










V posledních letech vydává ARM každý rok nové „big“ jádro pro mobily – loni Cortex-A77, o rok před tím Cortex-A76 a tak dále. Letos to bude trochu jiné. Vychází totiž další pokračovatel v této linii Cortex-A78, ale zároveň ještě jedno výkonnější jádro. Novinka Cortex-X1 otevírá nový o třídu vyšší výkonnostní segment a ARM se v této linii pouští za vyšším výkonem se širším jádrem. Pokud vám vadilo, že jádra ARM Cortex se zaměřují jenom na energetickou efektivitu a minimalizaci zabrané plochy na čipu a nekonkurují ve hrubém výkonu jádrům Apple, linie Cortex X jde přesně po tomto: výkonnější a „širší“ architektuře s vyšším IPC.
Cortex-A78: další zvýšení výkonu se štíhlým jádrem
Nejdříve se podíváme na Cortex-A78, jenž bude mainstreamovým jádrem, s nímž se asi budeme setkávat v největším počtu mobilních čipů. Jeho design vychází z linie Cortexu-A76 (2018) a následujícího Cortexu-A77, které vyvíjí americký tým v Austinu. Kódové označení je jinak Hercules.
Jádro má opět out-of-order architekturu s instrukční sadou ARMv8.2 a architektura je optimalizována na to, aby měla i poměrně vysoký výkon, ale aby to zůstáválo v rovnováze s malou plochou zabranou na čipu a nízkou spotřebou.
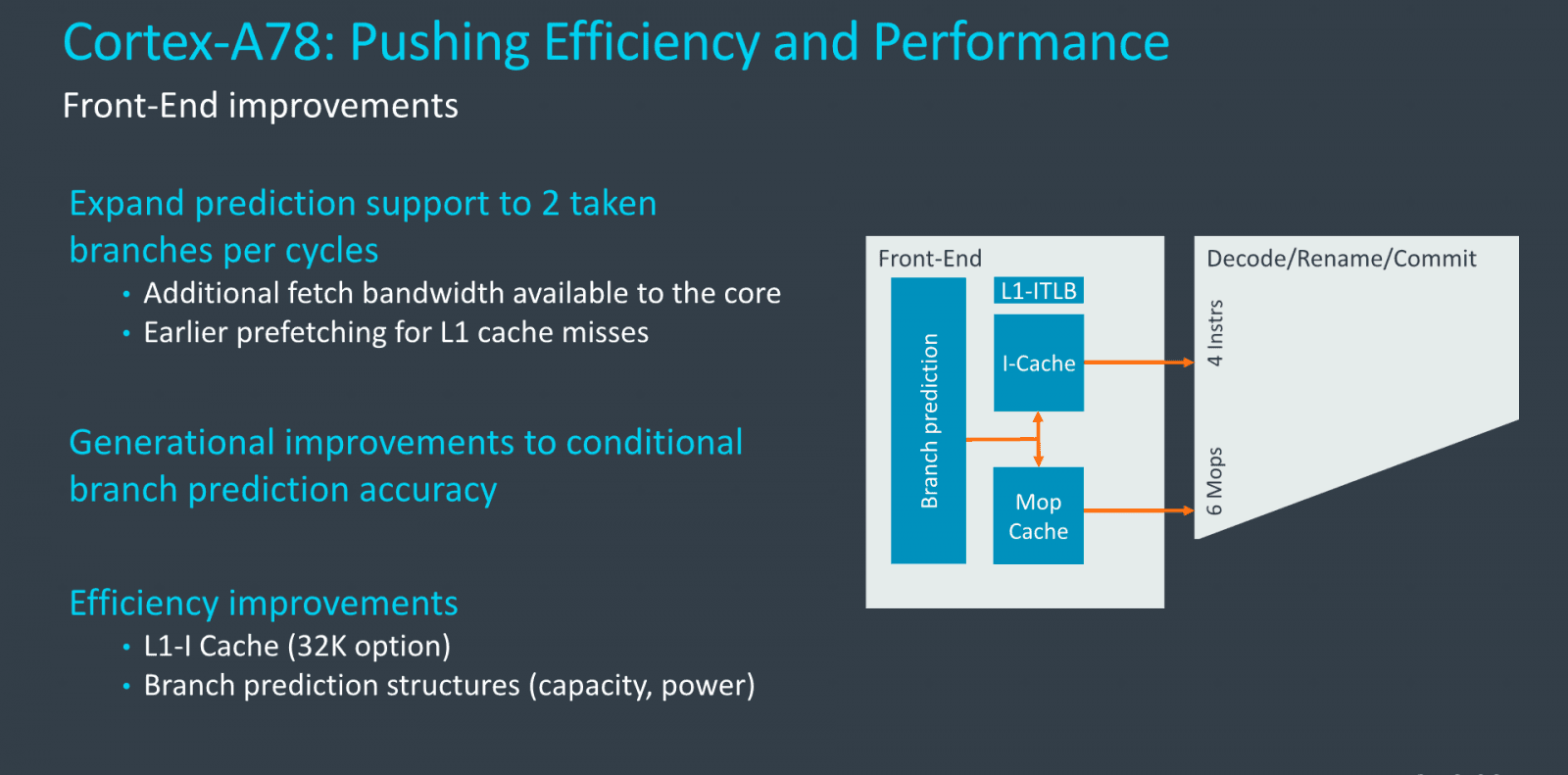
 Zlepšení proti A77 začínají v prediktoru větvení, který nyní dokáže zpracovat dvě větvení za takt místo jednoho (a pravděpodobně bude mít i lepší úspěšnost). Podobně mají být zlepšené prefetchery, které jsou opět schopné o něco úspěšněji odhadnout, jaká data bude program potřebovat.
Zlepšení proti A77 začínají v prediktoru větvení, který nyní dokáže zpracovat dvě větvení za takt místo jednoho (a pravděpodobně bude mít i lepší úspěšnost). Podobně mají být zlepšené prefetchery, které jsou opět schopné o něco úspěšněji odhadnout, jaká data bude program potřebovat.
 Mnohé úpravy byly provedeny ne pro výkon, ale pro vyšší energetickou efektivitu (zmenšení některých struktur v prediktoru). Pro zákazníky, kteří chtějí úspornější a menší jádro, je nyní dostupná volitelná možnost zmenšit L1 cache pro instrukce i data, z 64+64 na 32+32 KB (asi je možné zmenšit i jen jednu z nich).
Mnohé úpravy byly provedeny ne pro výkon, ale pro vyšší energetickou efektivitu (zmenšení některých struktur v prediktoru). Pro zákazníky, kteří chtějí úspornější a menší jádro, je nyní dostupná volitelná možnost zmenšit L1 cache pro instrukce i data, z 64+64 na 32+32 KB (asi je možné zmenšit i jen jednu z nich).
 Velkou inovací jádra A77 byla uOP cache (respektive, ARM jí říká mOP/macroOP cache) která ukládá už dekódované instrukce. To umožňuje obejít dekódování například ve velké části operací. Její velikost byla zachována v kapacitě 1500 macroOPů. Také kapacita dekodérů (4 instrukce/takt) zůstává, mOP cache dokáže produkovat 6 mOPů za takt, což je opět beze změny.
Velkou inovací jádra A77 byla uOP cache (respektive, ARM jí říká mOP/macroOP cache) která ukládá už dekódované instrukce. To umožňuje obejít dekódování například ve velké části operací. Její velikost byla zachována v kapacitě 1500 macroOPů. Také kapacita dekodérů (4 instrukce/takt) zůstává, mOP cache dokáže produkovat 6 mOPů za takt, což je opět beze změny.
Stejné počty jednotek, ale přepracované pro větší efektivitu
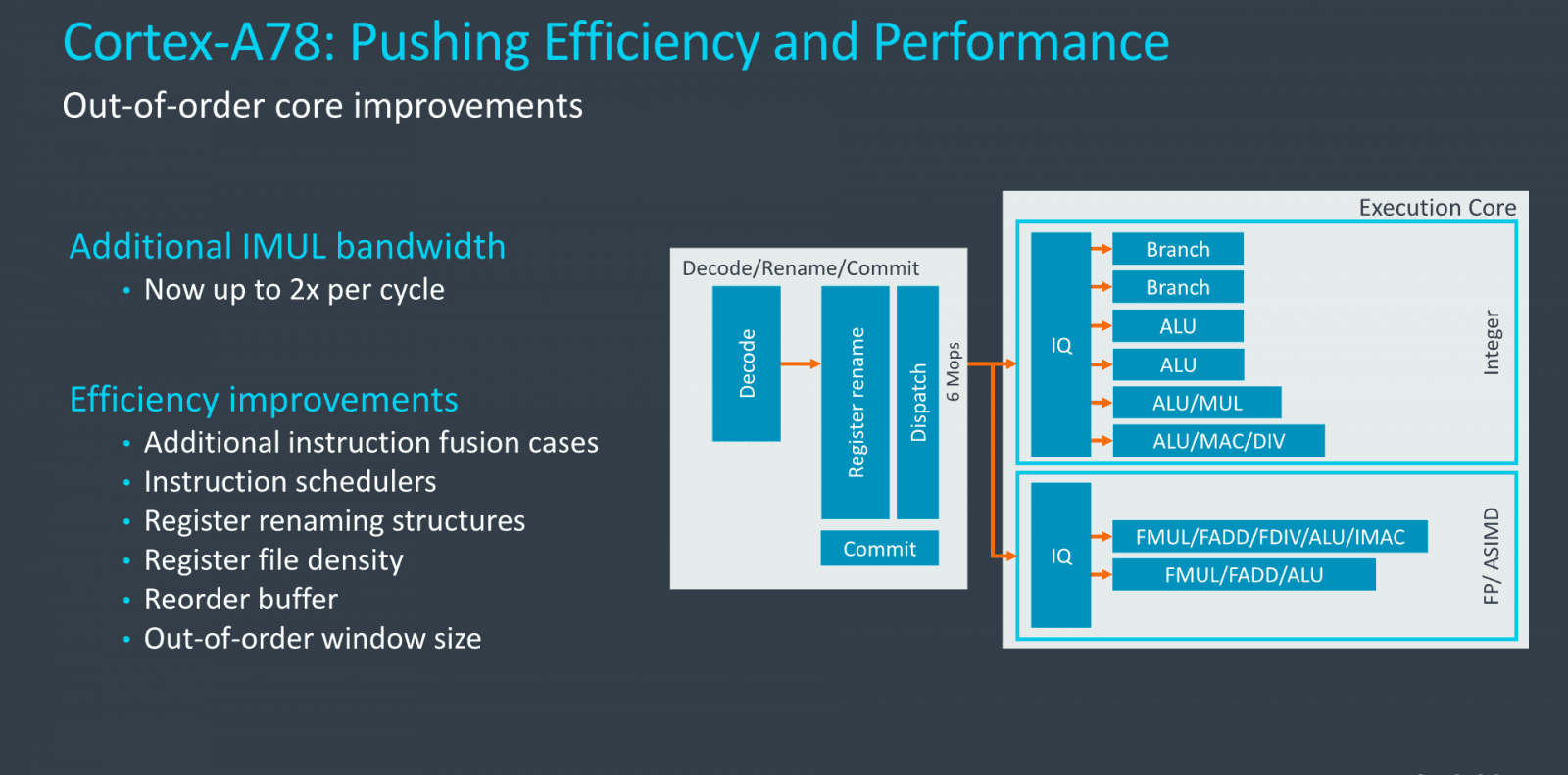
Výpočetní backend má čtyři ALU, dvě jednotky pro větvení a FPU/SIMD část má dvě 128bitové pipeline pro instrukce NEON – výkonnější SIMD instrukční sada SVE/SVE2 ještě podporována není, nicméně toto by prý možná mohla změnit následující architektura příští rok. Ta podle různých drbů už má být s instrukční sadou ARMv9, jež prý odstraní 32bitový režim a bude v základu obsahovat SVE2.
 Počty jednotek nechal ARM Cortex A78 stejné
Počty jednotek nechal ARM Cortex A78 stejnéJedna z mála změn v počtu (přesněji ale schopnostech) jednotek je, že celočíselné násobení podporují dvě ALU místo jen jedné. Dvě ALU jsou jednoduché, třetí má navíc i násobičku, čtvrtá je už plná MAC (tj, také s podporou násobení) a také podporuje dělení.
Posílené Load/Store
Load/Store část jádra pro operace s pamětí je ale už posílená. Cortex-A77 měl dvě AGU provádějící jak čtení, tak zápis. Architektura A78 přidává třetí, která je určená čistě pro čtení. A78 tedy zvládne tři čtení za takt (nebo třeba jedno čtení, dva zápisy). Pro srovnání: Intel Ice Lake (Sunny Cove) má čtyři pipeline, umožňující dvě čtení a dvě dva zápisy za cyklus, AMD Zen 2 umožňuje dvě čtení a jeden zápis za jeden cyklus.
Také je zvýšená kapacita přenosu mezi Load jednotkami a L1 datovou cache, z níž čtou: z 16 bajtů za takt na 32 bajtů. Zdvojnásobila se také kapacita mezi L1 a L2 cache, ale u L2 cache byl TLB zmenšen ze 1280 na 1024 stránek, opěr kompromis pro lepší efektivitu. L2 cache je 512KB.
 Out-of-order fronty podobné jako loni, někde i menší
Out-of-order fronty podobné jako loni, někde i menší

Reorder Buffer má stejnou kapacitu 160 instrukcí, design se opět soustředil na zvýšení jeho efektivity. Celkové „okno“ out-of-order vykonávání kódu bylo ale dokonce menší proti A77 (některé další fronty se zkrátily), protože jeho zvětšování údajně není tak efektivní a cílem byla co nejvyšší efektivita.
ARM v jádru provedl změny na nižší úrovni, kdy se různě zvyšuje efektivita, například issue fronty mají mít výrazně lepší spotřebu. Fyzický soubor registrů má také efektivnější návrh, takže potřebuje méně místa při stejných schopnostech. Více operací nyní může procesorem jít sfůzovaných dohromady, takže se ze stejného počtu jednotek a hloubky front vydře více reálného výkonu
Tato jádra jsou navržená pro kombinaci s propojovací logikou DynamiQ jako předchozí a stále se budou používat v (až) čtyřjádrových klastrech, které mohou mít 512 KB až 4MB L3 cache. Těchto klastrů pak může být v čipu více, nebo mohou další klastry být tvořené jinými jádry (in-order Cortex-A55) v big.LITTLE čipech.
Článek pokračuje na další stránce.
IPC vyšší o 4–7%, ale vyšší takty v 5nm čipech
Celkově tedy toto jádro vypadá jako poměrně mírná změna proti A77, což ale dává smysl proto, že A77 bylo větší přepracování a další podobná revoluce asi bude příště. A současně si ARM nechal přidávání jednotek pro vyšší výkon do druhého jádra X1, což umožnilo se u A78 více specializovat právě jen na vyšší účinnost.
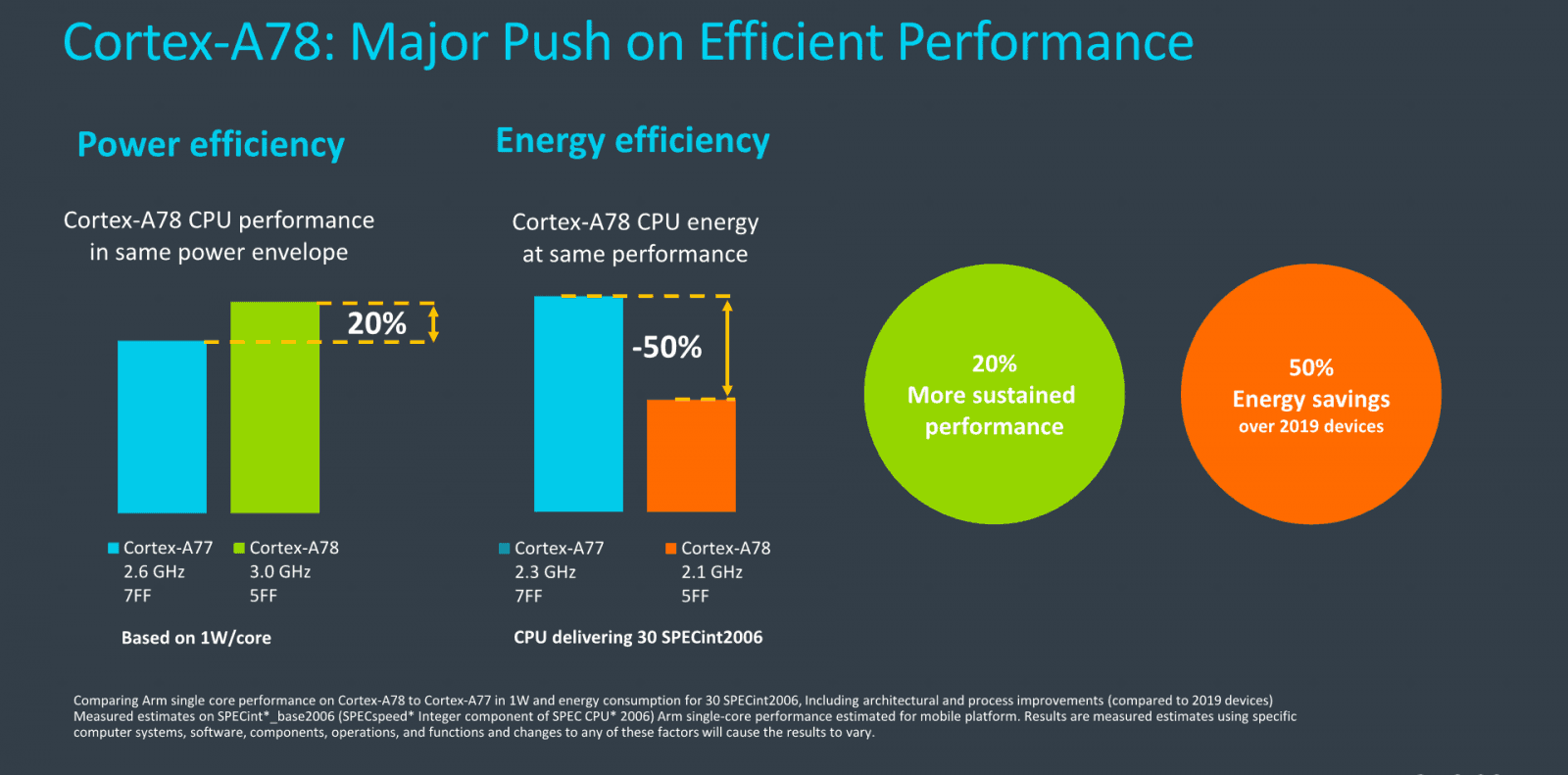
ARM uvádí, že Cortex-A78 by měl být schopen i při své menší velikosti zlepšit výkon až o 20 % proti Cortexu-A77, ale toto není zvýšení IPC. ARM uvádí, že jde o srovnání mezi těmito dvěma jádry při 1W spotřebě. Cortex-A77 má v takovém případě běžet jen na 2,6 GHz, kdežto Cortex-A78 už zvládne 3,0 GHz. Z toho by vycházelo, že IPC bude asi o 4 % vyšší, ovšem na jiném místě uvádí ARM zlepšení o 7 %.
 ARM Cortex A78 má dosahovat až o 20 % lepší výkon než A77
ARM Cortex A78 má dosahovat až o 20 % lepší výkon než A77Zvlášť na 5nm procesu by mobilní čipy měly s touto architekturou dosahovat vyšší takty – možná se dostanou i na ty 3 GHz. To teoreticky zvládne i A77, ale reálné čipy takto vysoko nešly.
Cortex-A78 údajně umožňuje při taktu 2,1 GHz dosáhnout stejný výkon jako A77 na 2,3 GHz a přitom mít poloviční spotřebu. Ovšem pozor – obě tato srovnání jsou v benchmarku SPECint2006, takže výkon v jiných může být trošku jiný.
Uváděná zlepšení výkonu a efektivitu zahrnují i zlepšení z 5m výroby
A vůbec největší háček je v tom, že v těchto srovnáních ARM počítá s tím, že Cortex-A77 je vyráběný na 7nm procesu TSMC (7FF), kdežto pro Cortex-A78 už se v těchto projekcích uvažuje 5nm proces (5FF). Takže tyto uváděné přínosy nejsou čistě architektura, je v nich započítáno i zlepšení, které dodá nový proces. Což je dost podstatné.
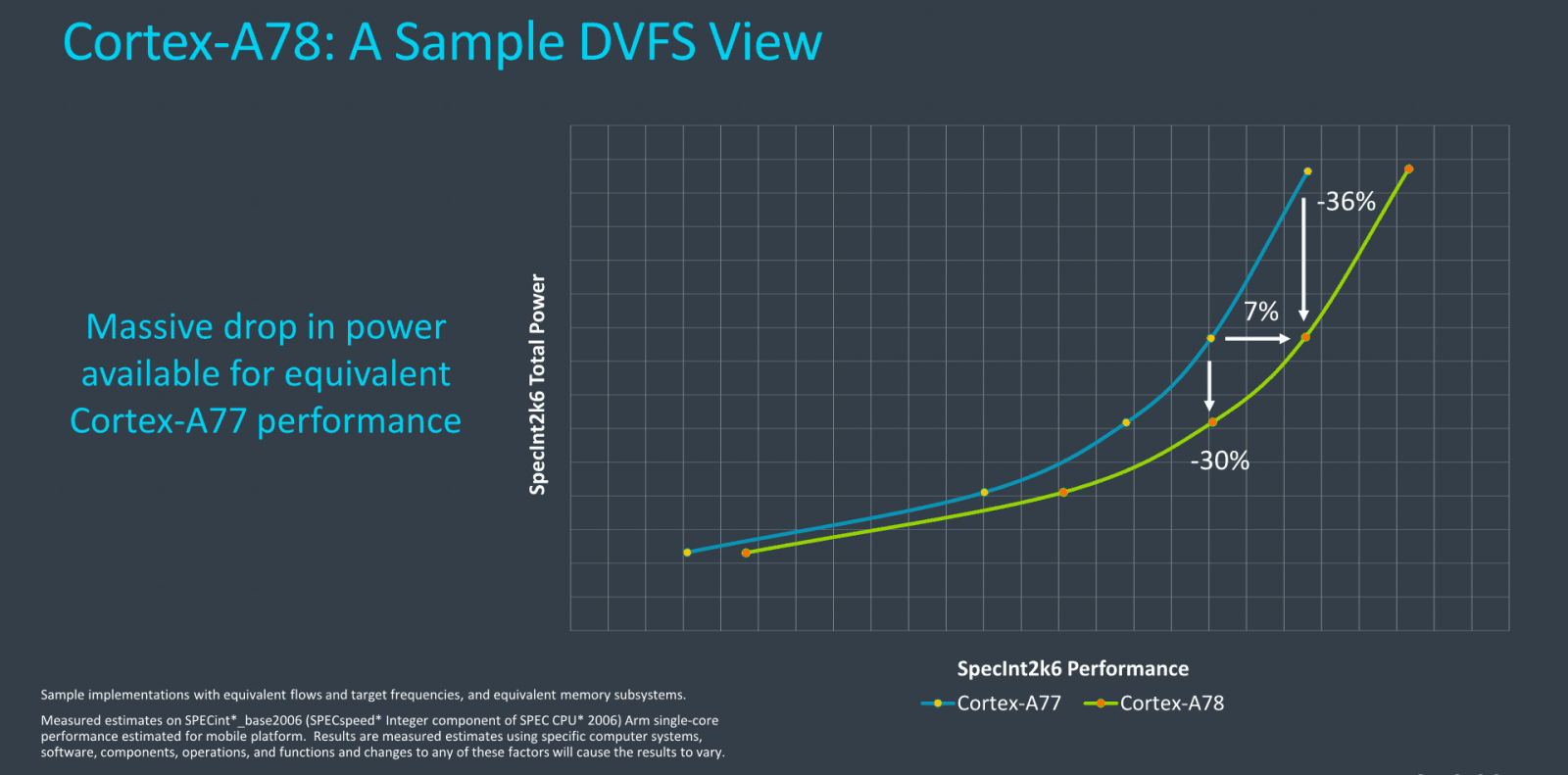
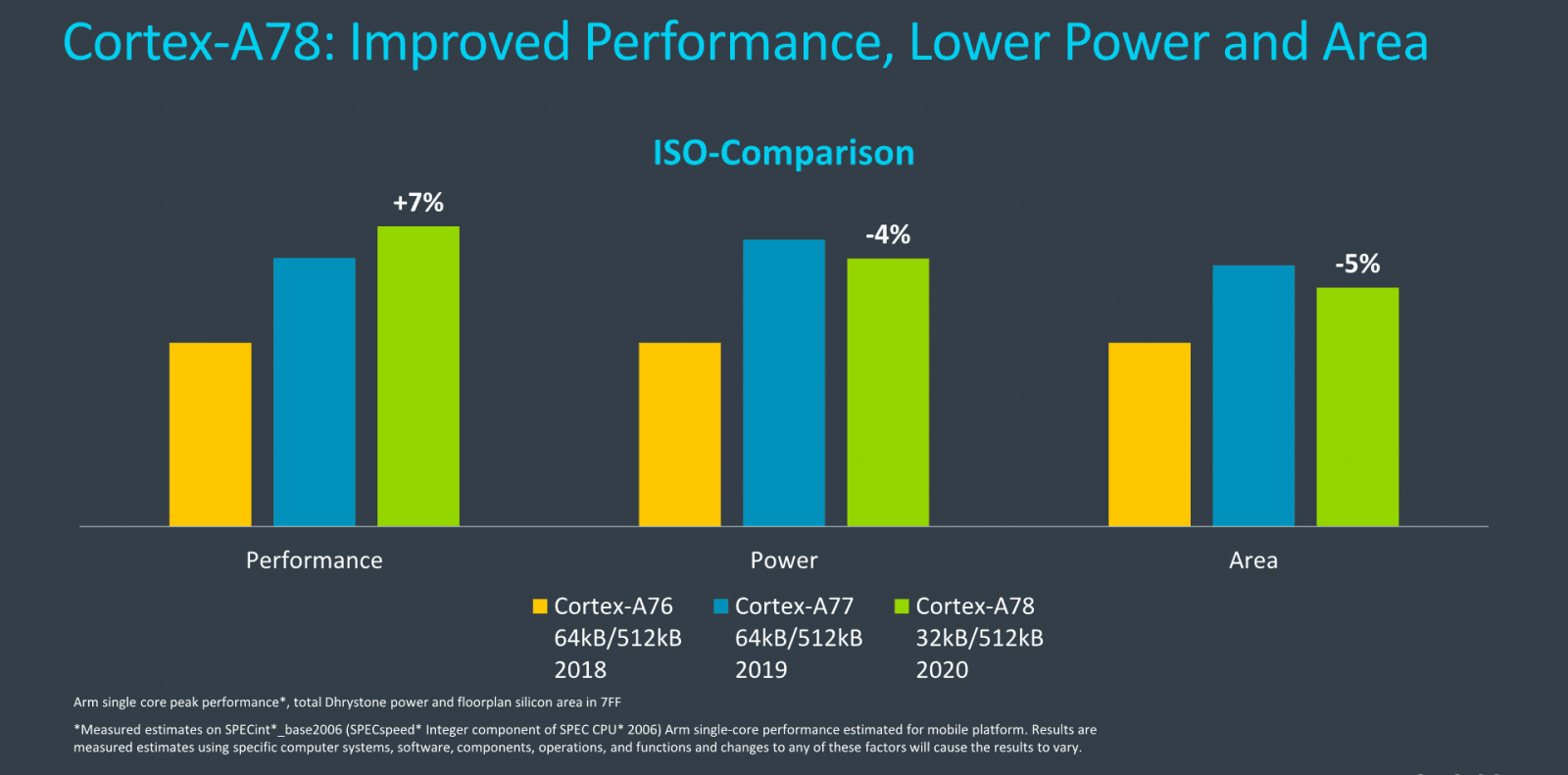
 Tyto grafy srovnávají výkon, spotřebu a plochu jádra ARM Cortex A78 s předchůdci na stejném 7nm procesu a při stejné frekvenci 3,0 GHz
Tyto grafy srovnávají výkon, spotřebu a plochu jádra ARM Cortex A78 s předchůdci na stejném 7nm procesu a při stejné frekvenci 3,0 GHzARM uvádí také čísla pro obě jádra vyráběná na procesu 7FF. V takovém případě má být výkon A78 lepší až o 7 % (nevíme, zda se liší frekvence), spotřeba o 4 % nižší (ta je ve Dhrystone, ne ve SPECint2006) a plocha o 5 % menší. Ovšem toto srovnání je mezi Cortexem-A77 s kapacitami L1 cache na 64 KB a Cortexem-A78 se 32KB kapacitami. Pokud by novější jádro nemělo volitelné menší cache, asi by mělo větší velikost a spotřebu, ale také výkon.
ARM jako obvykle toto jádro oficiálně oznamuje v předstihu před reálným hardwarem, ale klienti ho měli pod NDA k dispozici delší dobu. První procesory by tedy měly být oznámeny letos a od přelomu roku už by se toto jádro mělo začít objevovat v prvních telefonech – bude to tedy produkt zejména pro rok 2021.
Článek pokračuje na další stránce.
Cortex-X1: ARM leze do o kategorii vyššího zelí nyní patřícího jen Applu
Mainstreamové Cortexy A76, A77 a A78 jsou štíhlejší jádra než třeba architektury M3 a M4 Samsungu a jádra Apple. Bývá to vnímáno jako deficit, který mají ARM procesory pro telefony s Androidem proti telefonům od Applu. Ale ves kutečnosti tento rozdíl v absolutním výkonu nikdy asi nebyl jen v tom, že má Apple víc peněz na výkon a/nebo lepší inženýry, i když finanční faktor přítomen asi také bude.
Apple prodává celé telefony a v průměru má asi ze všech výrobců nejvyšší ceny a výdělky na jedno zařízení. Čipy si navrhuje sám a nese cenu jen za vyrobené wafery. Ale ta se v mnohasetdolarové částce celkem ztrácí – výrobní náklady samotného procesoru tedy mohou být výrazně vyšší, než co je jinak únosné.
 Naproti tomu firmy jako Qualcomm a MediaTek prodávají samotné čipy výrobcům telefonů a musí si konkurovat cenou. Kvůli tomu jsou pod tlakem mít čip co nejmenší, protože pokud by zdražili, levnější konkurent je může podtrhnout. Kvůli tomuto se na ploše jader ve většině čipů spíše šetří a ARM Holdings musí respektovat tuto poptávku. Menší jádra ARM Cortex také typicky mají zátěžový příkon až poloviční proti jádrům Applu. I toto dovoluje zlevnit celkový návrh.
Naproti tomu firmy jako Qualcomm a MediaTek prodávají samotné čipy výrobcům telefonů a musí si konkurovat cenou. Kvůli tomu jsou pod tlakem mít čip co nejmenší, protože pokud by zdražili, levnější konkurent je může podtrhnout. Kvůli tomuto se na ploše jader ve většině čipů spíše šetří a ARM Holdings musí respektovat tuto poptávku. Menší jádra ARM Cortex také typicky mají zátěžový příkon až poloviční proti jádrům Applu. I toto dovoluje zlevnit celkový návrh.
Proto byla jádra Cortex dosud vždy menší a ač měly poslední Cortexy stejný nebo teď už i lepší výkon na 1 W proti Applu, absolutní výkon byl vždy nižší. Ovšem s Cortexem-X1 přináší ARM Holdings další architekturu, která přinese výkonnější jádro, jehož roli z výše uvedených důvodů Cortexy řady A nehrály.
 Slajdy k vydání architektury ARM Cortex-X1
Slajdy k vydání architektury ARM Cortex-X1Umožněno je to tím, že linie X asi bude mít sekundární použití v serverech (coby architektura Neoverse). a vedle toho také tím, že ARM využívá stavební prvky z menšího jádra A78 a buduje z nich příbuzné IP. Tím se ušetří náklady, stejný tým v podstatě pracoval na jádru X1 zároveň s jádrem A78. U tohoto jádra umožnilo „rozštěpení“ udělat změny, které třeba pomáhají efektivitě na úkor výkonu. U jádra X1 je to naopak – díky tomu, že existuje i A78, může Cortex-X1 dělat změny, které efektivitě ubližují v zájmu výkonu.
Cortex-X1 alias Hera
Mimochodem, kódové označení jádra X1 je Hera, tedy Herkulova nevlastní matka, která mu ráda znepříjemňovala život (trošku nám tu hapruje jazyk, Hercules je latinská podoba jména Hérakles, Héra zase řecká, latinsky by mělo být Juno, což už ale ARM dřív použil pro vývojovou desku platformy ARMv8).
Širší jádro
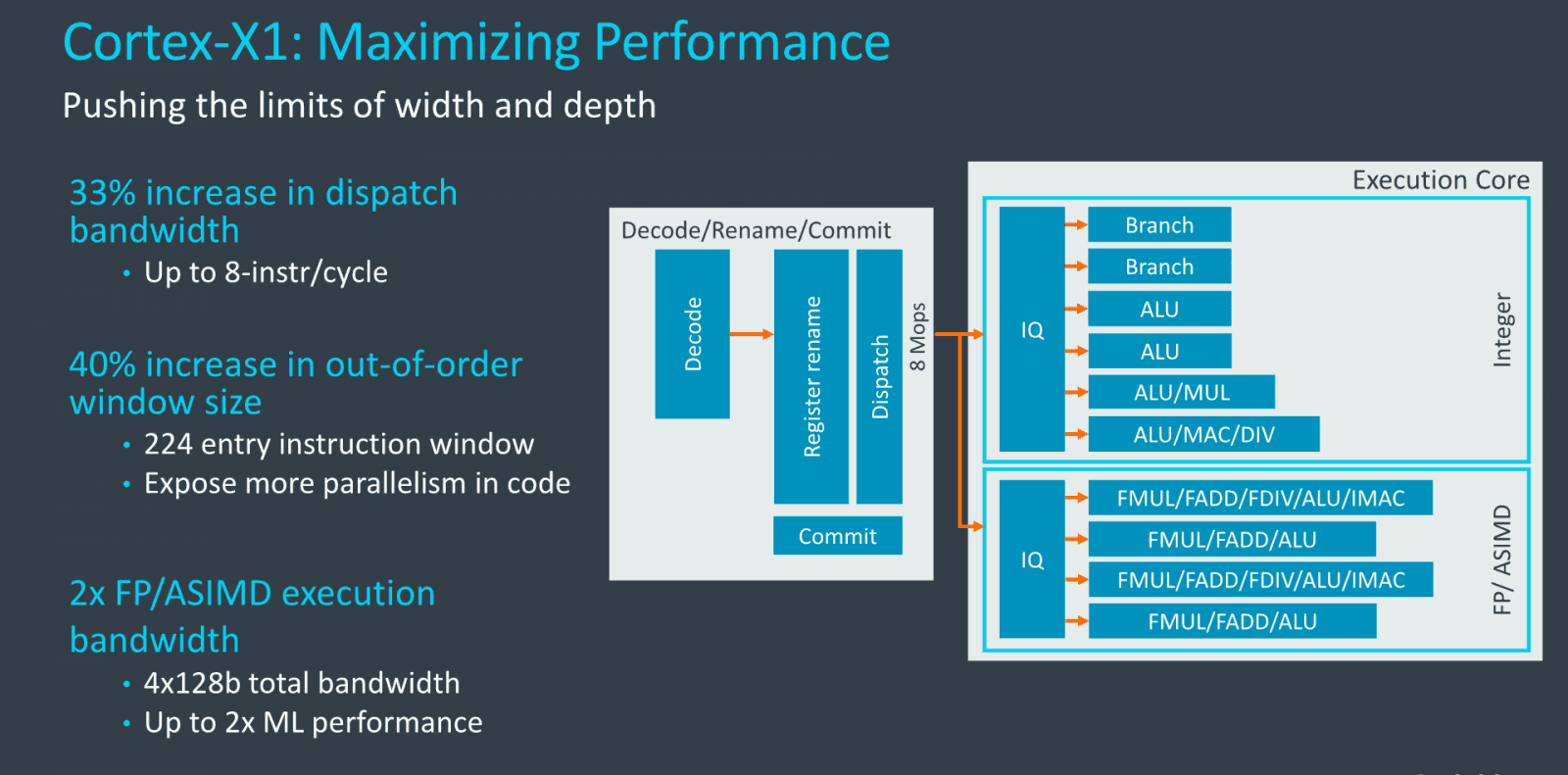
Cortex-X1 podporuje stejnou generaci instrukční sady(ARMv8.2) jako A78, jelikož mají stejné základy, ale představuje celkově širší architekturu. Začíná to u dekodérů, kterých je pět místo čtyř a dokáží tedy zpracovat pět instrukcí za takt. A jeho mOP cache dokáže poslat k dalšímu zpracování až osm dekódovaných macroOPů místo šesti za cyklus. Pokud tedy procesor jede jenom z mOP cache, dokáže zpracovávat osm instrukcí za takt.
 Srovnání architektury ARM Cortex-X1 a Cortex-A78
Srovnání architektury ARM Cortex-X1 a Cortex-A78mOP cache je také zvětšená na dvojnásobnou kapacitu, což by mělo mít přímý dopad na IPC. Podobnou operaci provedl také Zen 2, kde ale muselo AMD současně zmenšit tradiční L1 pro kód, což ARM neudělal. Kapacita mOP cache je 3000 instrukcí, což je méně než u Zenu 2 (4000) ale víc než u Intelu – jeho Ice Lake/Sunny Cove má „jen“ 2250 položek, Skylake má 1500. Zvětšený je proti Cortexu-A77/A78 také L0 BTB (branch target buffer) ze 64 na 96 položek.
Podobně jako z mOP cache může proudit až osm instrukcí za takt, lze tento počet operací zpracovat také ve fázi přejmenování registrů a dispatch. „Okno“, v kterém se provádí přehazování operací při out-of-order vykonávání instrukcí, je výrazně větší než u Cortexu A78 – ze 160 instrukcí se nafouklo na 224.
Toto by mělo přímo zvyšovat IPC. A současně jde o jednu z věcí, kde bylo třeba obětovat maximální efektivitu – proto dosud Cortexy držely kratší fronty proti třeba x86 procesorům. Také LSU pipeline mají údajně o třetinu větší okno pro optimalizaci I/O.
 ALU pořád jen čtyři, ale výkon FPU se zdvojnásobil
ALU pořád jen čtyři, ale výkon FPU se zdvojnásobil

Kde kupodivu rozšíření nenastalo, je u hlavního výpočetního backendu, kde zůstaly stále stejné čtyři ALU, místo aby ARM třeba zvýšil počet na šest. Opět jsou dvě jednoduché, dvě zvládající násobení (z nich jedna umí i dělení). K tomu dvě jednotky pro větvení, jako u Cortexu A78. Také tři AGU jsou stejné.
 Slajdy k vydání architektury ARM Cortex-X1: schéma jádra a vykonávacích jednotek
Slajdy k vydání architektury ARM Cortex-X1: schéma jádra a vykonávacích jednotekOvšem velké posílení nastalo v FPU/SIMD výkonu, který byl dosud slabým místem jader ARM Cortex. Cortexy A76, A77 a A78 mají dvě jednotky pro SIMD operace Neon. Ve floating point operacích mají šířku 128 bitů jako operace SSE u x86 (ale podle některých informací je pro snad celočíselné operace výkon poloviční, což by efektivně dávalo 64 bitů jako u MMX). Dnešní Intely a AMD mají mnohem vyšší SIMD výkon.
U Cortexu-X1 to ARM změnil a tyto dvě pipeline v podstatě sakumprásk zkopíroval a přidal ještě jednou (včetně mixu instrukcí, které umí). Díky tomu má X1 čtyři pipeline pro Neon a propustnost těchto SIMD výpočtů může být až dvojnásobná. Měla by asi být podobná jako u architektury AMD Zen (předtím, než Zen 2 rozšířil jednotky na 256 bitů).
Dvojnásobné cache
Další oblast, kde se zvyšuje výkon, jsou cache. U L1 jsou kapacity 64+64 KB už bez 32KB varianty. Datová L1 je zde ale složená ze dvojnásobku banků a poskytuje dvojnásobnou propustnost. L2 cache (ta je vyhrazená pro jádro) byla zvětšená z 512 KB na 1 MB. A také sdílená L3 cache je dvojnásobná – skýtá už 8 MB.
 L2 nabízí také dvojnásobnou propustnost. Ovšem zároveň je u ní dosažená velmi nízká latence jen 10 cyklů. Přitom srovnatelná 1MB L2 cache u ARM jádra Neoverse N1 pro servery měla latenci 11 cyklů). Zatímco Cortex-A78 zmenšil L2 TLB, zde byl naopak zvětšen na 2048 stránek.
L2 nabízí také dvojnásobnou propustnost. Ovšem zároveň je u ní dosažená velmi nízká latence jen 10 cyklů. Přitom srovnatelná 1MB L2 cache u ARM jádra Neoverse N1 pro servery měla latenci 11 cyklů). Zatímco Cortex-A78 zmenšil L2 TLB, zde byl naopak zvětšen na 2048 stránek.
Cortex X1 má ale stále krátkou 13stupňovou pipeline, která je stavěná na vysoké IPC díky malým postihům za neodhadnuté větvení (10 cyklů). Toto je něco, co se nedalo v rámci společného vývoje s Cortexem-A78 asi změnit a bude to limitovat výkon architektury X1. Takováto optimalizace na krátkou pipeline totiž snižuje dosažitelné frekvence. Cortex-X1 bude tak asi mít podobné maximální takty a v praxi se asi budou nejrychlejší implementace pohybovat pořád okolo 3 GHz.
Článek pokračuje na další stránce.
IPC lepší až o 30 % (proti minulé generaci)
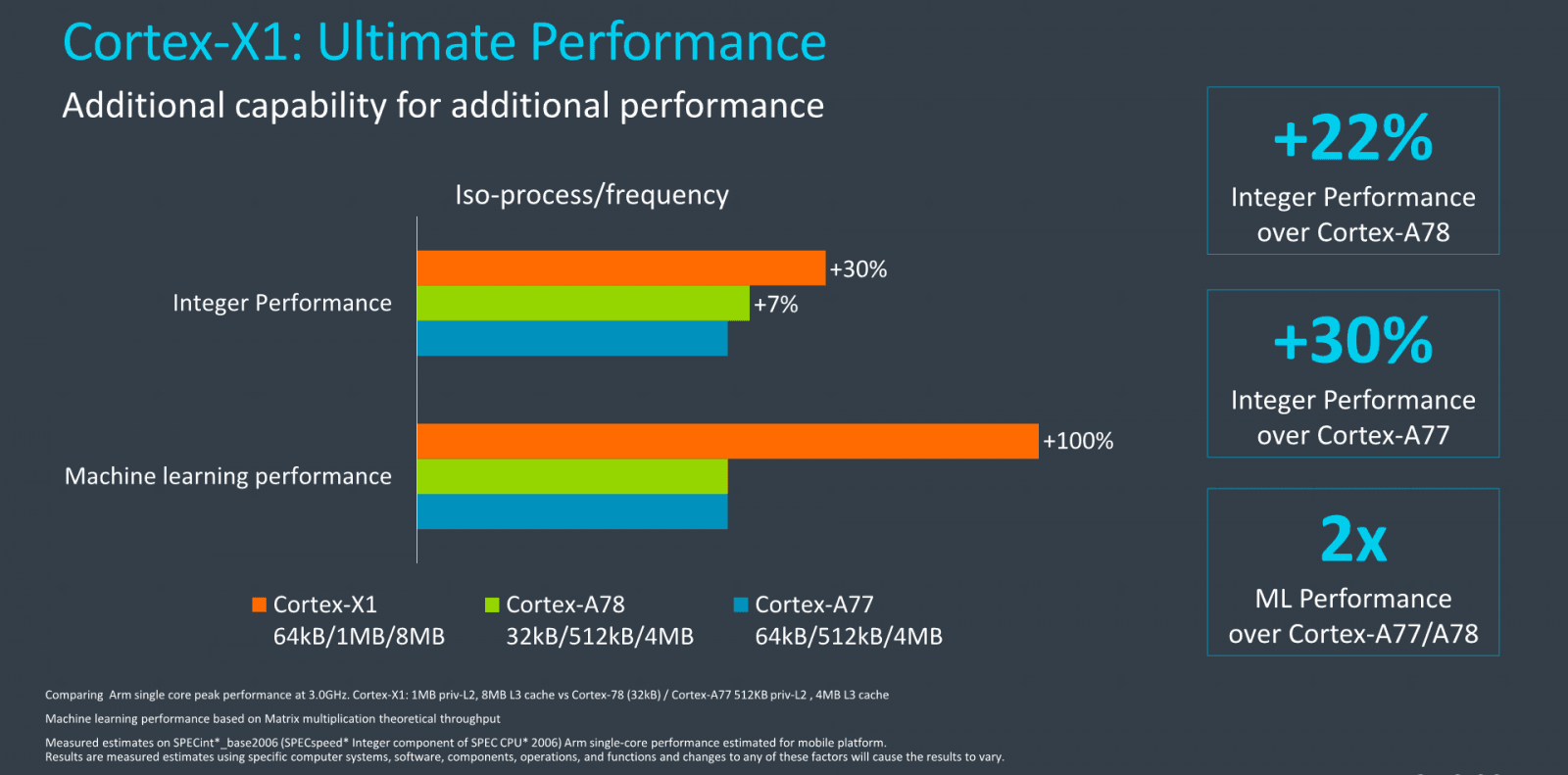
V případě Cortexu-X1 už ARM opravdu uvádí, že přímo IPC vzroste o 30 % proti loňskému Cortexu A77, toto je již bez vlivu výrobního procesu a frekvence, s oběma jádry na 3,0 GHz. Součástí tohoto nárůstu IPC je i vliv větší L2 a L3 cache, kterou však A77 mít nemůže, takže je to víc než fér.
V tomto srovnání má mít Cortex-A78 IPC o 7 %, vyšší, což by implikovalo, že Cortex-X1 by mohl mít o 21,5 % vyšší IPC, ovšem pokud by A78 mělo 64KB L1 (zde mělo 32KB), byl by rozdíl menší. Toto byla jinak čísla pro celočíselný kód SPECint2006, ale ve SPECfp2006 je to prý stejné. Na svém webu uvádí ARM, že „integer“ výkon je o 22 % vyšší než u Cortexu A78.
 Slajdy k vydání architektury ARM Cortex-X1: v SPEC2006 má být IPC až o 30 % lepší, než měl Cortex-A77
Slajdy k vydání architektury ARM Cortex-X1: v SPEC2006 má být IPC až o 30 % lepší, než měl Cortex-A77V „strojovém učení“, což budou SIMD výpočty, mají A77 a A78 podle ARMu stejné IPC, ale Cortex-X1 ho má dvojnásobné při stejné frekvenci. Kromě toho ARM také uvádí simulace pro trest Stream a browserový benchmark Google Octane, kde jsou ale nárůsty IPC méně vysoké než u SPEC2006.
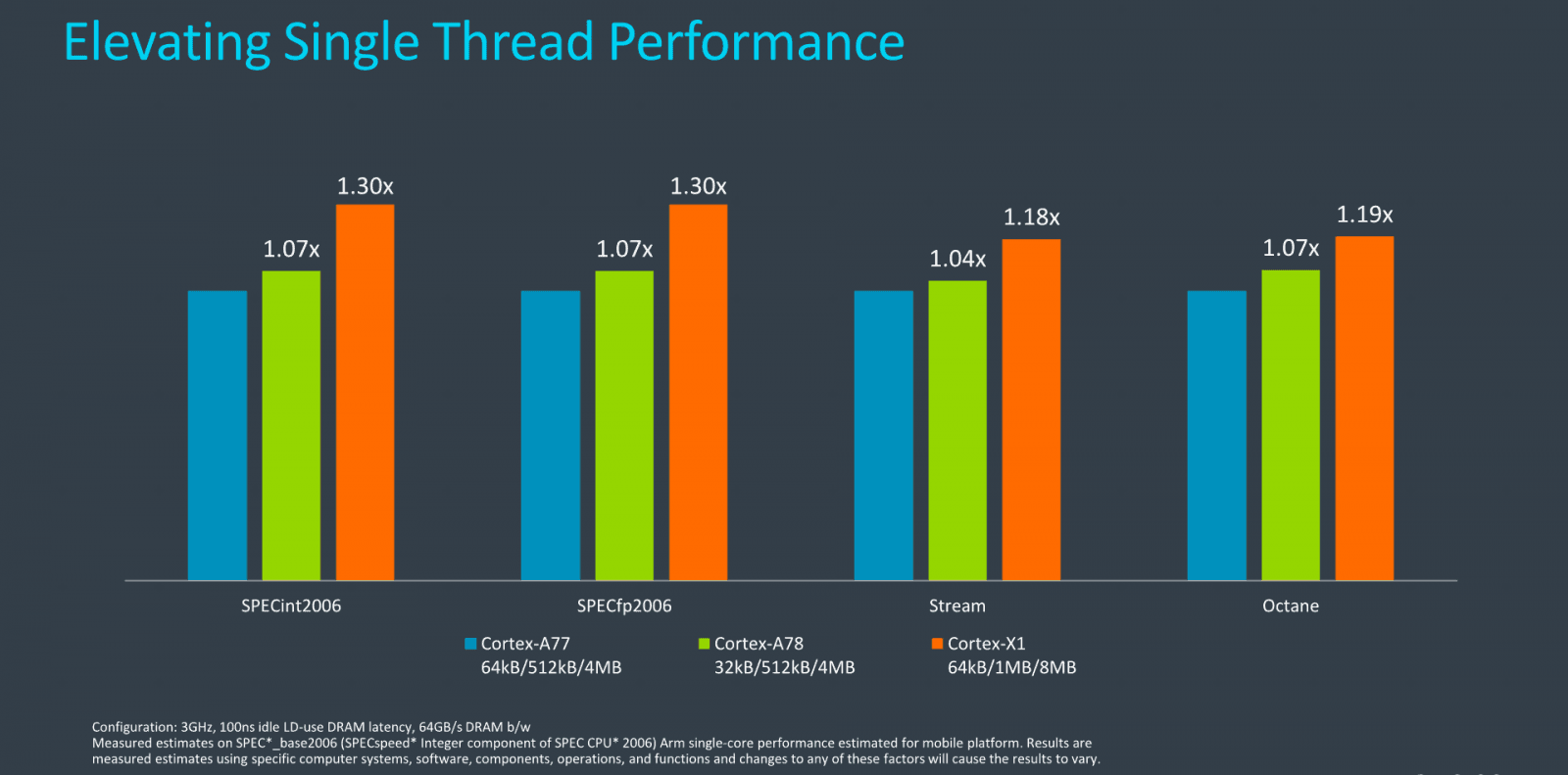
 Stream a Google Octane (Javascript) ukazují nižší přínosy
Stream a Google Octane (Javascript) ukazují nižší přínosyV Stream má být 3GHz Cortex-A78 s 32KB L1 cache o 4 % výkonnější než stejně taktovaný Cortex-A77 a Cortex-X1 má být výkonnější (tedy mít vyšší IPC) o 18 %. Proti Cortexu A78 by tedy měl 13,5 % lepší IPC. Tento test by měl být závislý hlavně na výkonu paměti, takže možná nejde o čisté IPC CPU jádra.
V Google Octane je zlepšení IPC o 7 % pro Cortex-A78 a o 19 % pro Cortex-X1. To by znamenalo, že Cortex-X1 zde má o 11,2 % lepší IPC než Cortex-A78. Tento benchmark by mohl být docela podstatný, protože měří výkon ve zpracování JavaScriptu. Mohl by tedy asi býtrelevantní prohlížení internetu a související aplikace, což je u mobilů, PC a spotřebitelských zařízení docela významná disciplína.
Cortex-X1 je „Custom“ architektura
Je zajímavé, že podle ARMu vznikl Cortex-X1 trošku jinak, než byste čekali. Jde totiž o evoluci programu zavedenému v roce 2016, v jehož rámci ARM pro zákazníky upravoval návrhy jader Cortex. Proto je X1 považován za „custom“ jádro, které bude nabízeno zákazníkům patřícím do tohoto programu. Nicméně návrh bude jen jeden identický pro všechny, jednotlivým licencujícím firmám ho už ARM dál upravovat nebude. I když je možné, že něco podobného se vrátí v dalších generacích.
 Vysoký výkon pro nárazové/jednovláknové zátěže, i na úkor spotřeby
Vysoký výkon pro nárazové/jednovláknové zátěže, i na úkor spotřeby

ARM Holdings uvádí, že u Cortexu-A78 by výkon měl být relativně udržitelný v určitém limitu spotřeby (ovšem v mobilních čipech pořád asi bude nějaké krátkodobé boostování versus nižší stabilní výkon). U architektury Cortex-X1 ale vyloženě mluví o tom, že cílem je zvýšit výkon ve vysoké zátěži, ale tento boost nemusí být moc dlouhodobě udržitelný, alespoň v mobilním SoC.
Toto naznačuje, že Cortex-X1 asi nebude mít vyšší energetickou efektivitu a současně s výkonem bude také vyšší příkon. Pokud by tedy mobilní SoC měl udržitelnou spotřebu limitovanou třeba na 4 W, pak jádra Cortex-X1 by musela snížit svou frekvenci na výrazně méně než Cortex-A78.
Třístupňové hybridní SoC?
Podle ARMu se z těchto důvodů dost možná budou jádra Cortex-X1 používat v mobilních SoC jen v malém počtu – čip by mohl mít jen dvě nebo dokonce jen jedno pro urychlení jednovláknových úloh. Většina takových SoC by tedy mohla mít třístupňovou hierarchii, s jedním Cortexem-X1 či dvěma, zbylými velkými jádry na architektuře Cortex-A78 a k tomu pak ještě malá jádra Cortex-A55.
Jádro/jádra X1 asi často nebudou ve vlastním klastru, ale mohla by zřejmě obsazovat společný klastr s jádry A78 (tedy například 1+3 nebo 2+2).
 Slajdy k vydání architektury ARM Cortex-X1
Slajdy k vydání architektury ARM Cortex-X1Při odhalení X1 jinak zazněla chvála od zástupců divize Samsung vyvíjející ARM procesory Exynos. Toto pravděpodobně znamená, že Samsung bude klientem onoho custom programu a jádra X1 použije ve svých čipech. Firma nedávno zrušila vývoj vlastních jader, jejichž ambicí bylo právě dosažení vyššího výkonu, než mají Cortexy řady A. Použití jader X1 a jejich eventuálních nástupců jako náhrady je zcela logický krok.
Dalšími klienty by nejspíš mohl být Qualcomm a možná i MediaTek, jenž ale často míří na nižší cenu, takže uvidíme, zda se tomuto highendu nevyhne. V serverových procesorech se patrně Cortex-X1 neobjeví, ale mohla by od něho vzniknout odvozená architektura Neoverse, využívající jeho vysoký výkon.











































