
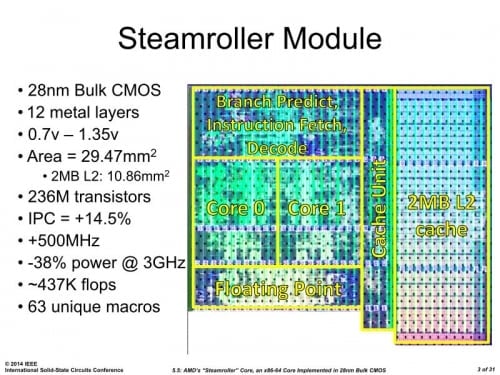
Ze slajdů (na web se bohužel zdaleka nedostaly všechny) se dozvídáme některé charakteristiky modulu architektury Steamroller, coby základního stavebního prvku odvozených CPU. V APU Kaveri má 28nm modul Steamroller plochu 29,47 mm² (celé Kaveri má měřit 245 mm²), z toho ovšem celých 10,86 mm² zabírají 2 MB L2 cache. Bez ní by modul se dvěma procesorovými jádry tedy měřil 18,61 mm². Celý modul obsahuje 235 milionů tranzistorů. Celé Kaveri dle oficiálního údaje zveřejněného při uvedení obsahuje desetkrát tolik tranzistorů (2,41 miliardy), nevíme ale, zdali se oba tyto údaje počítaly stejnou metodikou a lze je tedy porovnávat.
Prezentace potvrzuje, že Steamroller byl především navržen s cílem vylepšit efektivitu a poměr mezi výkonem a spotřebou. Při stejné spotřebě údajně Steamroller – zřejmě ve srovnání s Piledriverem – dokáže běžet na taktu vyšším o 500 MHz. To ale zřejmě platí, pohybujeme-li se na nízkých taktech typických například pro notebooky; neboť jak známo, na desktopu Kaveri končí na nižších taktech CPU než starší Richland. Pokud se moduly nastaví na stejný takt 3 GHz, potřebuje údajně Steamroller o 38 % méně energie. Podle některých zdrojů už má AMD v modulu Steamroller konečně používat rezonanční distribuci hodinového signálu, která se měla objevit již v Piledriveru, z toho ale zřejmě sešlo. Dalším úsporným trikem je například schopnost dynamicky vypínat a odpojovat od napájení zrovna nepotřebné bloky L2 cache.
Architektura AMD Steamroller - slajdy z ISSCC 2014 (Zdroj: PC Watch)
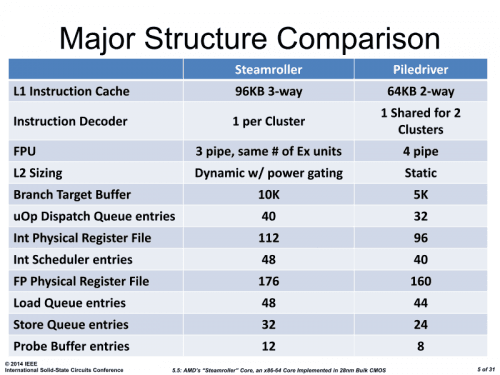
Steamroller má dle AMD dosahovat 9–18% nárůstu IPC (výkonu při stejném taktu), přičemž přínosy jsou nižší v jednovláknové a vyšší ve vícevláknové zátěži. Průměrné zlepšení AMD uvádí zhruba na 14,5 %, pochopitelně ale bude hodně záviset na průměrování a vybraných benchmarcích. Z ISSCC máme konečně také přehled některých úprav v čipu, které toto zlepšení umožňují. Již víme, že v Steamrolleru dostalo každé jádro vlastní instrukční dekodér, takže se již navzájem neblokují, a také že Steamroller má nově 96KB třícestnou L1 cache pro instrukce (což je o 50 % vyšší asociativita a kapacita než u Piledriveru).
Architektura AMD Steamroller - slajdy z ISSCC 2014 (Zdroj: PC Watch)
Kromě toho ale Steamroller posílil různé buffery používané systémem vykonávání instrukcí mimo pořadí (Out of Order Execution). Branch Target Buffer je dvojnásobný (10 KB místo 5 KB), kapacita uOp Dispatch Queue se zvedla z 32 instrukcí na 40, scheduler ALU pracuje nad „oknem“ 48 instrukcí místo původních 40. Prohloubily se fronty pro čtení (z 44 na 48 položek) i zápis do paměti (z 24 na 32 položek). A zvětšilo se i množství interních registrů, takže procesor dokáže přemapovat a podržet více hodnot z architektonických registrů. Fyzicky má nyní čip k dispozici 176 registrů FPU/SIMD a 112 obecných registrů (Piledriver jich měl 160, respektive 96). Obecně lze říci, že zvětšení bufferů a front vede k lepšímu využití dostupných jednotek a tedy zvyšuje výkon při stejném taktu.

Modul Steamroller potřebuje dvanáct vrstev kovových mezispojů a počítá se u něj s rozpětím provozních napětí od 0,7 V až do 1,35 V. V návrhu AMD proti minulosti zřejmě používá menší množství ručně navržených bloků, což by mělo ulehčit přesun na jiný výrobní proces či do jiné továrny; je ale otázka, zda takovou příležitost AMD někdy využije. V čipu je těchto nesyntetizovaných bloků (maker) 63, což je ale stále o mnoho více, než v prakticky plně syntetizovaném Jaguaru (ten jich obsahuje jen pět).












































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU