně procesoru, nikoliv CFX jako takového. Pro úplně srovnání by bylo potřeba porovnat výsledky jednoho výpočtu na různém počtu jader s více souběžnými výpočty na jednom jádru. K tomu ale bohužel nemáme k dispozici dostatečný počet licencí.
I s tímto omezením je tabulka 5 dostatečně vypovídající.
| Tab. 5 - Vliv různých konfigurací na výkon | |||
| počet jader | Turbo on/off | 1600/1333MHz | HT on/off |
| 1 | 7,2% | 0,4% | -3,1% |
| 2 | 3,8% | 2,8% | -2,0% |
| 3 | 2,0% | 6,9% | -2,2% |
| 4 | 3,2% | 9,8% | -2,4% |
| 2 + 2 | |||
| 2 | 1,9% | 9,0% | |
| 2 | 1,5% | 10,3% | |
Zapnutí HT sníží výkon zhruba o dvě procenta. (Takže se nevyplatí vypínat – počítač je jinak při výpočtu na čtyři jádra nepoužitelný.) Zapnutí turba se projeví hlavně u jednoho jádra, pak přínos klesá. Ano, vím, že procesor zvyšuje frekvenci více při zapojení méně jader, nicméně třeba v případě jednoho i dvou jader je frekvence +400MHz, přesto je nárůst pro dvě jádra menší. K tomu je krásně vidět vliv vyšší frekvence pamětí – pro jedno jádro v rámci chyby měření, pro čtyři jádra 10% výkonu navrch.
Naměřené výsledky ukazovaly na silnou závislost na paměťové propustnosti, proto jsem ještě porovnal časování CL9 a CL11, a to na 1333MHz, protože 1600MHz CL9 odmítaly Kingstony naběhnout.
| Tab. 6 - Vliv časování pamětí, 1333 MHz, 4 jádra | |||
| test | CL11 | CL9 | rozdíl |
| 1 | 652 | 611 | 6,7% |
| 2 | 639 | 604 | 5,8% |
| 3 | 629 | 606 | 3,8% |
Pro větší přesnost jsem tentokrát provedl tři měření a průměrný rozdíl přes pět procent je také docela významný. (V tu chvíli jsem docela litoval, že jsem si do počítače „nevydupal“ Crucial BallistiX LP s časováním CL8…)
Postupně jsem se dostal do stádia, kdy mě přestalo bavit spouštět pořád další a další testy, proto jsem věnoval chvíli čtení návodů a naučil se spouštět výpočet v dávkovém režimu z příkazové řádky. Pro jistotu jsem se jenom ujistil, že vliv na naměřené hodnoty je minimální a všechny další výsledky jsou již získané tímto postupem.
| Tab. 7 - Xeon E3-1230v2, HT on, 1600 MHz, Turbo on, dávka | ||||
| počet jader | čas (s) | výkon | výkon/jádro | rozdíl |
| 1 | 1230 | 100% | 100% | 1,6% |
| 2 | 724 | 170% | 85% | 0,3% |
| 3 | 584 | 211% | 70% | 1,9% |
| 4 | 556 | 221% | 55% | 1,1% |
Další parametr s velkým vlivem na výkon by měla být cache procesoru. Využil jsem pro srovnání počítač s Core i5-3550.
| Tab. 8 - Core i5-3550, 1600 MHz CL10, Turbo on | ||||
| počet jader | čas (s) | výkon | výkon/jádro | vs. 1230v2 |
| 1 | 1180 | 100% | 100% | 4,2% |
| 2 | 682 | 173% | 87% | 6,2% |
| 3 | 570 | 207% | 69% | 2,5% |
| 4 | 549 | 215% | 54% | 1,3% |
Frekvence (včetně turba) stejná, základní deska v obou případech Intel, paměti 1600 MHz CL10, Xeon má navíc HT a 8 MB cache místo 6 MB. Čekal jsem vítězství Xeonu, přesto je „obyčejná“ i5-tka rychlejší, a rozdíl je o něco větší, než by odpovídalo pouhému vypnutí HT. Napadá mě jedině buďto vliv rozdílné verze Windows (Professional vs. Home Premium), nebo jedině ještě, že by větší cache u Xeonu byla o něco pomalejší, jak se občas stává. (Jenom hádám, „negooglil“ jsem, jestli je to pravda.)
Předchozími testy jsem získal v rámci možností dostatečnou představu o závislosti výkonu na nastaveních, nastal čas vyzkoušet i ostatní sestavy, tentokrát už bez dalšího „pokusničení“.
Jako první přišla na řadu služebně nejstarší stanice v konfiguraci 2× Xeon X5450.
| Tab. 9 - 2× Xeon E5450, 667 MHz ECC | |||
| počet jader | čas (s) | výkon | výkon/jádro |
| 1 | 3196 | 100% | 100% |
| 2 | 1814 | 176% | 88% |
| 3 | 1679 | 190% | 63% |
| 4 | 1372 | 233% | 58% |
| 5 | 1477 | 216% | 43% |
| 6 | 1345 | 238% | 40% |
| 7 | 1414 | 226% | 32% |
| 8 | 1280 | 250% | 31% |
Jestli jsem do této chvíle žil v domnění, že výkon dvou starších procesorů je stále dostatečný, výsledné časy mě rychle vyvedly z omylu. Ani při využití všech osmi jader nedokázala sestava dorovnat jedno jádro nejnovějšího Xeonu. Ve světle toho, že každé výpočetní jádro se platí zvlášť, jsou výsledky docela tristní a používání této stanice by vlastně bylo plýtváním licencemi. Situace je o to zajímavější, že teoretický výpočetní dvou X5450 by měl být zhruba srovnatelný s E3-1230v2. Všimněte si také toho, jak relativní výkon na jádro neklesá plynule, ale spíše skokově s lichými počty – dle mého názoru se zde projevuje vliv architektury „slepené“ z jednotlivých dvoujader. (Však také v ANSYSU až do příchodu Nehalemu doporučovali na výpočty Opterony…)
Dále jsem prověřil novější sestavu 2× Xeon X5550.
| Tab. 10 - 2× Xeon X5550, HT on, 1333 MHz ECC | |||
| počet jader | čas (s) | výkon | výkon/jádro |
| 1 | 2875 | 100% | 100% |
| 2 | 1384 | 208% | 104% |
| 3 | 1103 | 261% | 87% |
| 4 | 897 | 321% | 80% |
| 5 | 844 | 341% | 68% |
| 6 | 784 | 367% | 61% |
| 7 | 774 | 371% | 53% |
| 8 | 741 | 388% | 48% |
Tady už je výkon i jeho závislost na počtu použitých jader podstatně lepší. Je zde ovšem jedna zvláštnost. Zatímco výsledky se zapnutým HT mají očekávaný průběh a jsou opakovatelné, při jeho vypnutí vypadají rozhodně „zajímavěji“, navíc pokaždé jinak.
| Tab. 10a - 2× Xeon X5550, HT off, 1333MHz ECC | |||
| počet jader | čas (s) | výkon | výkon/jádro |
| 1 | 2383 | 100% | 100% |
| 2 | 1550 | 154% | 77% |
| 3 | 1603 | 149% | 50% |
| 4 | 1236 | 193% | 48% |
| 5 | 1305 | 183% | 37% |
| 6 | 939 | 254% | 42% |
| 7 | 1038 | 230% | 33% |
| 8 | 866 | 275% | 34% |
Vysvětlení nemám, ale obdobně se projevuje i následující sestava se dvěma CPU, takže se nejspíše jedná o problém dvouprocesorových konfigurací. Klidně může být na vině i chyba v BIOSu, přece jenom, s vypnutým HT už v dnešní době výrobci příliš nepočítají. Problém jsem každopádně blíže nezkoumal, protože na požadované využití počítačů nemá negativní dopad.
A teď k poslední sestavě:
| Tab. 11 - Dell T7600, 2xXeon E5-2687W, HT on, 1600 MHz ECC | |||
| počet jader | čas (s) | výkon | výkon/jádro |
| 1 | 1669 | 100% | 100% |
| 2 | 801 | 208% | 104% |
| 3 | 587 | 284% | 95% |
| 4 | 475 | 351% | 88% |
| 5 | 441 | 378% | 76% |
| 6 | 422 | 395% | 66% |
| 7 | 364 | 459% | 66% |
| 8 | 302 | 553% | 69% |
| 9 | 293 | 570% | 63% |
| 10 | 308 | 542% | 54% |
| 11 | 276 | 605% | 55% |
| 12 | 266 | 627% | 52% |
| 13 | 245 | 681% | 52% |
| 14 | 229 | 729% | 52% |
| 15 | 233 | 716% | 48% |
| 16 | 227 | 735% | 46% |
Je vidět, že Sandy Bridge-EP opravdu hraje jinou ligu. Přesto neškáluje ideálně, k čemuž jistě přispívá i velký rozdíl mezi základní frekvencí a maximálním turbem (3,1 vs. 3,8 GHz). I tak je ovšem pokles výkonu větší, než by odpovídalo pouhému rozdílu frekvencí, a bohužel se ukázalo, že koupě nejvýkonnějšího modelu byla zbytečnou investicí. Vzhledem k dostupným licencím je nesmysl využívat tuto sestavu jakkoliv jinak než na všech šestnáct jader, což by níže taktované levnější modely zvládly stejně dobře, a na dvou jádrech je zase rychlejší Xeon řady E3.
Na závěr ještě pár grafů, jako základ slouží nejslabší Xeon X5450, Core i5-3550 jsem vynechal, protože se příliš neliší od Xeonu E3-1230v2.
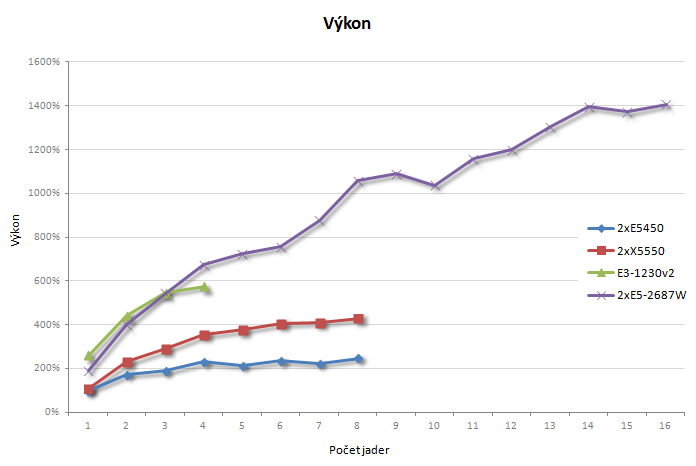
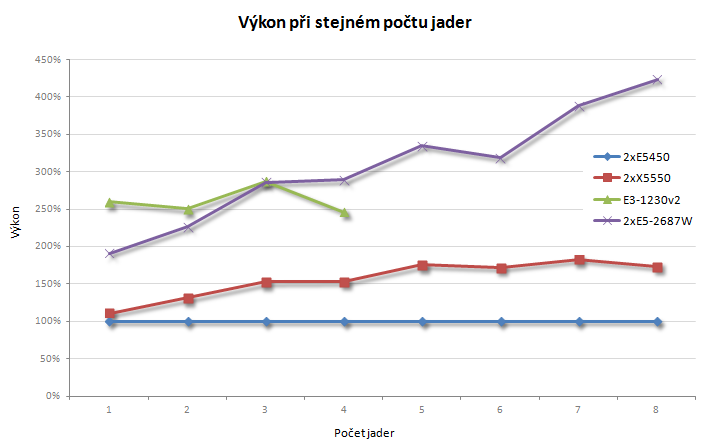
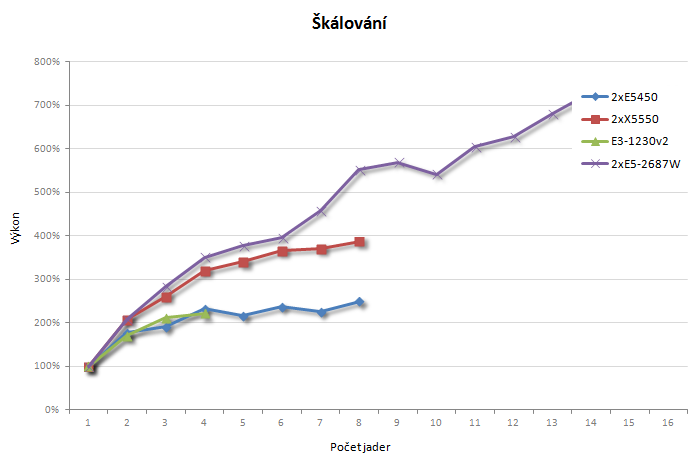
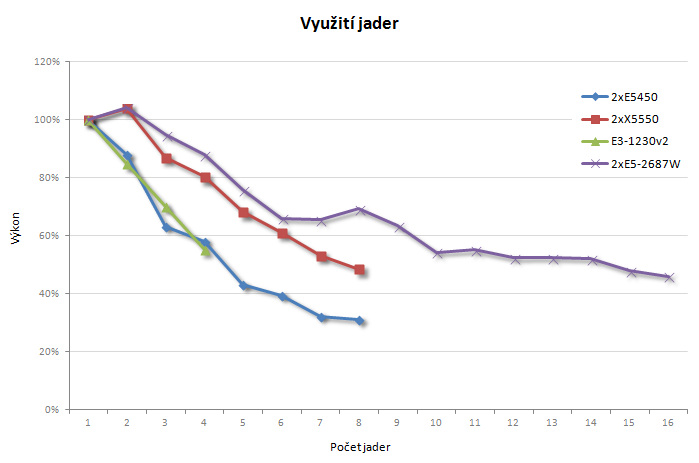
Závěr
Cílem tohoto článku není nějaké úplné výkonnostní srovnání (k tomu by bylo potřeba změřit více sestav), ani bych nějakým způsobem nechtěl extrapolovat získané výsledky na více jader a zpochybňovat tvrzení ANSYSu o takřka lineárním škálování výkonu na výpočetních clusterech. Přece jenom, kombinace uzlů se dvěma procesory s rozumným TDP (tj. nižší frekvencí a menším omezením ze strany pamětí) propojených sběrnicemi s propustností desítky GB/s bude o něčem trochu jiném.
Spíše jsem chtěl na příkladu z praxe ukázat, že sebelepší testy nemusí vždy postihnout skutečný problém, a že s paralelizací není vše tak růžové, jak by si člověk rád myslel. Když se vrátím k úvodním větám:
- Výkon na jádro je občas důležitý i u úloh, které jsou dobře paralelizovatelné, minimálně proto, že s rostoucím počtem jader platíte více za licence.
- Použití AVX a jiných instrukčních sady nemusí znamenat vyšší výkon, i dnešní procesory mají úzká hrdla. Jinak řečeno, data protečou rychleji procesorem, ale přes paměťové sběrnice už nikoliv.
- Z toho samého důvodu nemusí být ani GPU výpočty takový přínos, jak by se zdálo při srovnání teoretických výkonů. V CFD se grafické karty zatím výrazně neprosazují.

Další zajímavé zjištění pro mě bylo, že dny trvající výpočty se dají bez problémů provádět i na obyčejných (ne-ECC) pamětech a že nejvýhodnější varianta by byla přetaktovat obyčejné čtyřjádro s rychlými pamětmi a „ždímat, co to jde“. (Podobné postřehy jsem už na fórech párkrát zaznamenal, takže jsem evidentně neobjevil nic nového…)
Je mi jasné, že pro běžné uživatele nejsou tyto informace nikterak přínosné, přesto mi přišly dostatečně zajímavé na to, abych se o ně podělil, a jsem rád za každého čtenáře, který dočetl až sem. Na závěr bych rád poděkoval kolegům v práci za pomoc s článkem a redakci ExtraHardware za zveřejnění – cením si toho.











































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU