
Jak již bylo známo, Denver je architektura stavěná na vykonávání až sedmi operací za jeden takt (tzv. 7-issue), jedná se tedy o superskalární návrh. Tato informace se nyní potvrzuje; navíc se dozvídáme, že jádra poběží na taktu až 2,5 GHz. Co ovšem může být jistým zklamáním je, že Denver nepoužívá technologie out-of-order vykonávání instrukcí, která je obvykle klíčovou vlastností nejvýkonnějších CPU.

Nvidia místo toho sáhla k netradičnímu řešení. Denver dokáže přímo vykonávat instrukce ARM bez úprav, pro zvýšení výkonu však obvykle používá softwarovou JIT rekompilaci kódu v reálném čase pojmenovanou Dynamic Code Optimization. Ta by již měla generovat přímo operace v interní instrukční sadě Denveru a zároveň supluje technologii out-of-order, neboť eliminuje nepotřebné instrukce, přejmenovává registry, vybírá operace, které lze konat paralelně a vůbec se stará o optimální vytížení sedmi jednotek jádra. Optimalizace a řazení instrukcí probíhá údajně nad poměrně velikým „oknem“, které má čítat stovky instrukcí.
Tento optimalizovaný kód lze navíc poté používat opakovaně, takže teoreticky lze dosahovat i lepšího výkonu než při nativním běhu. Tedy za určitých podmínek, samozřejmě. Pro potřeby Dynamic Code Optimization je vyhrazeno 128 MB operační paměti, spolupracuje ale samozřejmě i s instrukční L1 cache.
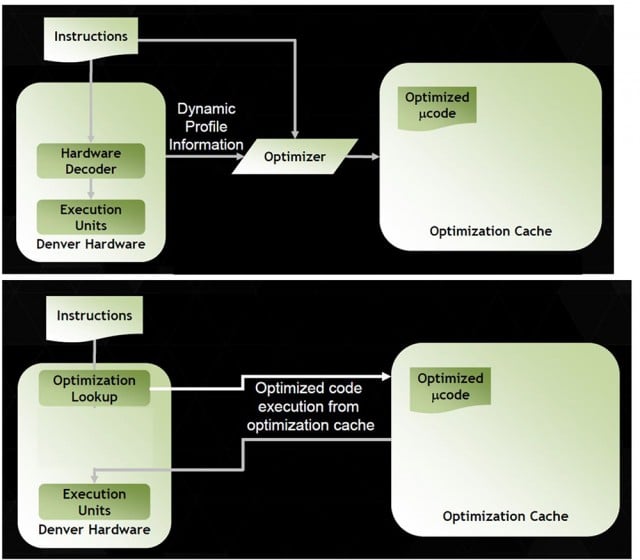
Pokud si pamatujete procesory Crusoe firmy Transmeta, už jste jistě doma. Nvidia má na technologie této firmy licenci a údajně po ní také podědila množství zaměstnanců. Nízkoúrovňová softwarová optimalizace s překladem instrukcí byla právě charakteristikou čipů Transmeta a Nvidia nyní jde stejnou cestou. Zajímavé na tom je, že Denver by tím pádem měl být schopen i emulace sady x86 jako Crusoe, pokud by o to firma měla zájem a Intel to strpěl...
Podle Nvidie je toto řešení efektivní z hlediska výkonu i spotřeby, absence logiky out-of-order by také měla značně zjednodušit a zmenšit celé jádro Denver. Překlad kódu ovšem znamená práci navíc, což se ale údajně má bohatě vrátit. Podle Nvidie má být výkon vysoký jak v jednovláknové, tak ve vícevkláknové zátěži a překonávat i různá mobilní osmijádra. CPU má i hardwarový dekodér ARM, takže v případě potřeby je možno Dynamic Code Optimization přeskočit.
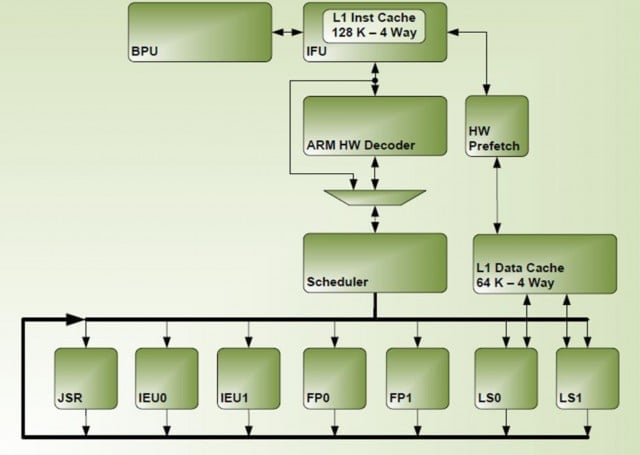
Co dalšího jsme se o Denveru dozvěděli? Jádro má 128KB instrukční L1 cache a 64KB L1 pro data, obojí s čtyřcestnou asocitivitou. L2 cache o velikosti 2 MB je sdílená (v Tegře K1 mezi dvěma jádry) a její asociativita je šestnácticestná. Denver má mít také značně agresivní prefetch. Nvidia zatím příliš nespecifikovala další detaily, zdá se však, že jádro obsahuje dvě jednotky typu ALU (IEU), dvě FPU, dvě jednotky load/store, takže ve výsledku vlastně nejde o zas tak široký návrh. K čemu je přesně sedmá jednotka JSR vám nepovím, mohla by sloužit pro větvení, skoky a podobně.

64bitová Tegra K1 s jádry projekt Denver je pinově plně kompatibilní s tou 32bitovou. To znamená, že výrobci zařízení mohou nový procesor vrhnout na trh již poměrně záhy, neboť vyřešit je třeba jen softwarovou stránku. Uvidíme, zda to někdo stihne už letos.
Zdroje: ExtremeTech, Nvidia










































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU