
Slajdy, které se přes víkend objevily na internetu, ukazují, že Knights Landing skutečně ponese jádra architektury odvozené od Silvermontu, jak psal web Heise Online. Pochopitelně ale budou muset projít značnými úpravami. Intel jim přidá podporu pro zpracovávání čtyř vláken naráz. Jejím smyslem je zřejmě hlavně to, aby mohly být vykonávací jednotky vždy plně vytíženy i tehdy, kdy procesor čeká na data z paměti a podobně. Zatímco Silvermont nepodporuje AVX, Knights Landing zřejmě bude, díky 512bitové vektorové jednotce, která bude tvořit hlavní výpočetní sílu celého čipu. Na rozdíl od dnešního Xeonu Phi ale 14nm čipy budou mít hned dvě tyto jednotky na jádro. Jádra se stejně jako v Atomech budou sdružovat do párů se sdílenou L2 cache.

Na čipu Knights Landing bude propojeno 36 dvoujádrových modulů
Knights Landing bude coby CPU skutečně plnohodnotným procesorem. Zatímco 22nm Xeon Phi potřebuje překompilovaný software, neboť nepodporuje žádná instrukční rozšíření architektury x86, Knights Landing poskytne plnou binární kompatibilitu s moderními procesory. Znamená to zřejmě všechna rozšíření typu MMX, SSE, AES a podobně a vektorová jednotka bude vedle sady AVX-512 zřejmě zvládat i AVX a AVX2. Podle prezentačních slajdů bude Xeon Phi navzájem plně kompatibilní s normálními Xeony; jedinou výjimkou bude rozšíření TSX (což je novinka architektury Haswell).
Výkon čipu má narůst víc než trojnásobně. Intel tímto slibuje teoretickou výpočetní kapacitu přes 3 TFLOPS při dvojité přesnosti (v jednoduché by to měl být dvojnásobek, vzhledem k tomu, jak SIMD instrukce fungují). Jednak počet jader naroste z 62 na 72 a zároveň dvě jednotky AVX-512 znamenají dvojnásobný maximální výkon. Určité zrychlení nepochybně vyplyne ze zvýšení pracovní frekvence. Nesmíme zapomínat ani na lepší skalární výkon jader při zpracovávání jednoho vlákna (i ten by proti zastaralé architektuře jader 22nm Knights Corneru měl vzrůst až trojnásobně). Přitom čipy budou mít nižší spotřebu: TDP má být 160–200 W podle modelu.
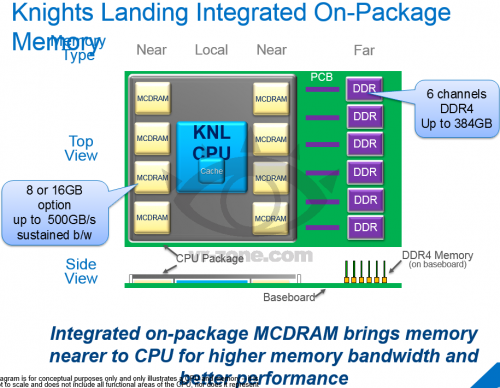
Slajdy k Xeonům Phi 14nm generace Knights Landing (VR-Zone): integrovaná paměť a DDR4
Uniklé slajdy také detailněji popisují paměťový subsystém čipů Knights Landing. Integrovaná paměť (označená MCDRAM) má čipu poskytovat propustnost až 500 GB/s a bude mít poměrně štědrou kapacitu – 8 nebo 16 GB. 8 GB je přitom tolik, kolik nesou na PCB současné karty Xeon Phi; modely s 16 GB GDDR5 nabídne Intel příští rok. Tato RAM přitom nebude hlavním paměťovým prostorem. 14nm Xeony Phi budou mít šestikanálový řadič DDR4 (celková šířka sběrnice tedy bude dělat 384 bitů), na který bude možno pověsit až 384 GB klasické paměti v modulech DIMM. Podporovaná efektivní frekvence DDR4 bude 2400 MHz. Kromě toho má Knights Landing také integrovaný řadič PCI Express 3.0 o 36 linkách.
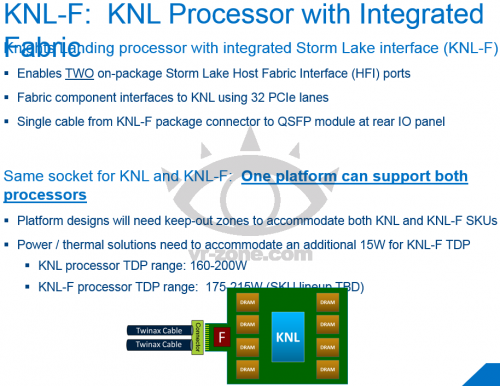
propojovací logika Storm Lake, volitelná součást čipů Knights Landing
Knights Landing bude hlavně záležitostí pro superpočítače. Těm Intel nabídne ještě jednu specialitu: integrovanou propojovací logiku pojmenovanou Storm Lake (což je možná ovoce technologie, kterou Intel před devatenácti měsíci koupil od společnosti Cray). Storm Lake bude propojení typu fabric, dostupné na některých verzích čipů. Ty budou používat stejný kompatibilní socket, nicméně čipy se Storm Lake budou mít o 15 W vyšší TDP (175–215 W). Modul Storm Lake má být interně připojen na sběrnici PCI Express 3.0, a to 32 linkami. Propojení uzlů se zbytkem systému se bude realizovat dvojicí kabelů, které se (pokud tomu dobře rozumím) budou zapojovat do portů přímo v pouzdru procesoru.
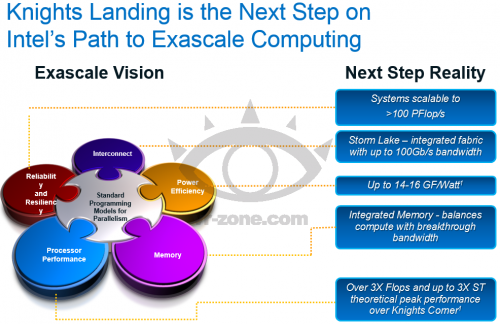
Slajdy k Xeonům Phi 14nm generace Knights Landing (VR-Zone)

Xeony Phi by mohly znamenat skutečně mnoho pro superpočítače a další nasazení, kde je třeba zejména hrubý aritmetický výkon. Není přitom až tak důležité, zda budou mít vyšší teoretickou výpočetní kapacitu než soudobá GPU (které nejspíš budou mít na papíře GFLOPS/TFLOPS více). Xeon Phi totiž bude mnohem snazší programovat a tedy z jeho teoretického potenciálu vyždímat praktický výkon. A za druhé již představuje vlastně celý uzel superpočítače, zatímco při použití GPGPU by v tandemu s výpočetními kartami musela běžet ještě i CPU Opteron či Xeon. 14nm Xeon Phi by tedy mohl vyhrávat i na spotřebu energie. A v neposlední řadě budou čipy Knights Landing schopny pracovat s nepoměrně větším paměťovým prostorem než výpočetní karty.
Zdroj: VR-Zone








































