
Minulý týden se v hardwarové oblasti objevilo nečekané „vánoční překvapení“, když francouzský časopis Canard PC Hardware publikoval předčasně předrecenzi procesoru Ryzen – přesněji řečeno prototypu („ES“), který se mu dostal do rukou. Výsledky testu byly sice zprůměrované, což rafinovaně podnítilo zvědavost celkovými skóre, aniž bychom se dozvěděli výkon v konkrétních aplikacích (jak se říká, vlk se nažral, koza zůstala prakticky celá), ale i tak jsme se k poznání výkonu Ryzenu dostali zatím dosud nejblíž. Na webu se mezitím objevily lepší skeny časopisu a další podrobnosti, které nám informace ještě trošku rozhojní.
Latence pamětí cache vypadají
překvapivě dobře
Předně se porůznu objevily skeny
celého článku, které potěší ty, kdož vládnou francouzštinou
(viz například zde na Imgur,
pozor na přeházené stránkování). Canard PC v něm přináší
ještě například schéma jádra Zen, které ale není vlastně
ničím novým, bylo zveřejněno již během srpna při odhalení
architektury. Autoři si ale dali práci se změřením velmi
důležitých latencí mezipamětí cache, takže máme první
možnost si ověřit, zda AMD splnilo slib, že tento subsystém,
který byl u stavebních strojů stinnou stránkou, skutečně
dokázalo výrazně zlepšit.
Ačkoliv je určitá šance, že
softwarem měřené latence nemusí být z různých důvodů
přesné, výsledky Canard PC Hardware naznačují, že AMD by
tentokrát mohlo uspět, ačkoliv implementace cache byly jeho
slabinou téměř notoricky. Pokud to vezmeme popořádku, tak L1
cache by měla mít latenci 4–5 cyklů (test zřejmě nebyl
úplně průkazný, nebo hodnota není konstantní). Čtyři cykly
by byly na úrovni dnešního standardu, stejnou latenci má Haswell,
Skylake, i Bulldozer a spol. Uvidíme ale, jak na tom bude
propustnost, tu zatím známe jen teoretickou (2×128 bitů
load/1×128 bitů store). Kromě toho je ještě latence zdá se snížena, pokud přístup pochází z FPU/SIMD části procesoru, která funguje tak trochu jako vydělený koprocesor. Přístup z FPU podle měření odezvu prodlužuje o další 3 cykly (tedy na 7 až 8 cyklů).

Desktopový Zen, AMD Summit Ridge (vizualizace)
Zejména L2 cache by měla být
masivním rozdílem proti Bulldozeru. Podle Francouzů se vyplatilo
její zmenšení na 512 KB, což je sice dvojnásobek proti 256 KB
u Intelu, ale proti 2 MB u Bulldozeru mnohem méně.
Redukce spolu s dalšími architektonickými změnami dokázala
latenci srazit dramaticky z 20 cyklů na 12. U Skylake by
měl Intel mít stejnou hodnotu (Haswell však zřejmě měl jen 11
cyklů), což je pro AMD dobré vysvědčení, zvlášť když má
větší kapacitu. Nicméně opět teprve uvidíme, zda se při
praktickém použití neobjeví nějaké problémy s propustností,
asociativitou či jiné nectnosti, výkon srážející. Případně
zda architektura L2 nebude bránit škálování na vyšší
frekvence (zatímco v Skylake/Kaby Lake bude Intel příští
rok mít na trhu čip s 4,5GHz turbem bez přetaktování).
Zajímavá je L3 cache. Podle
francouzských měření má její latence dělat 35 cyklů, což by
bylo na úrovni Haswellu (34 cyklů), zatímco u Skylake Intel
asi kvůli sptotřebě či lepší škálovatelnosti poněkud zvolnil
na 44 cyklů, takže by na tom Ryzeny mohly být dokonce lépe.
Nevíme však, zda je toto minimální latence, či průměrná –
spíše asi to první. U Zenu by měla být přístupová doba
variabilní dle toho, do jaké části cache chcete – bloky
blízké jádru jsou dosažitelné rychleji, než ty patřící
k dalším jádrům. Kromě toho L3 cache není společná pro
celé osmijádro Summit Ridge (tvořící základ Ryzenu). Je
rozdělena na dvě 8MB poloviny, sdílené vždy mezi čtyřmi jádry
tvořícími s ní tzv. Core Complex. Do L3 cache vedlejšího
Core Complexu musí jádro přistupovat skrze koherentní propojovací
logiku čipu, což přinese výrazné zpoždění.
Opět také ještě neznáme reálně
naměřenou propustnost L3 cache, nízká latence ale budí docela
slušné naděje. Také by mohla znamenat značné zlepšení proti
pomalé L3 cache v Bulldozeru. Ten by snad měl být až někde
okolo výrazně horších 65 cyklů. Takto dlouhá latence patrně
pomáhala škálovat na vysoké takty, ale značně už škodila
celkové užitečnosti této mezipaměti.
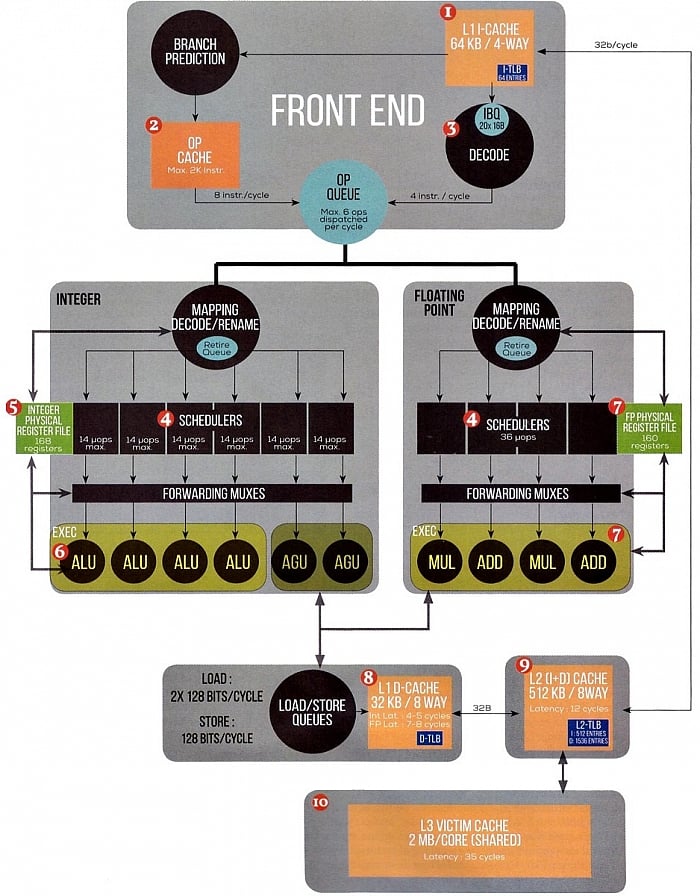
Schéma jádra Zen (Zdroj: Canard PC Hardware)
Závažná chyba při kombinaci
Micro-OP cache s SMT?
Mezi detaily, které Canard PC Hardware
sdělil, je i špatná zpráva. Implementace SMT je údajně
zatím postižená chybou. Respektive, problém se týká
„v současnosti dostupných vzorků“, jako byl ten, který
měli redaktoři k dispozici. Ty prý trpí chybou, pokud je
naráz použita Micro-OP cache (tedy L0, skladující již dekódované
instrukce, viz. článek
o architektuře Zen) a SMT, neboli zpracování dvou
vláken jedním jádrem za účelem zvýšení výkonu.
Redaktor časopisu bohužel neřekl,
v čem by tato chyba měla vězet. Při testech, z nichž
Canard PC Hardware uváděl benchmarky, bylo SMT aktivní, takže
zřejmě nebrání v základním fungování programů s plným
výkonem. Jenže údajně se jedná o „vážnou chybu“, což
by mohlo znamenat, že ovlivňuje (negativně, samozřejmě)
stabilitu nebo korektnost výsledků výpočtů. Ve finálním čipu
bude zřejmě nepřijatelná a AMD ji tedy bude muset do vydání
nějak vyřešit. Pokud se nepovede problém obejít nebo jej
nevyřeší nová revize/respin (pokud byl ES použitý francouzským
časopisem starší, mohla by se mezitím oprava stihnout), pak ale
AMD možná bude muset částečně vypnout některé části
postižených systémů, což by se asi projevilo zhoršením výkonu. Tuto situaci známe, v roce 2007 uškodila první sérii 65nm Phenomů s revizí B2 výrazně oprava chyby v TLB L2 cache (viz třeba recenzi Phenomu X4 9600 z tehdejší doby), která výrazně snížila výkon, byť výskyt chyby byl velmi vzácný.

Kompletní deaktivace SMT by masivně
uškodila vícevláknovému výkonu (SMT může odhadem přidávat
i 10–30 % celkové propustnosti operací v škálujících
úlohách). Pokud by AMD muselo vypnout Micro-OP cache, mohl by se
výkon podobně dramaticky zhoršit i v jednovláknové
zátěži, jelikož tato technologie je dle slov autorů architektury
Zen snad nejdůležitějším zlepšením ze všech použitých.
Navíc s ní asi většina návrhu počítá, takže by bez ní
celek fungoval neoptimálně.

Doufejme ale, že takto závažným
dopadům se AMD ubrání, inženýři mají s různými errata
v CPU dlouhou zkušenost a způsoby, jak se s nimi
vypořádat. Ani Canard PC Hardware nenaznačuje, že by ona chyba
byla pro Ryzen nějakou konečnou, takže je asi slušná šance, že
se do vydání všechno povede vyžehlit.
Zdroje: Imgur,
3DCenter.org,
Canard
PC Hardware (Twitter)








































