
Minulý týden jste si mohli přečíst první technický pohled na procesorové jádro Zen. To je nejzásadnějším počinem, s kterým firma přišla od příchodu Bulldozeru – zcela od základu novou architekturou CPU, nadto s úkolem zásadně zvrátit konkurenceschopnost a finanční zdraví svého tvůrce. Šlo nicméně jen o ochutnávku, neboť většinu informací si AMD schovalo až na prezentaci na konferenci Hot Chips 28. Z ní nyní máme detailní přehled celého jádra Zen a základní jednotky, tzv. Core Complexu, z nějž se odvozená CPU a APU budou skládat. Zatímco minule to bylo spíše povrchní, tentokrát AMD o samotné architektuře řeklo skoro vše, co o ní sděleno kdy bude.

Ještě než k detailům přejdeme,
však něco ke „koncepci“ celé architektury, jak ji inženýři
AMD charakterizovali. Mike Clark z týmu pracujícího na Zenu
uvedl, že toto pojmenování má vyjadřovat „rovnováhu“, což
byl při návrhu ústřední cíl. Jádro je údajně navrženo tak,
aby ideálně spojovalo všechny možné cíle – tedy výkon,
dosažitelné frekvence, funkce a instrukční schopnosti
a spotřebu. To také zřejmě znamená, že kompromis těchto
faktorů může jednotlivé vlastnosti držet níže, než kam by je
pustila architektura soustředící se právě na ten daný aspekt,
například vysokou frekvenci jako Bulldozer.
Výjimku a přednost možná měla
jen jedna věc – od základu byly údajně u všech
rozhodnutí brány v potaz otázky spotřeby, které
v předchozích architekturách přicházely až v druhém
sledu, nikoliv hned při prvním koncipování jejího fungování.
Spotřeba nicméně dnes determinuje i dosažitelný výkon,
jelikož TDP jsou omezená, takže prioritizovat efektivitu by dávalo
smysl.
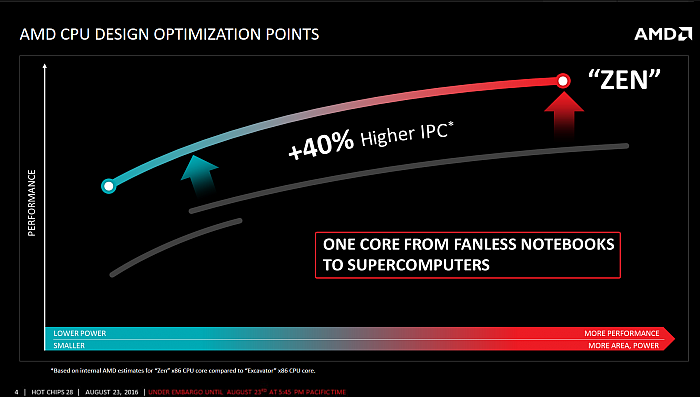
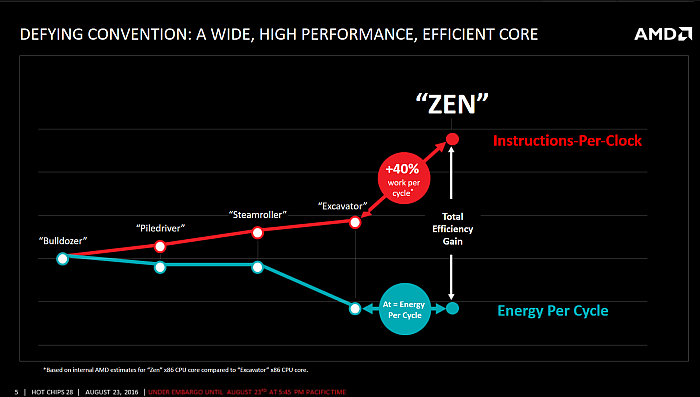
Zen má být zároveň náhrada za úsporný Jaguar (křivka vlevo) i výkonný Excavator (vpravo)
Zastaň kočku i bagr!
Kromě toho AMD uvedlo ještě jeden
záměr při návrhu čipu. Zen je podle něj náhrada jak „velkých
jader“ rodiny Bulldozer, která operovala s větším
absolutním výkonem, ale také s větší spotřebou, tak
i úsporných „malých jader“ Bobcat, Jaguar a tak
dále, která jsou úspornější, ale také slabší. Zen má naopak
pokrýt celou škálu těchto využití a být použitelný jak
při TDP Jaguaru, tak Excavatoru, přičemž má obě jádra v těchto
situacích kvalitativně překonávat. A to nejen výkonem, ale i efektivitou.
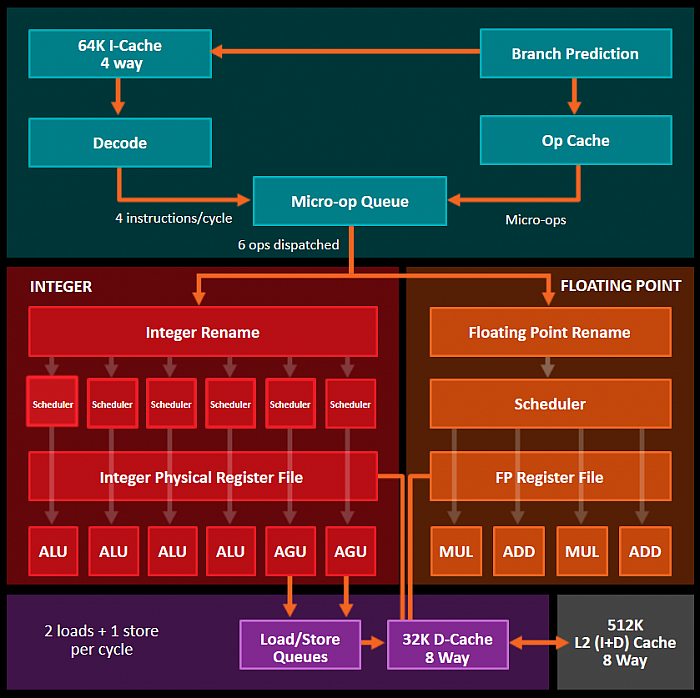
Schéma jádra Zen (Hot Chips 28)
Jádro podrobně
Nyní už tedy k architektuře
jádra samotného. To je stavěno na podstatně vyšší výkon při
stejném taktu – orientačně má být o 40% výkonnější
než Excavator, což je nejaktuálnější derivát Bulldozeru.
Pokud budeme sledovat jádro z hlediska
změn proti dnešní architektuře, pak začneme hned ve „frontendu“.
Jádro Zen má stále čtyři dekodéry, proti Excavatoru ale výkon
zvýší tzv. „Op Cache“ či „Micro-Op Cache“, která je
novinkou (Intel ji však má od Sandy Bridge) a ukládá již
dekódované instrukce. V případě, že pro danou instrukci
v kódu existuje protějšek v cache dříve dekódovaných
micro opů, může být dekódování přeskočeno. Zda je toto
možné, pozná procesor podle micro tagů, přidělených kódu
v předchozí fázi zpracování, tzv. „Fetch“, kdy si
procesor bere postupně kód programu z instrukční L1 cache.
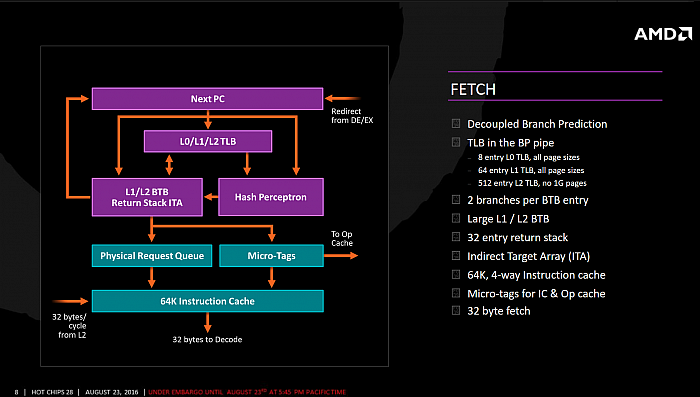
Zen: frontend, fáze Fetch
I fáze Fetch (která při zpracování
předchází dekódování) jinak přináší některá zlepšení,
například zde procesor má vylepšené předpovídání větvení.
Prediktory se vyvíjejí kontinuálně, a proto je firmy
vylepšují prakticky každou novou generaci. K dispozici jsou
mu „velké“ (konkrétní kapacitu ale neznáme) branch target
buffery, přičemž pro každou položku v nich umí procesor
řešit dvě větvení. Procesor také dokáže předvídat, kam
program skočí při návratu ze subrutiny pomocí tzv. „Return
Stacku“, do nějž může mít uloženo 32 jednotlivých záznamů.
Obě opatření by měla pomáhat jednovláknovému výkonu.
Do fronty Micro-opů následující po
fázi Decode, tedy dekódovaných instrukcí, které jsou již
převedené z x86 na interní sadu CPU, podle situace jde buď
nově dekódovaná instrukce z dekodérů, nebo (což zpracování
urychlí a ušetří elektřinu) z Op Cache. Při využití
obou zdrojů to může být šest instrukcí, tedy o polovinu
více, než v Excavatoru. Podle AMD je Op cache jedno
z nejdůležitějších zlepšení, právě tím, jak zvedá
výkon a snižuje spotřebu.
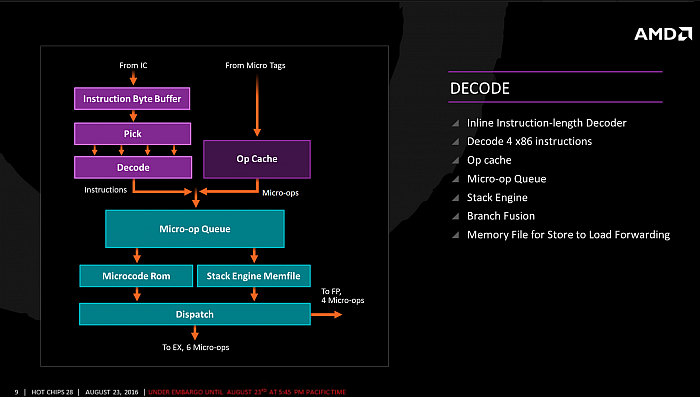
Zen: fáze dekódování instrukcí
V následující části
zpracování, frontě Micro-Op Queue a poté fázi „Dispatch“
následují další zlepšení. První spočívá v účinnější
technice Store to Load Forwarding. Procesor sleduje, zda není
zapisováno na místo v paměti, odkud poté bude znovu čteno.
V takovém případě je totiž možno čtení přeskočit
a předat rovnou hodnotu, mezitím uloženou v zvláštním
paměťovém souboru procesoru.
Další paměť je pak integrována
pro potřeby tzv. „Stack Engine“. To je struktura, která by si měla pamatovat poslední adresy v paměti a umožňovat úspornou práci s adresami, takže procesor nemusí provádět náročné operace pomocí AGU a load/store pipeline.
Cílem je opět omezit drahé a energeticky náročné přenosy
dat. Propustnost zpracování zde také vylepšuje technika Branch
Fusion, kdy jsou větvení sbalena dohromady s další
instrukcí.
Architektura Zen: frontend
Hlavní svaly Zenu, výpočetní
jednotky
Zatímco předchozí fáze provádění
kódu na papíře moc dobru představu o schopnostech procesoru
nedávají, lepší perspektivu nám předestře samotná vykonávací
část, kam z fáze Dispatch může proudit až deset instrukcí
za takt – šest do celočíselné části, čtyři do FPU.
Jádro sestává ze čtyř ALU, tedy jednotek vykonávajících
aritmetické a logické operace s celými čísly, dvou AGU
zpracovávajících adresy, čtení a zápis do paměti/cache
a čtyř pipeline v FPU. Naproti tomu Excavator měl ALU
jen dvě a v FPU pipeline tři, ale sdílené pro dvě
jádra – výpočetních prostředků je tedy v Zenu
mnohem více.
Rozdělené schedulery místo unifikovaného
Zen je specifický tím, že má proti
Jaguaru nebo Bulldozeru/Excavatoru v celočíselné části
vyhrazené shedulery pro jednotlivé ALU a AGU. Dispatch tedy
instrukce posílá do celkem šesti schedulerů o 14 položkách,
které pak pracují nezávisle, zatímco fronta Retire, kterou
výpočty končí, je poté již unifikovaná a má hloubku 192
položek (a dokáže zpracovat až 8 instrukcí za takt
proti čtyřem u Excavatoru).
Rozdělené schedulery, které
připomínají architektury K7 až K10, nejsou tak pružné, ale mají
jednu výhodu – AMD je údajně může jednotlivě odpojovat
od hodinového signálu (tzv. clock gating, který je agresivně
používán po celém jádru) a šetřit tak energii. Pokud se
kapacity schedulerů sečtou, mají tyto fronty 84 položek proti 48
u Excavatoru, přičemž platí, že čím víc, tím lepší
schopnosti přehazovat instrukce a vydřít z kódu více práce
na jeden cyklus.
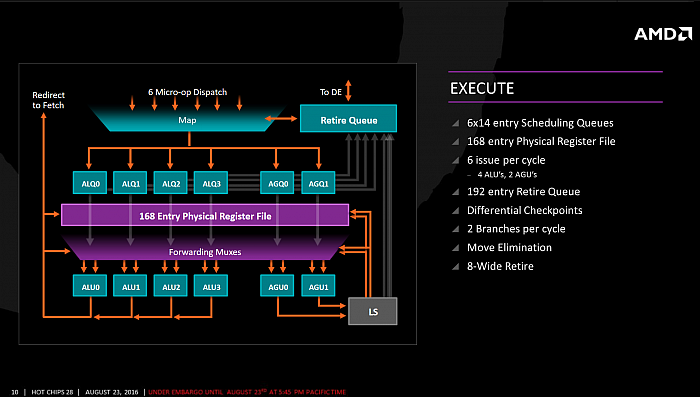
Celočíselná část výpočetních jednotek
Jednotlivé ALU jsou víceméně
symetrické pokud jde o většinu instrukcí. Násobení celých
čísel (IMUL) lze ovšem vykonat jen v jedné z nich,
podobně například instrukci CRC32. Větvení je také posíláno
jen do dvou ze čtyř ALU. Zbytek operací ale zastanou všechny. ALU
používají techniku elminace MOVů (tedy přesunů dat mezi
registry) díky použití fyzického souboru registrů, což ovšem
není u AMD nová věc. Soubor registrů má kapacitu 168
položek, dostupných pro držení, kopírování a přejmenovávání
architektonických registrů, jak to vyžaduje out-of-order
vykonávání kódu.
Dvě AGU dokáží provést dvě
128bitové čtecí operace nebo jeden zápis. Zpracování je stylem
out-of-order, kdy ve frontě může být až 72 čtecích operací
a ve frontě zápisů až 44 operací. Zde je možná určitá
nerovnováha, neboť u K10 i Bulldozeru až Excavatoru (ale
i Jaguaru) byl poměr ALU a AGU vždy 1:1. Pro více AGU
ale možná v architektuře Zen nezbylo místo, nebo (zatím)
nenastal čas – možná, že přibudou v některém z budoucích
následníků.
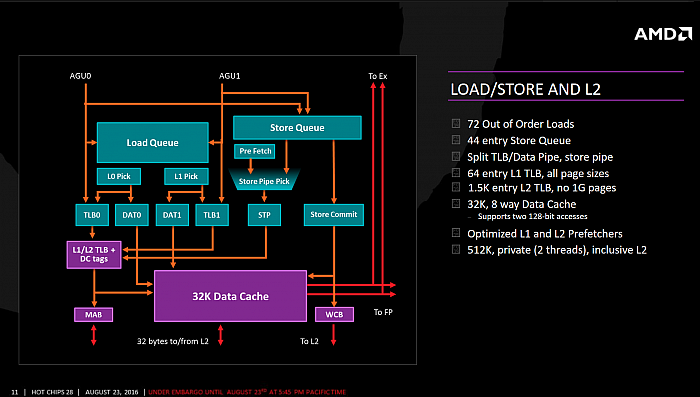
Systém AGU a Load/Store
FPU opět oddělená
FPU je oddělená, AMD u ní
zachovalo svůj typický „koprocesorový model“. Má svůj
vlastní scheduler, jenž tvoří dva stupně fronty (NSQ a SQ), což umožňuje
předem získat některé informace pro další zpracování v NSQ, než začne skutečný scheduling v SQ. FPU má
i vlastní soubor registrů (neboť instrukce SIMD pracují se
zvláštní sadou architektonických registrů yMM a xMM).
Scheduler je tentokrát unifikovaný, s hloubkou 96 proti 60
položkám u Excavatoru. AMD uvádí, že by mělo
být rychlejší čtení dat do FPU – z paměti cache se dostanou
za 7 cyklů, u buldozerů to bylo 9 cyklů. FPU
dokáže ukládat za takt jednou 128 bitů.
Samotné výpočetní pipeline jsou
čtyři, dvakrát „ADD“ a dvakrát „MUL“. Jejich
vektorová šířka je 128bitů, takže v jednom průchodu
zvládají instrukce SSE, ale na 256bitové AVX(2) potřebují
průchody dva (Zen z nich dělá dva Micro-Opy). V jednotkách
MUL je možno vykonat i instrukce FMAC kombinující násobení
a sčítání (FPU tedy zvládá dvě za takt). V případě,
že všechny vstupy má tato pipeline lokálně přítomné, není
zpracováním FMAC zaměstnána žádná další jednotka, pokud je
však třeba vstup získat z některé další pipeline,
k jejímu obsazení dochází. Za příznivé konstelace je však
možné provést dvojici FMAC a dvojici sčítání naráz.
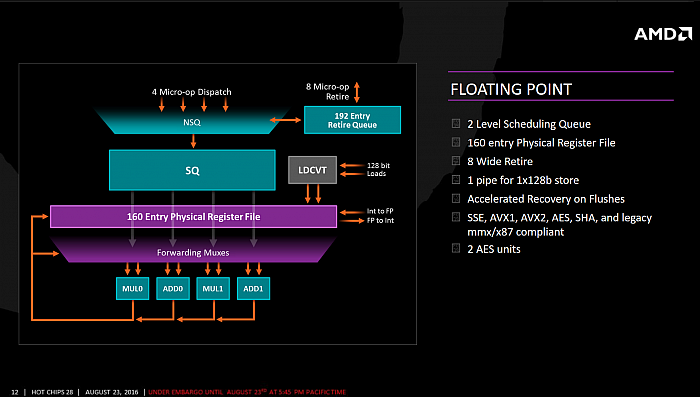
FPU Zenu
FPU podporuje instrukce x87, MMX,
SSE–SSE4, AVX a AVX2, FMA3, BMI1 a BMI2 a nově SHA
(přesněji SHA1 a SHA256). Také šifrování přes AES by mělo
být posíleno, každé jádro má v FPU dvě jednotky. Jádro
podporuje i další nové, avšak asi nikoli světoborné
instrukce, viz tabulku níže. Některé instrukce byly ovšem odebrány: Zen na rozdíl od Bulldozeru a potomků neumí rozšíření XOP či TBM, specifické pro AMD a nepodporované Intelem.
Celkově by FPU měla podávat
podstatně vyšší výkon, jelikož je nyní určena pro jediné
jádro, zatímco v derivátech Bulldozeru měl obdobné
prostředky (při kratších out-of-order bufferech) společně
k dispozici modul o dvou jádrech. Důležité budou
latence jednotlivých instrukcí, které ještě neznáme, vzhledem
k tomu, že Zen míří na konzervativnější takty, by ale
i u nich mohlo teoreticky dojít ke zlepšení (to ale
teprve uvidíme).
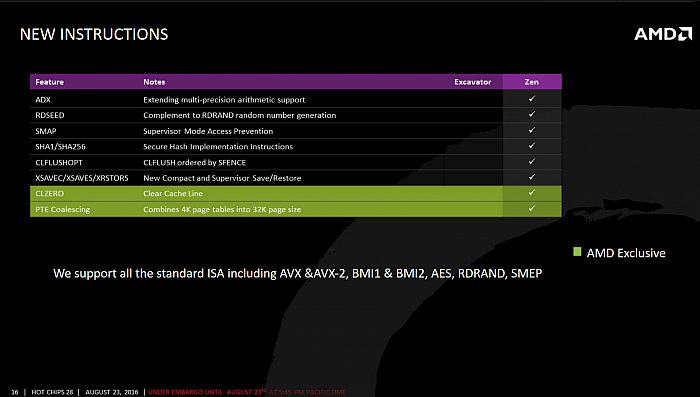
Nové instrukce podporované architekturou Zen
Out-of-order buffery v porovnání
se Skylake
Zde by se možná mohla udělat malá
odbočka. Asi si moc nedovete představit, zda jsou různé hloubky
bufferů a front, které jsme na základě materiálů
zveřejněných AMD popisovali, velké, či malé. Můžete je
srovnat s údaji v následující tabulce, které Intel
uvídí pro svá CPU. Čísla se poměrně blíží out-of-order
hloubce jádra Skylake, scheduler s dohromady 84 položkami
(ovšem rozdělenými do 6 front) je proti 97 u aktuálního
Intelu menší, AMD ale zase má zvlášť scheduler pro FPU
o hloubce 96. Fronta pro čtení je stejně dlouhá (72), pro
zápis však kratší (44 proti 56 položkám). Kapacity registrových
souborů jsou podobné: Zen 168/160, Skylake 180/168.
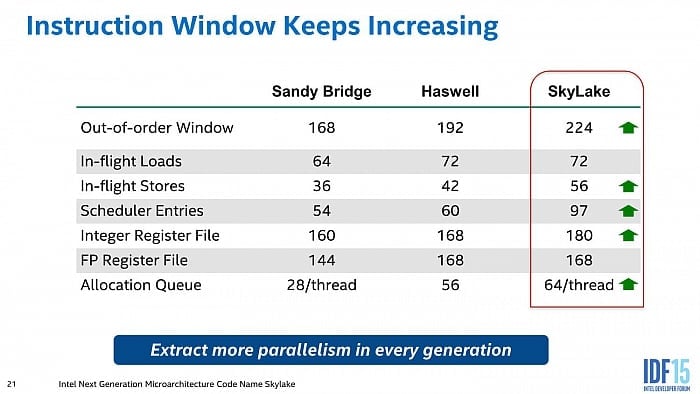
Hloubky front a bufferů u procesorů Intel
Reparát z cache, SMT a ideové vyznění díla
Jedno ze zásadních zlepšení je pro
Zen očekáváno, slíbeno – a doufejme, že i naplněno –
v hierarchii mezipamětí cache, považované obecně za problém
Bulldozeru a následníků. AMD v zveřejněném popisu
Zenu avizuje notná zlepšení. L3 má údajně mít celkově
pětinásobnou propustnost (dohromady pro všechna jádra), L1 a L2
cache údajně dvojnásobnou, což je už kapacita pro jediné jádro.
Lepší má být údajně latence i prefetching.
Kapacity a asociativity již známe
z minula, nicméně pro připomenutí: L1 je tradičně
rozdělená na datovou a instrukční část. Instrukční L1 má
64 KB (jako v K7–K10) a je čtyřcestně asociativní,
jádro z ní může číst 32 bytů za takt. Datová L1 cache má
poloviční kapacitu (32 KB), ale asociativita je osmicestná (opět
platí, že čím více, tím lépe, umožňuje to flexibilněji
kombinovat přechovávaná data). Podporuje dvě 128bitové (16 B)
čtení či jeden stejně velký zápis. Tyto šířky jsou
optimalizovány pro instrukce SSE, podobně jako FPU, 256bitové
cesty by byly náročnější na spotřebu. Důležitá změna je, že
L1 datová cache je nyní opět lepšího typu „write-back“,
nikoliv jednoduší „write-through“ Bulldozerů. To vylepšuje
výkon zápisu jak pro L1, tak pro L2 cache.
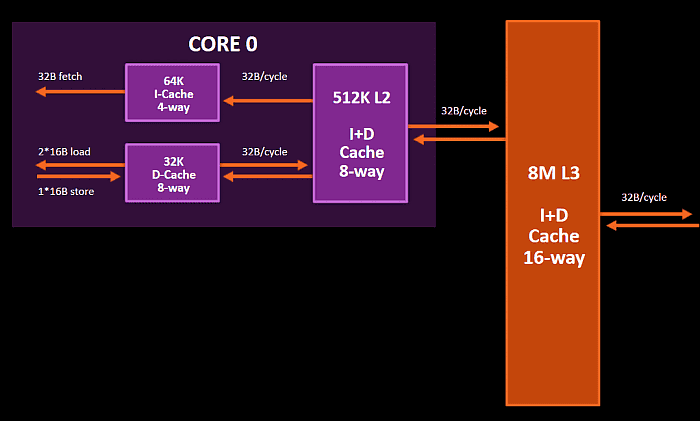
Hierarchie pamětí cache v Zenu
L2 cache komunikuje s L1 cache
rychlostí 32 bytů za takt, totéž pak s L3 cache. L2 je
stejně jalo L1 privátní pro každé jádro a má kapacitu 512
KB, což je návrat k architektuře K10 čipů Phenom I a II
a dvojnásobek proti 256KB L2 jader Nehalem až Skylake od
Intelu. Asociativita je osmicestná. L3 cache je již sdílená
a šestnácticestně asociativní, její kapacita je 8 MB.
Není inkluzivní, jde o tzv. „victim cache“, do níž
putují data, která jednotlivá jádra vyhodila ze své L2. Pro
účely celkové kapacity pro data se tedy kapacity L2 a L3
sčítají.
Základní jednotka: Core Complex
S L3 cache úzce souvisí
organizace jader v celém procesoru. Bylo řečeno, že L3 je
sdílená, důležité ovšem je dodat, čím vším sdílená.
Architektura Zen organizuje jádra do základní stavební jednotky,
tzv. „CPU Complexu“ či „Core Complexu“ (CCX). Tento základní
stavební prvek, jenž je vidět i na pokoutně
uvolněném snímku čipu z května, je složen ze čtyř
jader a jedné L3 cache. Čtyři bloky, z nichž je
složena, mají pro jednotlivá jádra různou přístupovou latenci
dle „vzdálenosti“, zprůměrovaně je ale latence pro všechna
jádra stejná a každé jádro má přístup do celé kapacity.
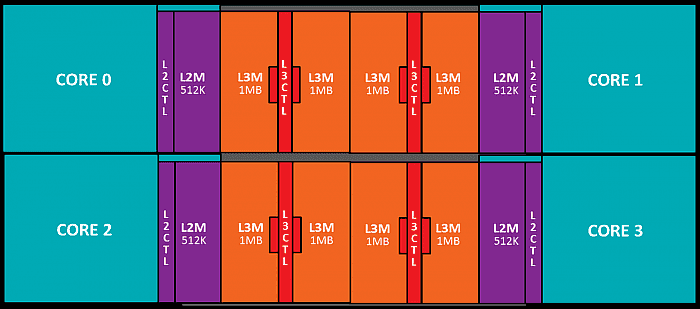
Core Complex (CCX), stavební základ procesorů architektury zen
Pro potřeby řízení spotřeby má L3
cache separátní taktování, v čipech patrně poběží na
odlišném taktu proti jádrům. Ta by v rámci jednoho CCX měla
mít zdroj taktu společný, takže CPU bude měnit frekvenci těchto
čtyř jader naráz. Pokud některá jádra nebudou vytížená,
budou pro zmírnění své spotřeby používat techniky jako clock
gating.

Čipy Summit Ridge na nerozřezaném waferu. Dvojice CCX je dobře vidět
Již víme, že desktopový čip Summit
Ridge bude mít jader osm, zatímco připravované
APU Raven Ridge čtyři. Druhý čip tak bude mít jen jeden CCX
a jednu L3 cache, ovšem Summit Ridge bude složeno ze dvou
těchto jednotek. To znamená, že toto osmijádro má L3 cache
o celkové kapacitě 16 MB, avšak ve dvou částech. AMD nám
potvrdilo, že obě CCX na čipu komunikují vnitřní propojovací
logikou procesoru (která je koherentní), na níž „sedí“ také
paměťový řadič, severní/jižní můstek a další
komponenty. Do L3 cache druhého komplexu tedy jádra nevidí, musí
si data z ní vyžádat a přesunout k sobě podobně
jako ve víceprocesorovém systému.
SMT: někdy se vlastní cesta nevyplácí
Nakonec povídání nám zbyla věc,
která bude na Zenu možná jedna z těch nejpřelomovějších,
tedy podpora pro zpracovávání dvou vláken v jednom jádře.
AMD tuto schopnost dle obecných zvyklostí nazývá SMT (Simultaneous Multi-Threading), od Intelu
ale tuto techniku známe jako HT neboli Hyper Threading (měla ji Pentia 4, in-order
Atomy a od Nehalemu všechna „velká jádra“ Intelu). SMT
dokáže zvýšit celkový výkon podávaný procesorem a čipu
umožňuje konkurovat hypotetickému podobnému CPU s větším
počtem jader, avšak bez SMT.
SMT využívá toho, že plně vytížené
superskalární jádro nevyužívá téměř nikdy všech výpočetních
kapacit, některé zůstávají volné. Tento nevyužitý výkon je
možno částečně dostat zpět – často jde o desítky
procent navíc – pokud čipu umožníte zpracovávat instrukce
paralelně ze dvou vláken. Efektivní je to zejména širokých
jádrech s potenciálně vysokým IPC, Zen se čtyřmi ALU
a čtyřmi pipeline v FPU je tedy dobrým kandidátem.
AMD představilo některé aspekty
toho, jak bude jeho implementace SMT fungovat. Zen podporuje stejně
jako Intel dvoucestný SMT. Podle slajdů by všechny komponenty
jádra měly být sdílené. Vlákna tak nemají některé jednotky
zduplikovány pro sebe a při deaktivovaném SMT může jedno
vlákno používat zcela všechny zdroje. Velká část komponent je
sdílena „kompetitivně“ bez staticky přidělených částí,
takže co nevyužije jedno vlákno, může sebrat druhé – to
je příklad například schedulerů, vykonávacích jednotek, cache,
dekodérů či registrů. Napevno rozdělené jsou při SMT jen
fronta Retire, Micro-Op Queue a fronta zápisů. Důvodem je, že
jejich dynamické rozdělení by příliš zvýšilo komplexnost
jádra.
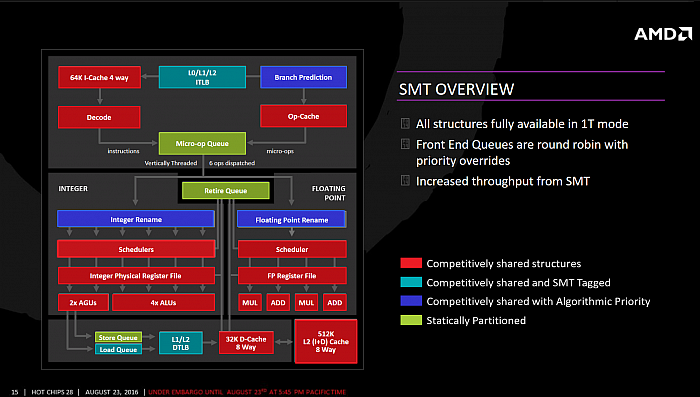
Charakter sdílení bloků při aktivním SMT (Hot Chips 28)
Některé struktury (TLB, fronta čtení)
použávají „tagování“ jednotlivých vláken, čímž lze jednomu či druhému udělit prioritu. Pro část bloků je pak využito sdílení,
kde procesor rozdělení prostředků aktivně řídí určitými
přednastavenými algoritmickými prioritami a může tedy první nebo druhé
vlákno zvýhodnit tak, aby byl zajištěn lepší celkový výkon (například pookud je třeba se rychle zotavit ze špatně odhadnutého větvení).
Tyto priority se týkají například sekce Dispatch, rozdělující
práci do jednotlivých schedulerů, nebo prediktoru větvení. Tento systém ovšem není propojen s prioritami procesů, které
přiděluje operační systém na softwarové rovině, což by snad měly umožňovat struktury, používající tagování.
SMT je poměrně fundamentální změna
proti rodině Bulldozer. Ta byla také zaměřena na zvýšení
vícevláknového výkonu, ovšem modulární architektura také
zvaná „CMT“ to realizuje sdílením prostředků a replikací
jiných, čímž dokáže zvýšit počet jader možných v určité
ploše křemíku. Nevýhoda je, že přístup CMT poškozuje
jednovláknový výkon, jednotlivá jádra jsou totiž slabší.
Použitím jednoho velkého jádra, které dynamicky mohou sdílet
dvě vlákna, se ovšem podpoří zároveň jak celkový výkon pro
obě jádra, tak i výkon pro jediné vlákno. SMT tedy
uspokojuje oba kardinální požadavky a Zen by díky němu měl
být podstatně všestranější než Excavator. Zároveň se tím značně přiblíží Intelu, který tento recept používá léta.
Výhled na reálný úspěch?
Není možné ještě architekturu Zen
nějak zodpovědně zhodnotit jen z těchto „papírových“
parametrů, jelikož výkon čipu může omezovat spousta faktorů,
které nelze snadno předvídat. Čistě z popsaných vlastností
tedy nelze příliš usoudit, jak konkurenceschopný Zen bude. Lze
asi říct, že AMD má potenciál ke slušnému IPC. Čtyři ALU
například odpovídají Haswellu, Broadwellu či Skylake.
Některé slabiny se však předpokládat
dají. V prvé řadě je procesor se svými 128bitovými
datovými cestami a FPU stavěn na práci s instrukcemi
SSE–SSE4. S instrukcemi AVX je kompatibilní, optimalizovaný
kód by však nejspíš měl běžet jen stejně rychle jako za
použití SSE, jelikož vektor je sice dvojnásobný, ale generuje
dva Micro Opy, jako dvě instrukce SSE. Zen tedy asi pomocí AVX či
AVX2 nezrychlíte, na druhou stranu to může kompenzovat
efektivnějším zpracováváním kódu v SSE, jenž je dnes
mnohem častějším úkazem. V tomto ohledu ukáží více
benchmarky jako enkodér x265.

Architektura AMD Zen (Hot Chips 28)
Zatímco IPC by díky šířce jádra
a implementaci SMT navrch mohlo nabývat slušných hodnot, je
třeba dávat pozor na to, že tato charakteristika nedělá výkon
sama, absolutní „rychlost“ je vázána zároveň na frekvenci.
Právě frekvence by mohla být slabinou Zenu ve srovnání
s architekturami Intelu, které se během let vývoje vyšplhaly
na takty nad 4,0 GHz (alespoň u top modelů). To, jak je
zvýrazňována rovnováha v návrhu architektury, by mohlo
znamenat, že Zen bude mít potenciál k dosazžení vysoké
frekvence horší, právě výměnou za větší efektivitu, menší
komplexnost, či další faktory.
Inženýrské vzorky osmijader Summit
Ridge se údajně pohybují okolo 3,0 GHz a je možné, že
firma zvolila jako cílové optimum této architektury právě
hodnotu někde v této oblasti. To se může zdát jako hloupost
z pohledu desktopových procesorů a zejména, pokud jste
zvyklí přetaktovávat. Ovšem tato „chyba“ může být zároveň
výhodou pro oblast notebooků a serverů, kde se hraje na nižší
frekvence a ani Intel nějak závratných taktů nedosahuje.
Pokud by tedy Zen v tomto praktickém pásmu (dejme tomu 2,8–3,5
GHz) díky nižšímu „stropu“ získal výhodu větší
efektivity, šlo by patrně o dobrou volbu pro tyto dnes
nejdůležitější trhy. V desktopu by pak byl negativně
postižen jen výkon v jednom vlákně, vícevláknový by stále
byl kompenzován vyšším počtem jader proti konkurenčním
Intelům.
Nicméně frekvence, na kterých se Zen
bude reálně prodávat, jsou zatím stále neznámé, a s nimi
i absolutní výkon. V tomto ohledu si na lepší informace
asi ještě počkáme, neboť konkrétní parametry procesorů Summit
Ridge si AMD zatím nechává pro sebe a objeví se asi teprve,
až se přiblíží uvedení. To má dle AMD nastat z kraje roku
2017.

Architektura AMD Zen (Hot Chips 28)
Zdroje: AMD











































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU