OpenCL 2.0
Nová verze OpenCL zdá se částečně následuje vývoj architektury HSA, mnoho aktérů ostatně pracuje na obou projektech. OpenCL 2.0 jako stěžejní vylepšení přináší propojení paměťových prostorů grafického jádra či GPU a procesoru. Obojí bude pod OpenCL 2.0 používat sdílenou virtuální paměť s unifikovaným adresováním. To znamená, že jak kód běžící na CPU, tak kód běžící na GPU si mohou přímo předávat ukazatele a adresy.
OpenCL 2.0 také odstraní jednu z velkých slabin předchozích verzí, a to že veškerou práci musel grafickému čipu zadávat kód běžící na procesoru počítače. GPU si totiž neumělo samo přidělit nové úlohy (kernely). Pod OpenCL 2.0 to již možné bude, a zařízení již bude moci spouštět úlohy bez asistence. Jednak se tím sníží zátěž CPU, nutnost intervencí hostitelského systému ale také vytvářela významné úzké hrdlo výkonu. Spouštění úloh například mohlo u některého kódu zabrat tolik času, že se již vůbec nevyplatilo ho počítat na GPU.

OpenCL také ve verzi 2.0 dostane podporu pro některé obrazové formáty, které bude možné využít k přímému sdílení dat s kódem používajícím OpenGL (takže přes OpenCL budou moci běžet některé operace 3D grafiky). Vedle toho přináší nová specifikace i různé další vylepšení pro programátory. Jedním z nich je třeba podpora objektů typu roura (pipe). OpenCL 2.0 nabízí nově funkce pro čtení a zápis do rour.
Vedle toho by OpenCL 2.0 mohlo přinést lepší podporu v rámci operačního systému Android. Google totiž na této platformě OpenCL neimplementoval a tlačí vlastní API pro výpočty na GPU, pojmenované Renderscript. OpenCL 2.0 proto obsahuje rozšíření, umožňující vytvářet klientské ovladače, které lze do Androidu doinstalovat a pak používat v aplikacích.
![]()
Cuda 6
V podstatě současně (koncem minulého týdne) oznámila shodou okolností Nvidia zase novou generaci vlastního programovacího API pro výpočty na GPU, tedy frameworku Cuda. Ten se tak dostává na verzi 6. Zajímavé je, že hlavní novou funkcí je i v zelenám táboře unifikovaný paměťový prostor. V nové verzi bude programátor mít přístup jak k operační paměti systému, tak ke grafické paměti v rámci jediného adresního prostoru. Není tak již třeba explicitně řešit přesuny dat z jedné do druhé.
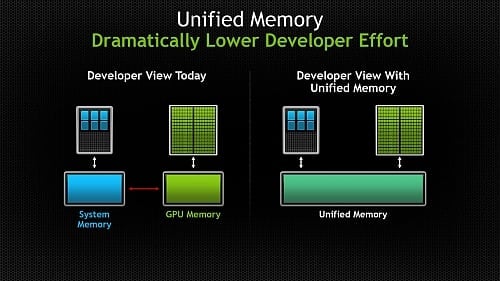
Tady je ale třeba poznamenat, že zásadní problém s pamětí spočívá v hardwaru. Tedy v tom, že grafická paměť je je oddělená od operační a všechna komunikace tedy nějak musí projít přes sběrnici PCI Express. To také způsobuje výkonnostní omezení (zejména co se týče latence přenosů), která pak trápí programy typu GPGPU. Nvidia neprodukuje APU či integrovaná GPU, takže pochopitelně ani nemůže nabídnou zařízení, která by pro GPU a CPU používala fyzicky unifikovanou paměť. Tedy pokud pomineme čipy Tegra.

Unifikovaná paměť ve frameworku Cuda 6 je tedy zejména funkcí, která zjednodušuje vývoj softwaru. O přenosy dat se již nebude muset starat programátor a může je nechat na ovladačích a překladačích. Možná si vzpomínáte, že unifikace paměti měla být jednou z novinek GPU architektury Maxwell. Dle Nvidie je ale tato funkce převážně softwarovou záležitostí, takže se jí podařilo zprovoznit ještě předtím. Maxwell má ale být pro tento model optimalizován na úrovni hardwaru, takže mu sdílení paměti s procesorem půjde lépe. Co přesně Nvidia pro zmírnění hardwarových omezení udělá a jak velký to bude mít efekt, ale teprve uvidíme.
Zdroje: Khronos Group, Bright Side Of News*, AnandTech










































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU