


Procesorová architektura RISC-V už získala značný zájem polovodičových a IT firem – a také popularitu u běžných zájemců o technologie či open source, neboť jde o otevřenou a „free“ instrukční sadu. Nicméně zatím se s ní počítá zejména jako s náhradou jader ARM či dalších pro potřeby embedded mikrořadičů často schovaných hluboko v jiných čipech a uživateli nepřístupných. RISC-V zatím nenabízí nějaký výkonný hardware, na němž by se dalo třeba provozovat alternativní stolní PC. Ovšem zde možná přichází zlom. Firma SiFive, která vyvíjí licenční jádra RISC-V jako komerční hotovou alternativu pro zájemce o tuto otevřenou architekturu, totiž teď odhalila první jádro s vyššími výkonnostními ambicemi. Architektura U84 a její pozdější odvozenina U87 mají atakovat až ARM Cortex-A72, což už by slibovalo celkem použitelný procesor.
SiFive je firma založená v roce 2015 přímo některými autory architektury RISC-V (ovšem nyní v ní pracuje jako architekt také třeba Andy Glew, jenž prošel Intelem, AMD, MIPS a Nvidií). Vyvinula i vlastní RISC-V čipy a stojí například i za vývojářskou deskou HiFive1. Teoreticky by tedy tato firma mohla jednoho dne hrát podobnou ústřední úlohu pro ekosystém, jako ARM Holdings. Ale v případě RISC-V vzhledem k volné licenci instrukční sady a tím pádem možnosti ušetřit asi hodně firem bude raději vyvíjet vlastní jádro nebo používat nějaká bezplatně dostupná open source jádra, byť u těch má vývoj logicky menší „drajv“.
První komerční out-of-order jádro RISC-V: lepší než ARM Cortex-A72?
Všechna dosavadní jádra, která SiFive nabízela, byla nižšího výkonu s jednoduchou in-order architekturou. Nyní však firma nakročila do vyšších pater uvedením nové série jader U8, která používají out-of-order zpracování instrukcí, kdy procesor instrukce může zadávat výpočetním jednotkám nejen paralelně (to lze i u superskalárních in-order jader), ale i mimo pořadí, což dokáže značně zlepšit výkon za jeden MHz. Proti předchozím in-order jádrům má narůst několikanásobně.
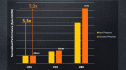
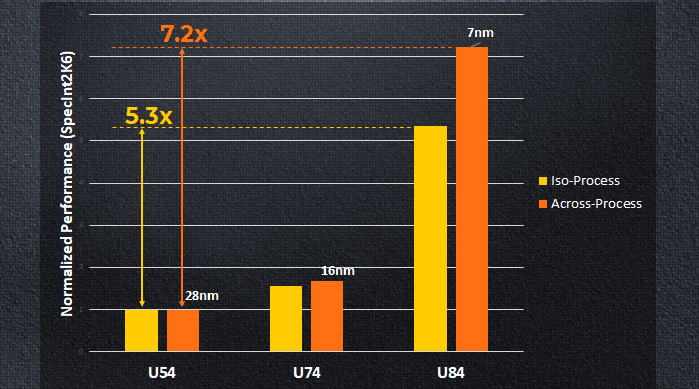
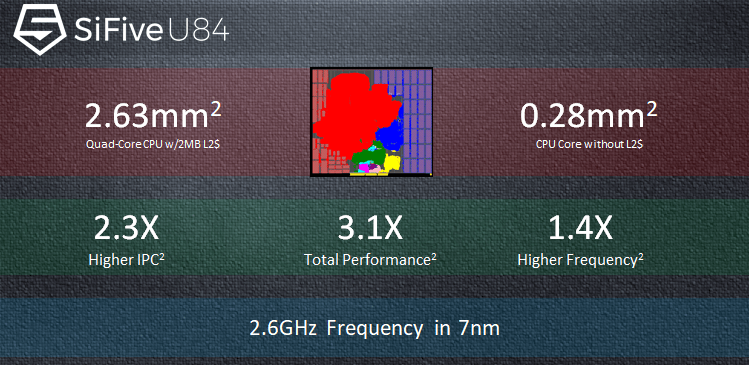
Plán či projekce jsou takové, že jádra U8 budou zhruba výkonem konkurenceschopná se starším (2015) ARM Cortexem-A72 vyrobeným na 16nm procesu TSMC. Ale má na to potřebovat jen polovinu plochy na čipu a má údajně mít až o 50 % lepší energetickou efektivitu. K tomu je třeba říct, že ARM už má lepší jádra (aktuální Cortex-A77 by měl být o hodně dál), není jasné, zda se porovnává stejný výrobní proces. V čem se porovnává výkon, to víme, mělo by jít o SPECint (ale není uvedeno, zda 2006, nebo 2017).
Architektura jader U8 (U84 a U87)
Web AnandTech dostal od SiFive podrobnější informace k architektuře nových out-of-order RISC-V jader, díky čemuž se na ně můžeme podívat. Architektura U8 by měla dát vzniknout zprvu dvěma verzím, U84 a U87. Měly by být podobné s tím rozdílem, že U84 má jen klasické celočíselné jednotky a skalární FPU, ale postrádá jinde dnes skoro neodmyslitelné SIMD (vektorové) rozšíření důležité pro intenzivnější výpočty, ale i multimédia – tedy ekvivalent SSE/AVX u x86 nebo ARM Neon). Jejich specifikace totiž zatím ještě není uzavřená. SIMD jednotky proto dostane právě až další verze jádra pojmenovaná U87, která bude k dispozici zřejmě až příští rok. Bližší parametry této architektury zatím SiFive neuvádí. Zatím se tedy bavíme jen o jádru U84 bez podpory SIMD.
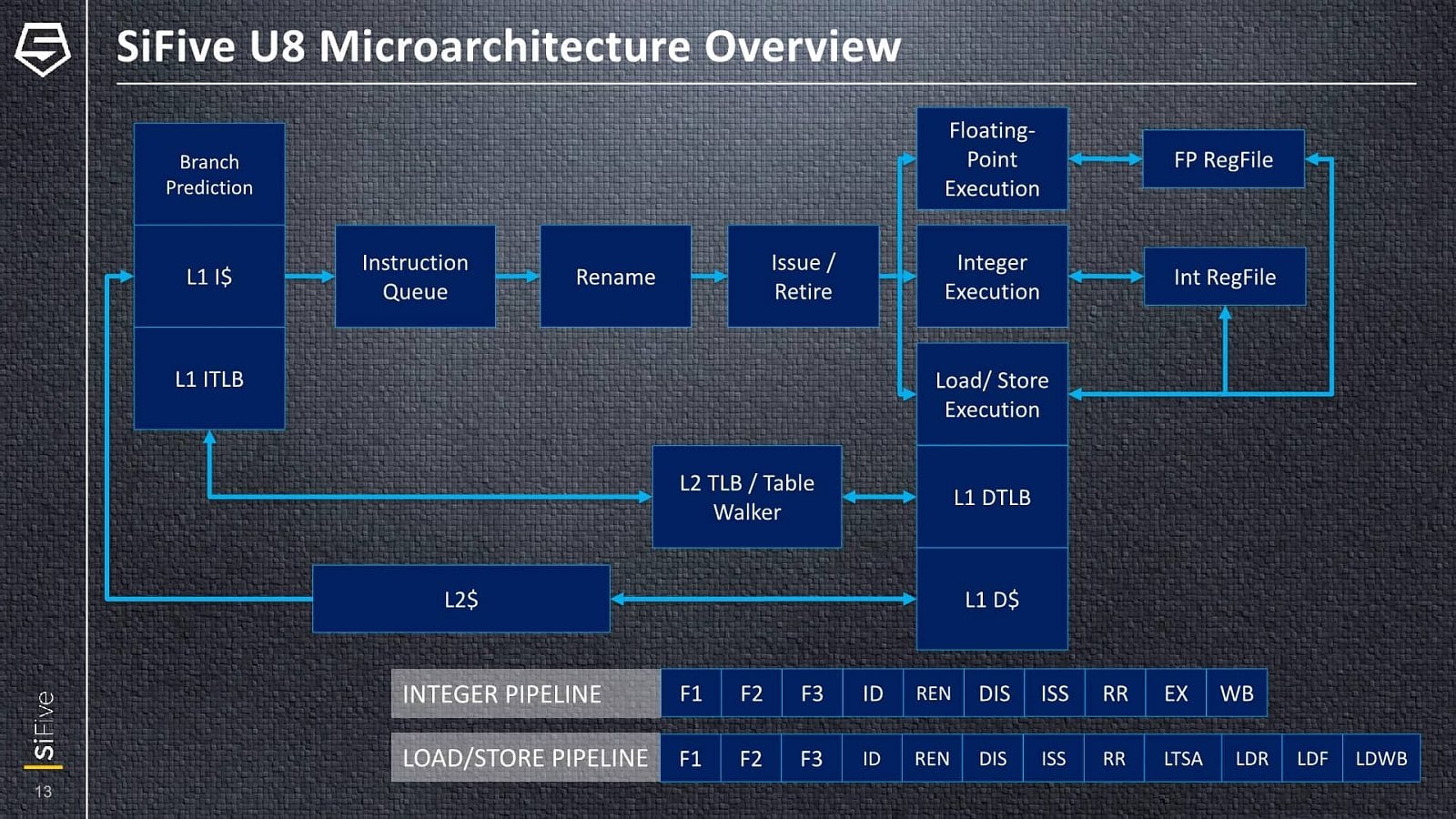
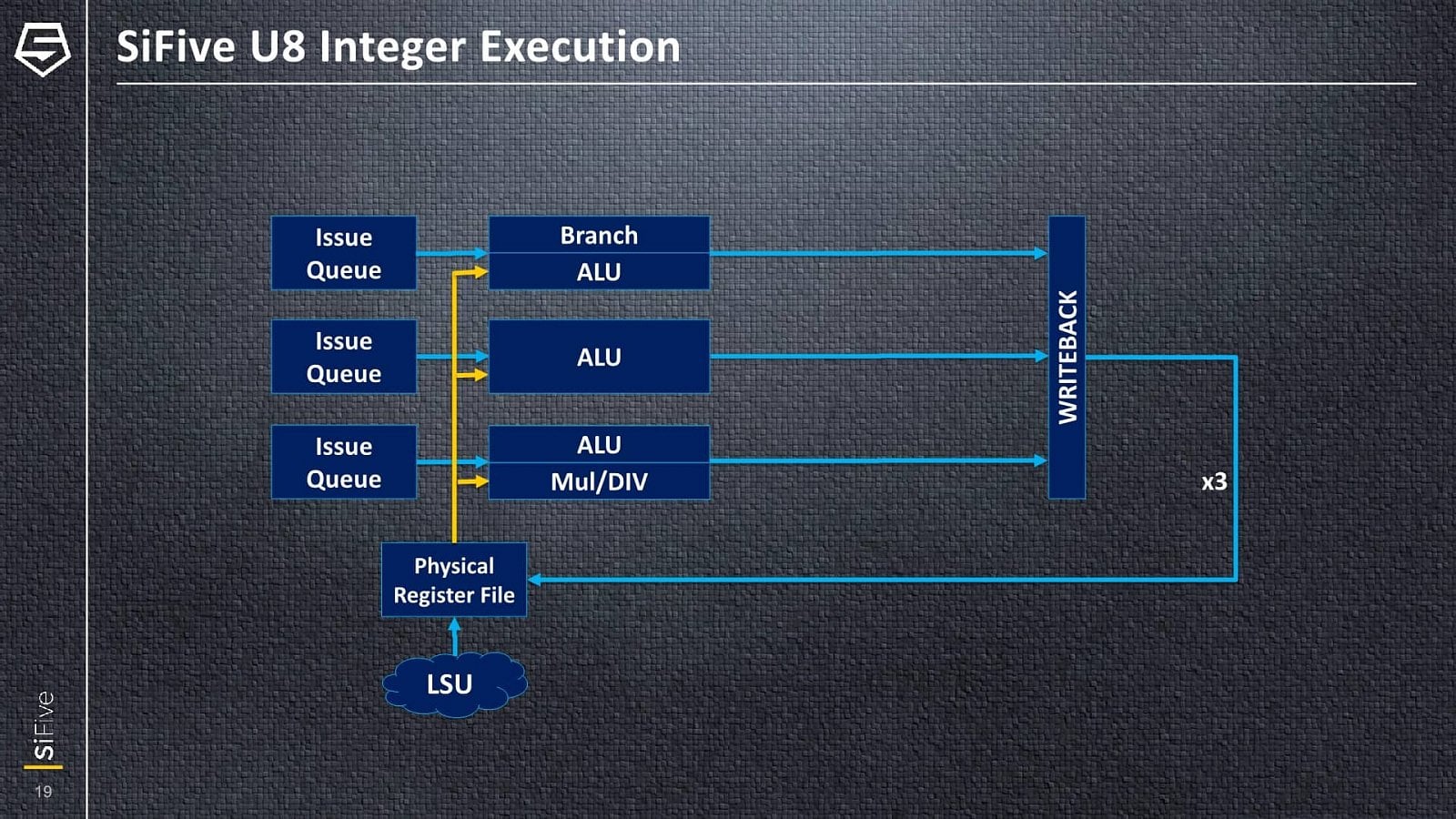
Jádro SiFive U84 má 12stupňovou pipeline (10 stupňů pro ALU pipeline, 12 stupňů pro operace load/store) a jedná se o 3-issue architekturu, schopnou zpracovávat tři instrukce za jeden cyklus – stylem out-of-order, jak už bylo řečeno. Design také používá fyzický soubor registrů (physical register file), což umožňuje snadné přejmenování registrů, aniž by se samotná data musela přesouvat. Ne všechny parametry byly sděleny (například jako je hloubka některých bufferů out-of-order vykonávání), některé snad mohou být i konfigurovatelné podle preferencí implementátora.
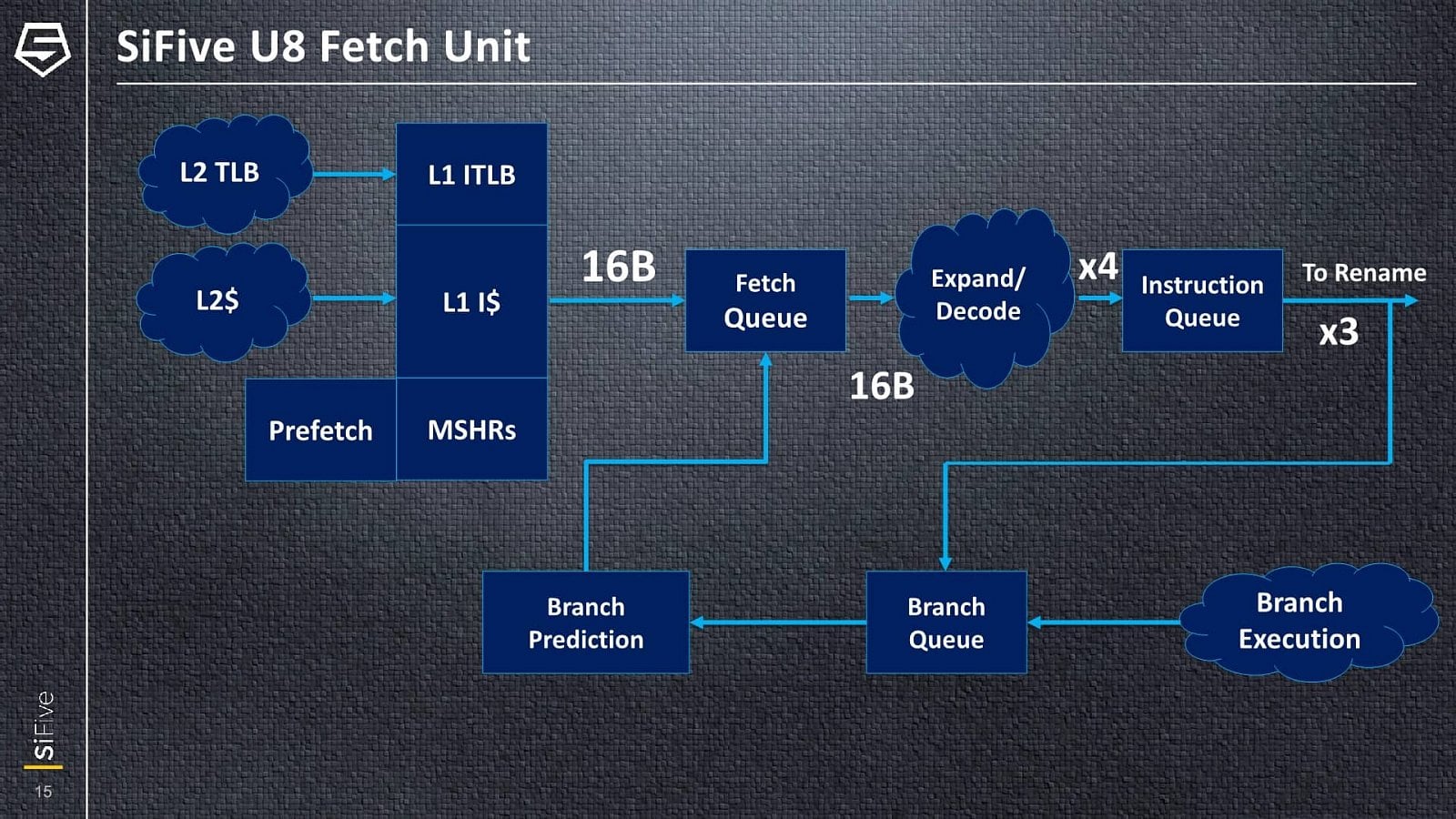
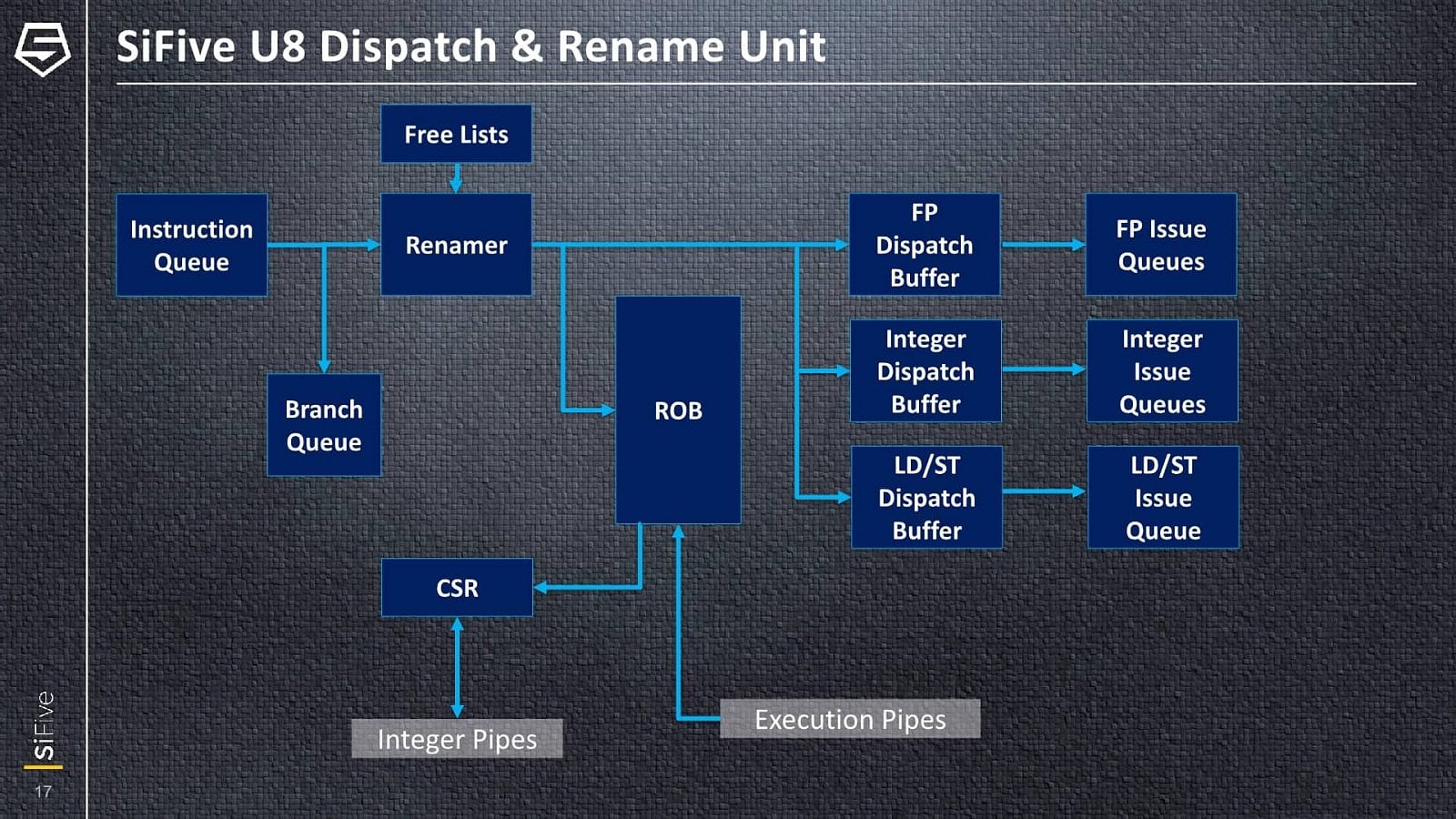
Fetch instrukcí probíhá z instrukční L1 cache, přičemž v každém cyklu je možné dodat 16 bajtů, což by při 32bitové délce instrukční dávalo čtyři instrukce, ovšem RISC-V podporuje variabilní délku instrukcí, takže v případě užití komprimovaných 16bitových instrukcí by to mohlo být i více. Dekodér či dekodéry však zpracovávají maximálně čtyři instrukce za takt. Ovšem do fáze přejmenování registrů (rename) už mohou z instruction queue postoupit jen tři instrukce za takt.
Fetch, decode a issue tedy dokáží zásobit více instrukcí, než lze za cyklus nasypat do výpočetních jednotek – toto by mělo být proto, aby frontend dokázal rychleji dohnat případné „bubliny“ nebo postih za špatně odhadnuté větvení. Je také možné, že 4-issue šířka frontendu už je připravená pro rozšíření backendu u budoucích následníků. Přítomnost spekulativního provádění s prediktorem větvení a out-of-order vykonáváním pravděpodobně znamená, že tato jádra již budou náchylná na zranitelnost Spectre V2 (Branch Target Injection), zatímco dříve se architektura RISC-V a SiFive honosily odolností čistě kvůli jednoduchým jádrům.
Tři ALU, FPU zatím nebyla odhalená
Za fází rename následuje reorder buffer o nespecifikované hloubce (takže nemůžeme porovnávat proti ARMům a x86), z nějž dispatch přiděluje tři dekódované instrukce/operace jednotlivým jednotkám. Celočíselná část má už tři ALU, které nejsou rovnocenné. Všechny zvládají jednoduché operace, ale celočíselná násobení a dělení jdou vždy jen přes jednu z nich. Jedna ze zbylých jednoduchých ALU pipeline pak zase vedle aritmetickologických operací také obsahuje jednotku pro zpracování větvení, pro které není separátní pipeline, jako často u jader ARM. Každá z těchto tří ALU pipeline má před sebou vlastní issue queue.
Kromě vlastních ALU jednotek musí přirozeně být přítomné také load/store pipeline či AGU pro provádění přesunů dat mezi registry a pamětí (respektive L1/L2 cache). Nicméně k tomu, kolik jich je a kolik čtení a zápisů dat za cyklus zvládnou, SiFive neprozrazuje. Podobně nesděluje, kolik je vedle ALU v jádru FPU pipeline pro výpočty s plovoucí řádovou čárkou (floating point). Nevíme tedy, zda je jedna, dvě a striktně vzato ani, zda náhodou nefunguje in-order. Nicméně až přijde jádro U87 se SIMD rozšířením, pravděpodobně bude tato část také lépe popsána. Čistě skalární floating point operace možné na U84 asi nejsou zas takovou prioritou.
U8 umožňuje vytvořit až devítijádrové CPU
Jaké parametry mají L1 a L2 cache, SiFive také neuvádí. Zde je právě možné, že kapacity budou volitelné a s tím ruku v ruce možná i asociativita. Uvedené nejsou nicméně ani latence. V příkladu implementace se ale zmiňuje možnost mít čtyřjádrový klastr se sdílenou L2 cache o kapacitě 2 MB. L2 tedy může být sdílená a pravděpodobně by měla roli mezipaměti poslední úrovně.
Klastr ovšem nemusí být jen čtyřjádrový, jednu L2 může takto sdílet až devět jader s plnou koherencí. Je také uvedeno, že lze zkombinovat heterogenní jádra, takže U84 může mít roli „big“ jader a lze přidat nějaká úsporná „little“ jádra (U7 či ještě jednodušší jádra SiFive řady S), jako u čipů ARM.
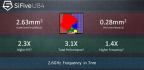
Takt až 2,6 GHz na 7nm procesu
Jádro U84 má údajně dosahovat až o 40 % lepší frekvenci než předchozí in-order architektura U74. Na 7nm procesu má prý být schopné běžet až na 2,6 GHz. Ale uvidíme, zda třeba reálná implementace nezaostane – celkem často se stane, že na trhu jsou nakonec dostupné jen nižší frekvence, než bylo původně uvažované maximum. Výkon má být proti U74 až 3,1× lepší, z čehož část dělá pokrok ve frekvenci, zbytek vyšší IPC – to je údajně 2,1× lepší. Na 7nm procesu jinak prý pro jedno jádro bez L2 cache stačí plocha 0,28 mm². Čtyřjádrový klastr se společnou L2 cache o kapacitě 2 MB se má vejít do 2,63 mm².
Výkonnější jádra by měla hodně posunout možnosti architektury RISC-V pokrýt různé segmenty trhu. Takovéto čipy by byly dobře použitelné například na jednodeskových počítačích, které ovšem potřebují také dost periférií, GPU, multimediální funkce a konektivitu, takže zde asi tak snadno nějaké „RISC-V Pi“ nevznikne. Také v mobilní oblasti asi nehrozí, že by se RISC-V rychle dostal do telefonních SoC, protože přechod například platformy Android by musel překonávat spoustu překážek. Pravděpodobně tak i tato jádra budou více používána hlavně v embedded oblasti a jako „služebná“ integrovaná jádra různých čipů – třeba výkonných SSD řadičů. Nicméně pokud se nějaké firmy pokusí na RISC-V založit přímo uživatelsky viditelný procesor pro nějakou aplikaci, budou tyto silnější architektury jedním z předpokladů, aby takový snaha byla úspěšná.