
Loni bylo toto téma na vzestupu a letos se mu prakticky nevyhnete: umělá inteligence. Tato technologie (přesněji řečeno neuronové sítě a strojové učení pomocí nich) je nyní považována za nesmírně perspektivní oblast, a to zdaleka nejen kvůli samořídící vozidlům. Výrazně by z ní mohla profitovat Nvidia, které v této oblasti našla využití pro svá výpočetní GPU. Možná se ale chystá nový soupeř, proti kterému se bude muset na tomto poli pochlapit. Procesory určené speciálně pro umělou inteligenci totiž chystá japonské Fujitsu.
IT práci firmy Fujitsu se moc nevěnujeme, nicméně možná víte, že dlouhodobě vyrábí výkonná CPU. Tradičně s architekturou Sparc, nyní ovšem zřejmě přechází na ARM. Tato CPU pak Fujitsu kromě „big iron“ serverů používá hlavně ve svých speciálních superpočítačích. Jeho stroje se značně odlišují od průměru hlavně silným důrazem na výkonnou propojovací logiku, díky které mají velmi dobrý poměr mezi papírovými FLOPS a reálným výkonem při řešení nejnáročnějších problémů. A právě pro enterprise a superpočítače Fujitsu AI čipy chystá – zřejmě počítá spíše s nasazením ve velké škále než v menších systémech.
DLU
Na problém strojového učení Fujitsu vrhne speciální procesor či akcelerátor nazvaný DLU – Deep Learning Unit. Půjde o heterogenní architekturu, kombinující na jeden procesor CPU se specializovanými výpočetními jednotkami. Fujitsu použije několik velkých procesorových jader „Master“, které by asi mohly být podobné výkonným jádrům použitým v jeho stávajících CPU. Tato jádra budou zajišťovat základní běh a řídit skupinu výpočetních jader se zjednodušenou (specializovanou) architekturou nazvaných DPU – Deep Learning Processing Units. Právě DPU budou zajišťovat výpočetní výkon čipu.
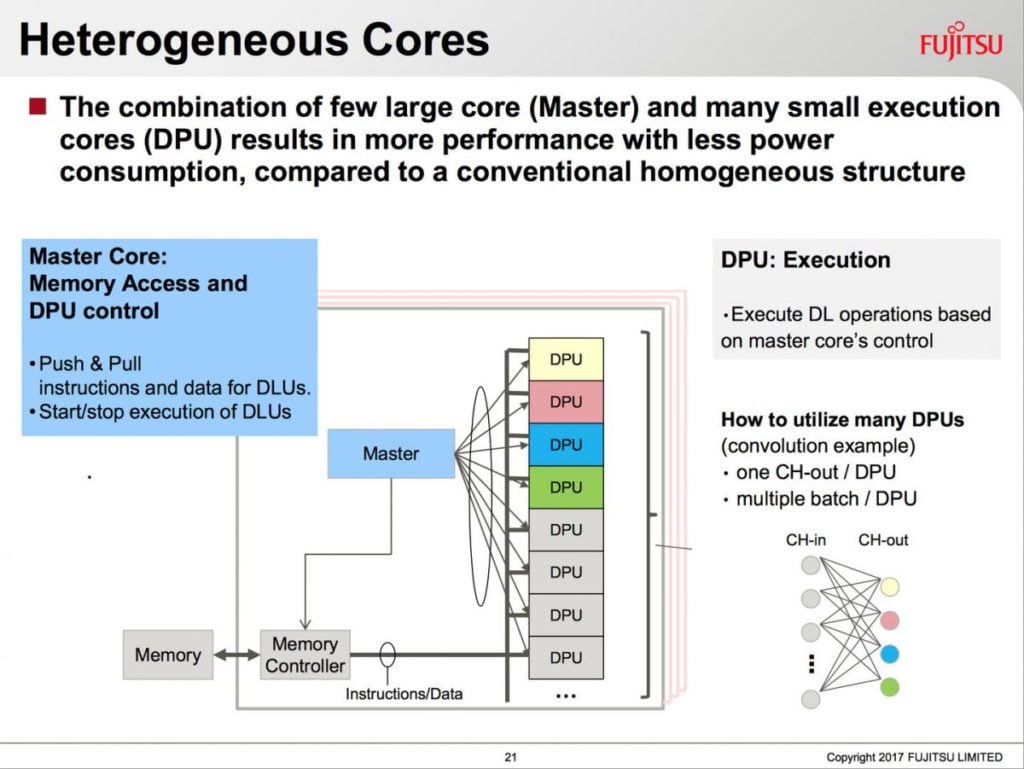 DLU bude heterogenní procesor kombinující univerzální jádra a paralelní výpočetní akcelerátory
DLU bude heterogenní procesor kombinující univerzální jádra a paralelní výpočetní akcelerátoryKaždé jádro DPU bude poskytovat značný paralelismus k běhu mnoha operací naráz. V DPU se nachází 16 jednotek DPE (Deep Learning Processing Elements), přičemž každé DPE obsahuje 8 vektorových (SIMD) výpočetních jednotek, sdílejících údajně velký soubor registrů. DPU by měly na čipu být propojené nějakým typem sítě a spolu s jádry Master budou používat rychlou paměť typu HBM2 integrovanou na procesoru.
Na komunikaci bude zřejmě kladen důraz i nad úrovní jednoho čipu. Procesory DLU totiž budou zřejmě podporovat pokročilou propojovací logiku Tofu 2, kterou Fujitsu používá ve svých superpočítačích. Díky ní z nich bude možné postavit velké klastry. Zdá se, že zatím se počítá s tím, že DLU nebudou v jednotlivých uzlech pracovat samostatně, místo toho poběží jako akcelerátory podřízené nějakému hostitelskému CPU.
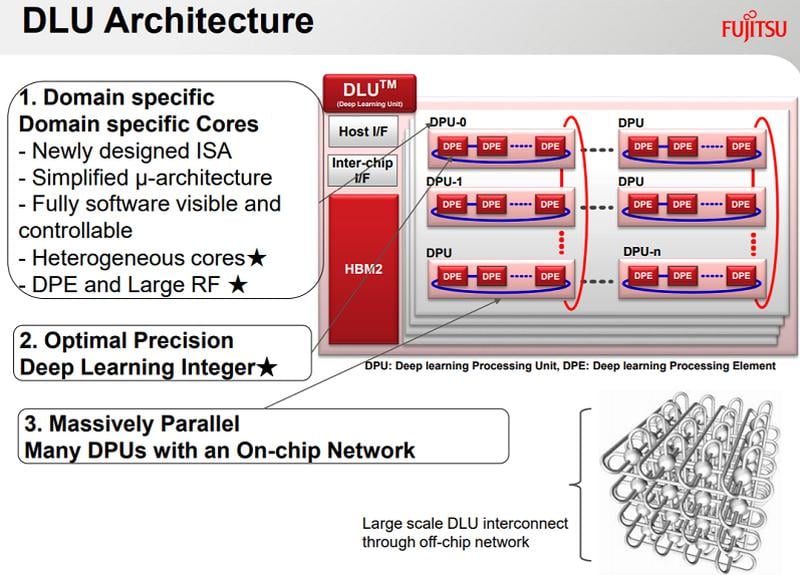
Optimalizace na úsporné 16bitové a 8bitové výpočty
Architektura jednotek DPU/DPE bude zřejmě zredukovaná jen na potřebné výpočetní operace, což sníží komplexitu a zvýší výkon a energetickou efektivitu. Tato specializace se bude týkat i datových typů, s nimiž procesor bude pracovat. Fujitstu ho navrhuje speciálně pro hodnoty s nižší přesností, které jsou pro strojové učení optimálnější. „Největším“ datovým typem bude FP32, tedy jednoduchá přesnost s plovoucí čárkou.
 DLU bude používat výpočty zejména s přesností FP16, INT8 a INT16
DLU bude používat výpočty zejména s přesností FP16, INT8 a INT16Pro výpočetní úlohy se ale bude používat zejména poloviční přesnost FP16, která by měla mít dvojnásobný výkon, a celočíselné hodnoty. DPU budou podporovat nejen 8bitové hodnoty INT8, ale také 16bitové INT16. Ty by měly být značně univerzálnější a při vhodném programování zvládnout řadu operací, kde by jinak kvůli přesnosti byly potřeba výpočty FP16. INT16 má větší přesnost než FP16, ale horší rozsah. Hlavní výhodou ale je, že výpočty s celočíselnými hodnotami by měly být rychlejší a méně energeticky náročné. Tím pádem by také měly umožňovat celkově vyšší výkon.

 Čip DLU je údajně ve vývoji minimálně dva roky a na trhu by se údajně mohl objevit příští rok. Přesněji mají tyto akcelerátory být uvedené během účetního roku 2018 firmy Fujitsu, což znamená mezi dubnem 2018 a březnem 2019. Mezitím by se u konkurence měly objevit novější generace čipů, ale Fujitsu slibuje, že nabídne až deset krát lepší poměr výkonu ke spotřebě, plus škálovatelnost na velmi velké systémy (a tedy velmi velké neuronové sítě). Jak úspěšná jeho architektura bude, ale samozřejmě ukáže až čas. Tyto produkty nebudou vůbec levné, vzhledem k zaměření Fujitsu na enterprise, superpočítače a „big iron“ servery. DLU asi bude k mání jen v jeho značkových serverech, nikoliv jako samostatný akcelerátor instalovatelný kdekoliv.
Čip DLU je údajně ve vývoji minimálně dva roky a na trhu by se údajně mohl objevit příští rok. Přesněji mají tyto akcelerátory být uvedené během účetního roku 2018 firmy Fujitsu, což znamená mezi dubnem 2018 a březnem 2019. Mezitím by se u konkurence měly objevit novější generace čipů, ale Fujitsu slibuje, že nabídne až deset krát lepší poměr výkonu ke spotřebě, plus škálovatelnost na velmi velké systémy (a tedy velmi velké neuronové sítě). Jak úspěšná jeho architektura bude, ale samozřejmě ukáže až čas. Tyto produkty nebudou vůbec levné, vzhledem k zaměření Fujitsu na enterprise, superpočítače a „big iron“ servery. DLU asi bude k mání jen v jeho značkových serverech, nikoliv jako samostatný akcelerátor instalovatelný kdekoliv.
Ve strojovém učení bude horko
Fujitsu není jediný hráč, který se do oboru AI kromě Nvidie chystá. Hned dvě želízka má Intel – Xeony Phi s architekturou Knights Mill uzpůsobenou pro strojové učení a speciální program ASIC čipů Lake Crest, získaný akvizicí firmy Nervana. Vlastní akcelerátory TPU vyvíjí i Google a výpočetní GPU pro AI už nabízí i AMD. V této oblasti tedy zřejmě zavládne čilá konkurence a vyzyvatelů asi časem ještě přibude. Neuronové sítě nepotřebují příliš náročnou mikroarchitekturu a měly by dobře sedět zjednodušeným, ale masivně paralelním specializovaným čipům navrženým na míru těmto operacím. Pozice Nvidie tak asi nebude tak bezpečná, jako v jiných aplikacích čipů GPU (jako jsou hry, profesionální grafika), kde jsou pro novou konkurenci mnohem vyšší bariéry.








































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU