
O vnitřnostech Steamrolleru se na konferenci Hot Chips 2012 rozhovořil CTO společnosti, Mark Papermaster. Hned na začátek možná leckoho zklamal, jelikož novinka bude stále vycházet z konceptu Bulldozeru. Protentokrát však nechme předsudky stranou. O tom, jestli byla tato architektura historickým omylem, nakonec možná rozhodne právě to, co AMD předvede s „parním válcem“.
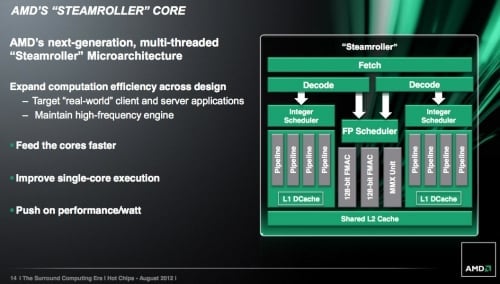
První a zřejmě nejradikálnější změnou je zdvojení instrukčních dekodérů celočíselné části. V každém modulu nyní budou dva (zpracovávající 4 instrukce za takt), vyhrazené pro každé z jader. Rychlost dekódování tak stoupne na dvojnásobek. V Bulldozeru a Piledriveru se obě jádra na dekodéru střídala po jednotlivých cyklech; zdvojení dekodérů tedy zřejmě odstraní kritickou brzdu ve výpočetním procesu. V mnoha případech by měl být výrazně eliminován propad výkonu při vytížení obou jader. Modul tak možná přestane být posměšně nazýván „jádrem s technologií HT“.
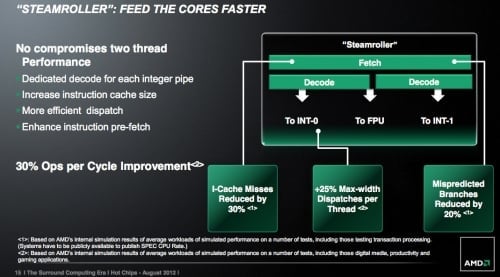
Dekódování se týká další potenciálně významné plus. Steamroller totiž údajně bude mít buffer pro již dekódováné instrukce (mělo by jít o analogii podobné „L0“ cache v procesorech Sandy Bridge a Ivy Bridge). Tento buffer umožňuje procesoru přeskočit opětovné dekódování instrukcí, pokud se hotový ekvivalent již nachází v tomto zásobníku. To může nastat při provádění smyček, či pokud se CPU zotavuje ze špatně předpovězené větve. Použití dříve dekódované instrukce ušetří nejen čas (čímž se zvedne výkon), ale také elektrickou energii, neboť dekodér nemusí znovu pracovat. To bude samozřejmě výhodné hlavně pro mobilní APU.
Samotné výpočetní jednotky zřejmě zůstávají stejné. Jejich výkon je ostatně u většiny architektur omezen schopností „frontendu“ je udržovat zaměstnané. A zde už AMD změny hlásí. Za prvé bude procesor najednou pracovat s větším počtem instrukcí, takže je bude moci efektivněji uspořádat a rozdělit mezi výpočetní jednotky (zlepšení údajně dosahuje 5-10 %). Vylepšena by měla být technika „store to load forwarding“, která umožňuje přeskočit načítání dat z paměti, pokud je na zdrojové místo procesor předtím zapsal (a má je tedy v paměti cache). Navíc bude zvětšen počet fyzických registrů procesoru, což ušetří nějaké přístupy do mezipaměti a s nimi spojené prodlevy.
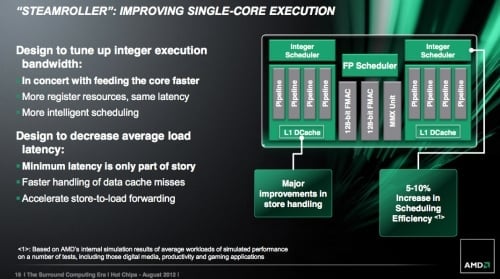
Výkon by mělo vylepšit i zvětšení instrukční L1 cache. AMD bohužel neuvádí novou velikost (Bulldozer měl 64 KB sdílených pro obě jádra v modulu). Nová cache má údajně o 30 % zredukovat počet případů, kdy procesor v mezipaměti nenajde potřebná data. Bohužel nezazněly žádné náznaky o zvýšení asociativity této mezipaměti, ani o změnách v poměrně malé datové L1 cache. Dost možná se zde tedy žádné úpravy nechystají.
Další změny AMD slibuje v přednačítání (prefetch) instrukcí. Vylepšen by údajně měl být i prediktor větvení, takž by počet chyb měl klesnout o 20 % (podotýkám ale, že úspěšnost v reálném provozu značně záleží na tom, jaký kód na CPU běží). Celkově AMD předpokládá nárůst výkonu při stejné frekvenci o zhruba 30 %. Toto číslo samozřejmě berte s rezervou, neboť marketing má vždy potřebu přikrášlovat. Údaj se nicméně má zakládat na simulovaných testech her, aplikací a multimediálních úloh (čímž se zřejmě míní kód s instrukcemi SIMD).
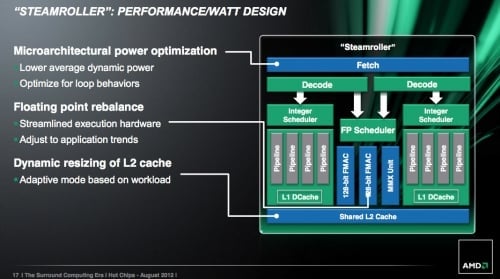
Některé z výše popsaných novinek se vedle lepšího výkonu zaměřují i na spotřebu procesoru. Tu hodlá AMD vylepšit dalšími cestami. Moduly budou moci vypínat části své L2 cache (v blocích po jedné čtvrtině). Tato technika by měla vylepšit spotřebu v klidu díky omezení úniků proudu. Stejný cíl bude mít i přepracování sdílené jednotky FPU. AMD se podařilo „zrecyklovat“ některé komponenty jednotek FMAC (ty provádějí výpočty v plovoucí řádové čárce) a sdílet je s jednotkami MMX, zpracovávajícími instrukce SIMD. Údajně to nebude mít vliv na výkon, ale celá FPU se díky tomu o něco zmenší a spotřebuje méně energie.

První várka detailů o Steamrolleru vypadá poměrně dobře. Nárůst IPC očividně nebude stačit na pokroky, které Intel udělal s architekturami Sandy Bridge a Ivy Bridge (a které ještě učiní v čipech Haswell). Pokud ho však AMD opět zkombinuje s výhodou v počtu jader, mohlo by se konkurenční postavení firmy o něco zlepšit. Nechci ovšem být přílišný optimista, protože AMD často pronásleduje jakási smůla. Verdikt nad Steamrollerem si tehdy nechme na dobu, kdy budou k dispozici reálné testy. Doufejme, že to bude spíše dříve než později a že nás tentokrát AMD potěší.
Zdroj: AnandTech










































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU