


Každý rok teď uvádí ARM nové jádro z výkonnější linie „big“ architektur. Loni to byl Cortex-A76 a také letos přichází novinka, která nese jméno Cortex-A77 – dřívější kódové jméno bylo Deimos. Odhalení této architektury připadlo na nyní probíhající veletrh Computex 2019. Bude sice o něco menšího významu než A76, ale ARM si od ní pořád slibuje razantní nárůst výkonu procesorů asi o 20 %.
Cortex-A77: ARM pokračuje v brutálním tempu každoročního zvyšování výkonu
Cortex-A77 je přímý následovník jádra A76 a měl by z něho evolučně vycházet. Zároveň by rozhraní, jimiž je jádro integrováno do celých procesorů, měla zůstat prakticky stejná, takže by výrobci mobilních SoC měli být schopní velmi rychle aktualizovat své čipy a upgradovat je na jádro A77. Stejně tak zůstává stejná instrukční sada ARMv8.2 a A77 se bude nadále párovat s Cortexem-A55 v roli „LITTLE“ jádra.
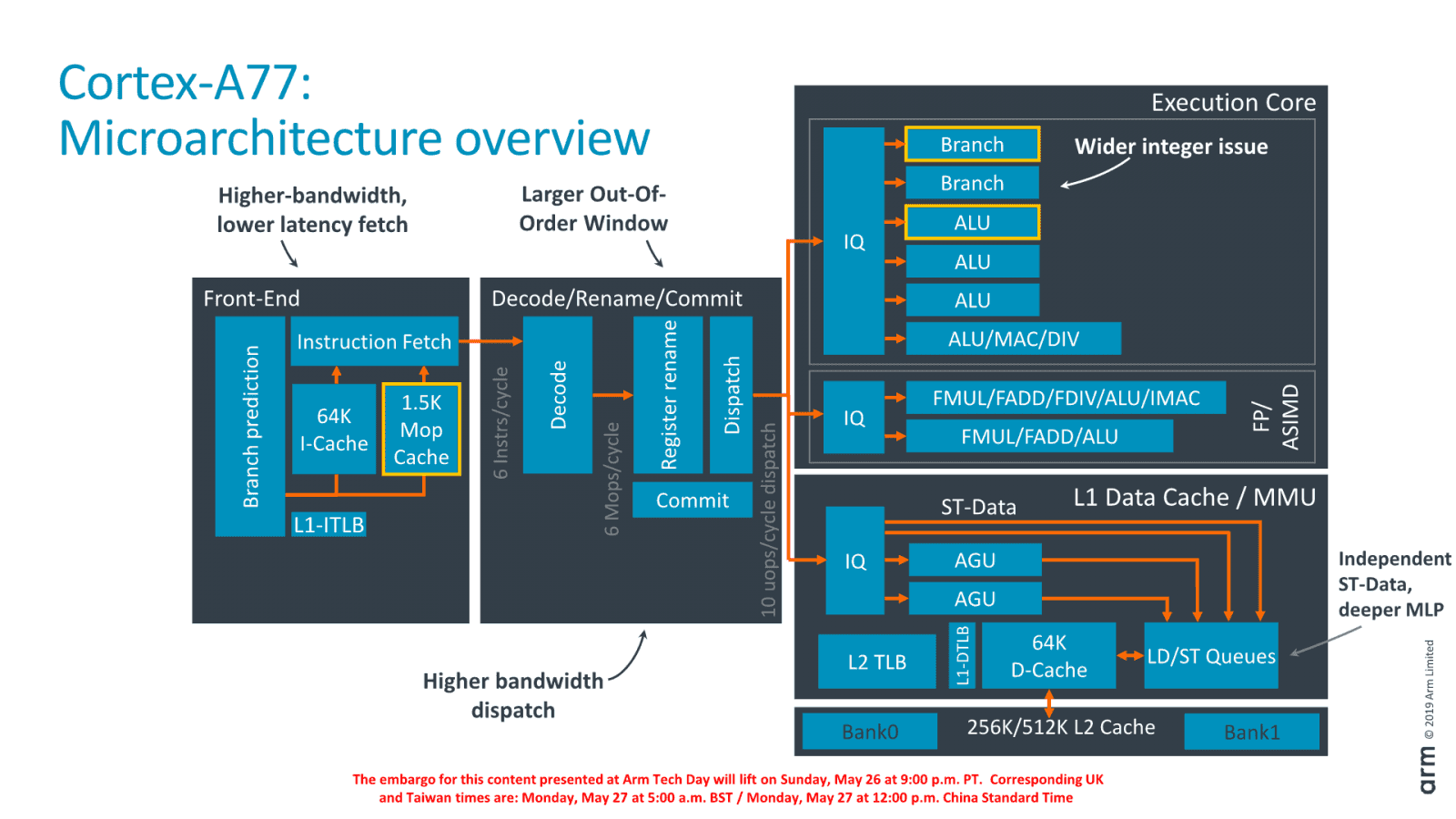
 Celkové schvéma pipeline z prezentace architektury ARM Cortex A77 (Zdroj slajdů: AnandTech)
Celkové schvéma pipeline z prezentace architektury ARM Cortex A77 (Zdroj slajdů: AnandTech)Premiéra: uOP Cache
Cortex-A77 má stejné velikosti pamětí cache (64+64KB L1 pro data/instrukce, 256KB nebo volitelně 512KB L2 cache). Ale velkou změnou je přidání „L0“ neboli uOP Cache (ARM jí říká macro-OP cache), která ukládá již dekódované instrukce. Má kapacitu asi 1500 instrukcí, což je srovnatelné se Skylake. Podle ARMu se až 85 % instrukcí (ve smyčkách například) dá brát z uOP cache, místo aby se musely znovu dekódovat. Instrukce z této cache jsou už po provedení uOP Fusion a z cache jdou v pipeline rovnou do stupně rename. Toto také dokáže v některých případech redukovat cenu postihu za špatně odhadnuté větvení jen na 10 cyklů (u A76 to bylo 11 cyklů). Tato ztráta je u Cortexů A76/A77 jinak velmi nízká v porovnání s jinými jádry. AnandTech uvádí, že u Zenu nebo Skylake je postih 16 cyklů.

Širší a hlubší Out-of-Order zpracování
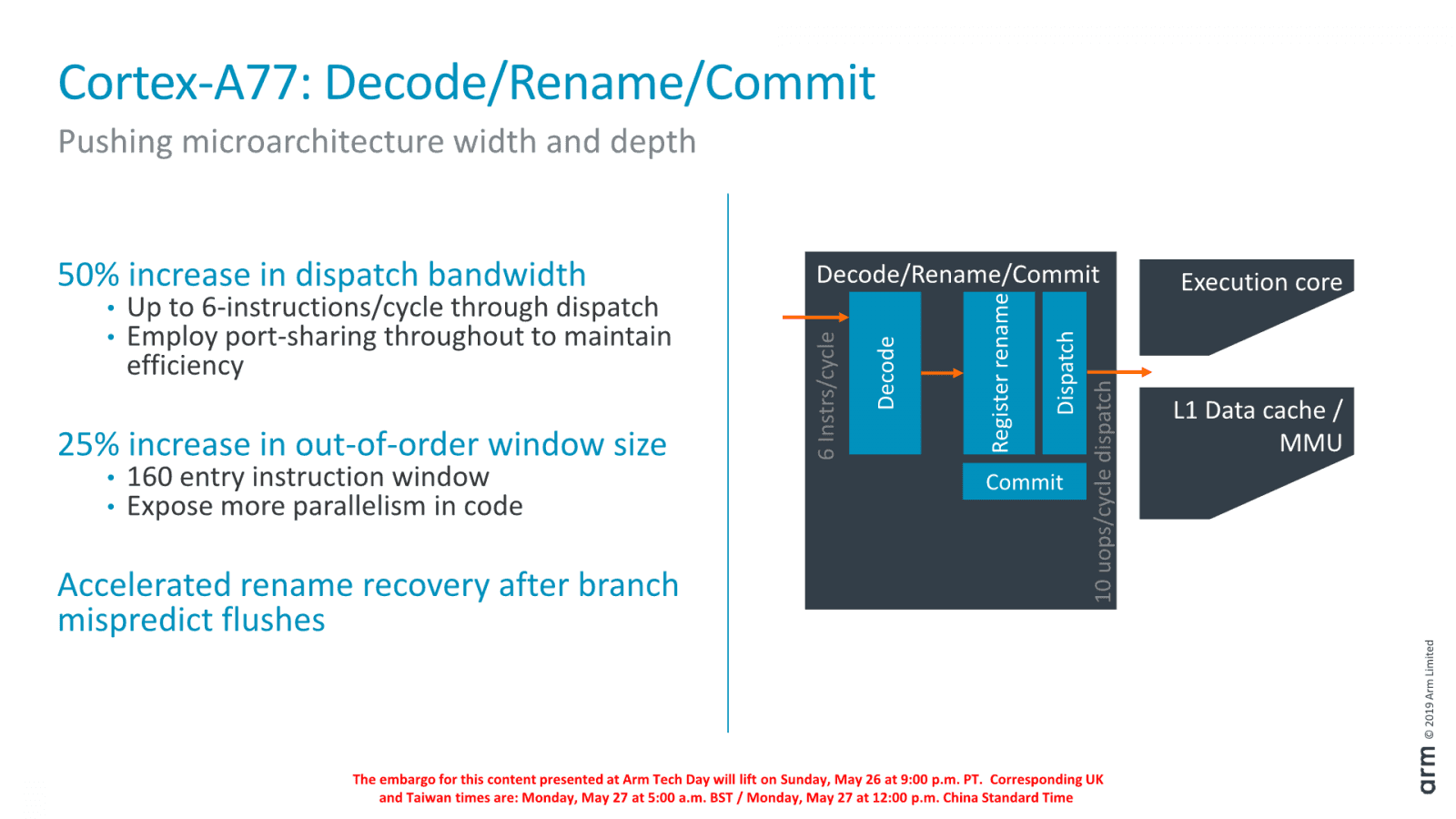
Tato uOP Cache byla zlepšovákem hodně důležitým pro jádra Intel Sandy Bridge nebo AMD Zen, takže potenciálně jde o velkou věc. Zvyšuje množství instrukcí, které může fáze dekódování poslat k dalšímu zpracování, a také energetickou efektivitu. Kapacita dekódování byla zlepšena pomocí uOP Cache. Samotné dekodéry jsou sice stále jenom čtyři, ale teď spolu s uOP cache dokáží poslat dál šest instrukcí místo čtyř, čímž se jádro Cortex-A77 stává hodně „širokým“, ačkoliv ARM stále tlačí na to, aby Cortexy zabíraly co nejmenší plochu na čipu (na rozdíl třeba od Apple).

Schopnost zpracovávat instrukce stylem Out-of-Order byla posílena také zvětšením „okna“, v kterém přehazování může pracovat – reorder buffer („Instruction Window“) se zvětšil ze 128 na 160 položek. Není to mimochodem ani polovina kapacity poněkud extrémního jádra Intel Ice Lake/Sunny Cove (352 položek), ale jádra Cortex se drží snahy dosáhnout maxima možného s méně prostředky.

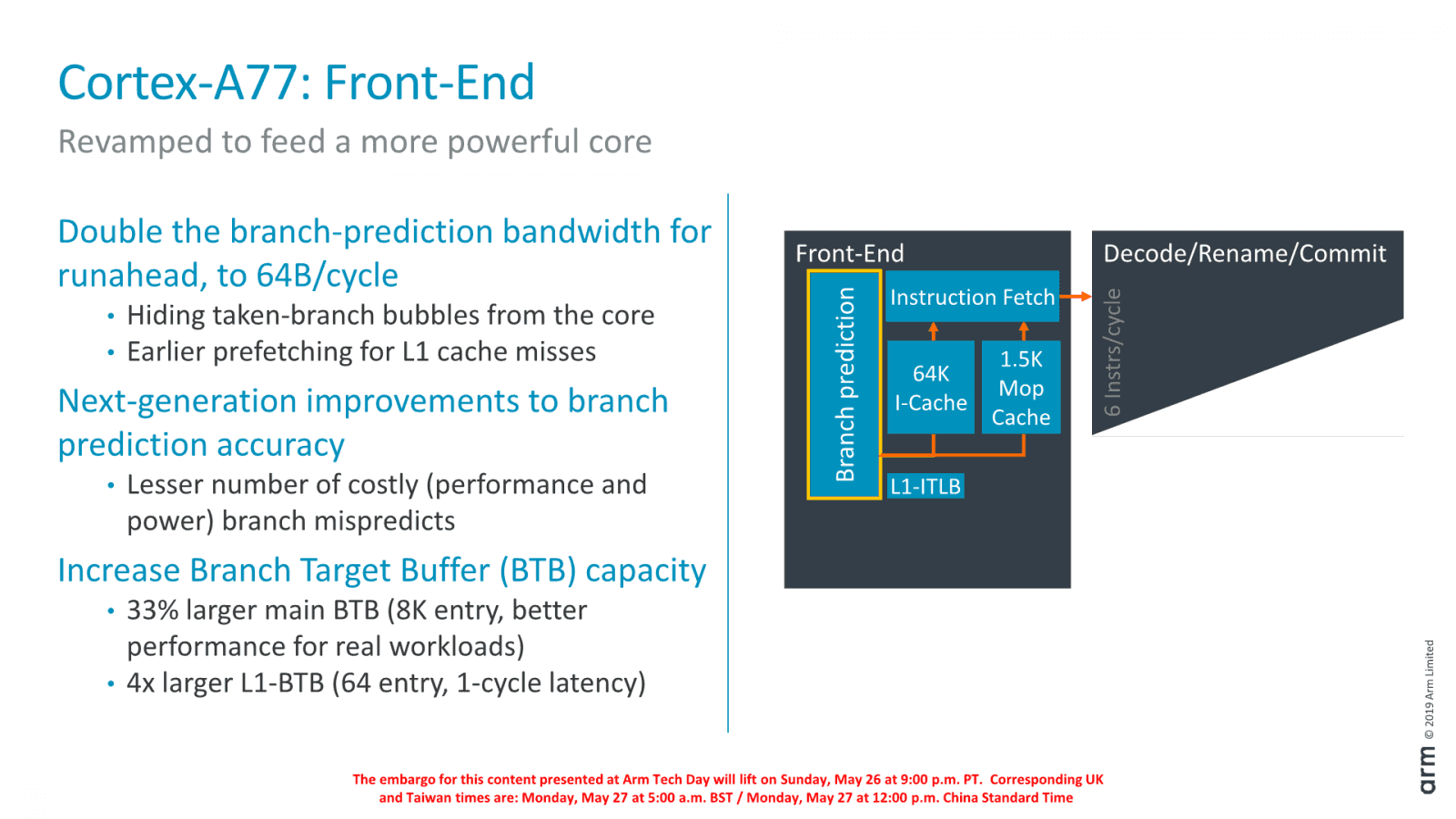
ARM posílil prediktor větvení. Má mít lepší přesnost, jeho buffer se zvětšil z 6000 na 8000 položek. A také byla zdvojnásobená kapacita jeho krmení z 32 bajtů za cyklus na 64 bajtů (16 instrukcí). Cílem toho je, aby se po chybné predikci co nejrychleji znovu rozběhly další fáze zpracování instrukcí, které byly přerušeny.
Rozšíření vykonávacích jednotek
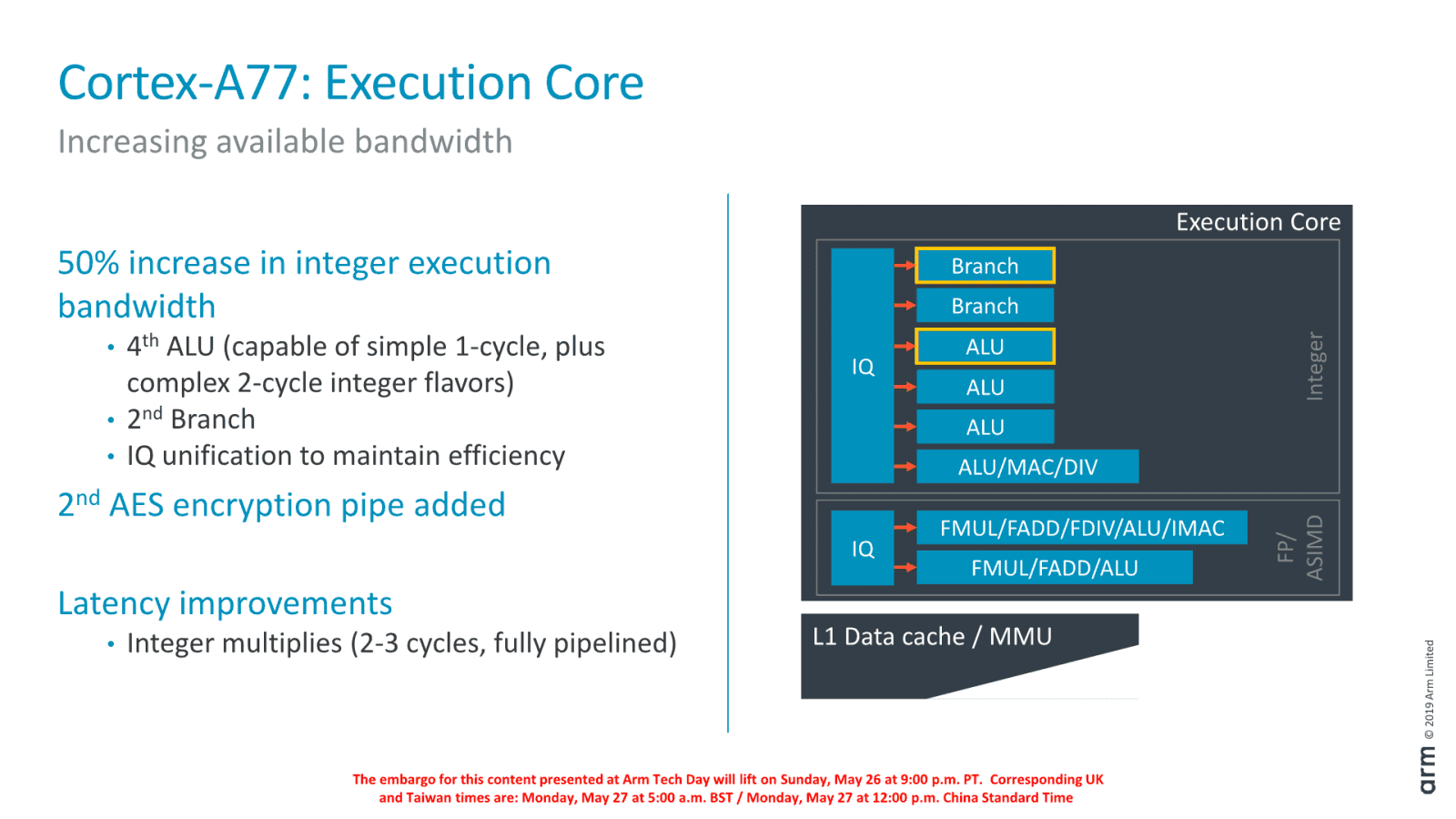
Samotné výpočetní jednotky, které následují za tzv. „frontendem“ byly také posíleny, a to vůbec ne nevýznamně. Cortex-A76 měl stále jen tři ALU, ale A77 se pochlapí na čtyři, což je opět srovnatelné třeba s AMD Zen. Jde o teoretické zvýšení kapacit o 33 %, tato čtvrtá jednotka umí jednoduché, ale i některé komplexní operace.

Zároveň také přibude druhá jednotka na zpracování větvení. A také jednotka pro akceleraci šifrování AES byla nově zdvojená, takže tyto operace mohou zrychlit až o 100%. Výkon má také zvýšit to, že u celočíselných násobení došlo ke zkrácení latence ze čtyř na dva až tři cykly. ARM jinak také sjednotil „issue“ fronty, dříve separátní pro jednotlivé jednotky (tento design má AMD Zen, naopak Intel má frontu unifikovanou).
FPU/SIMD beze změn
Kde se ale asi neopak nic neměnilo, jsou SIMD/Floating Point jednotky, které zůstávají jen dvě. Výpočetní kapacita v SIMD kódu tedy teoreticky zůstává stejná, ale nějaké zlepšení IPC by v těchto úlohách mohly přece jen vytěžit dříve popisovaná zlepšení frontendu.
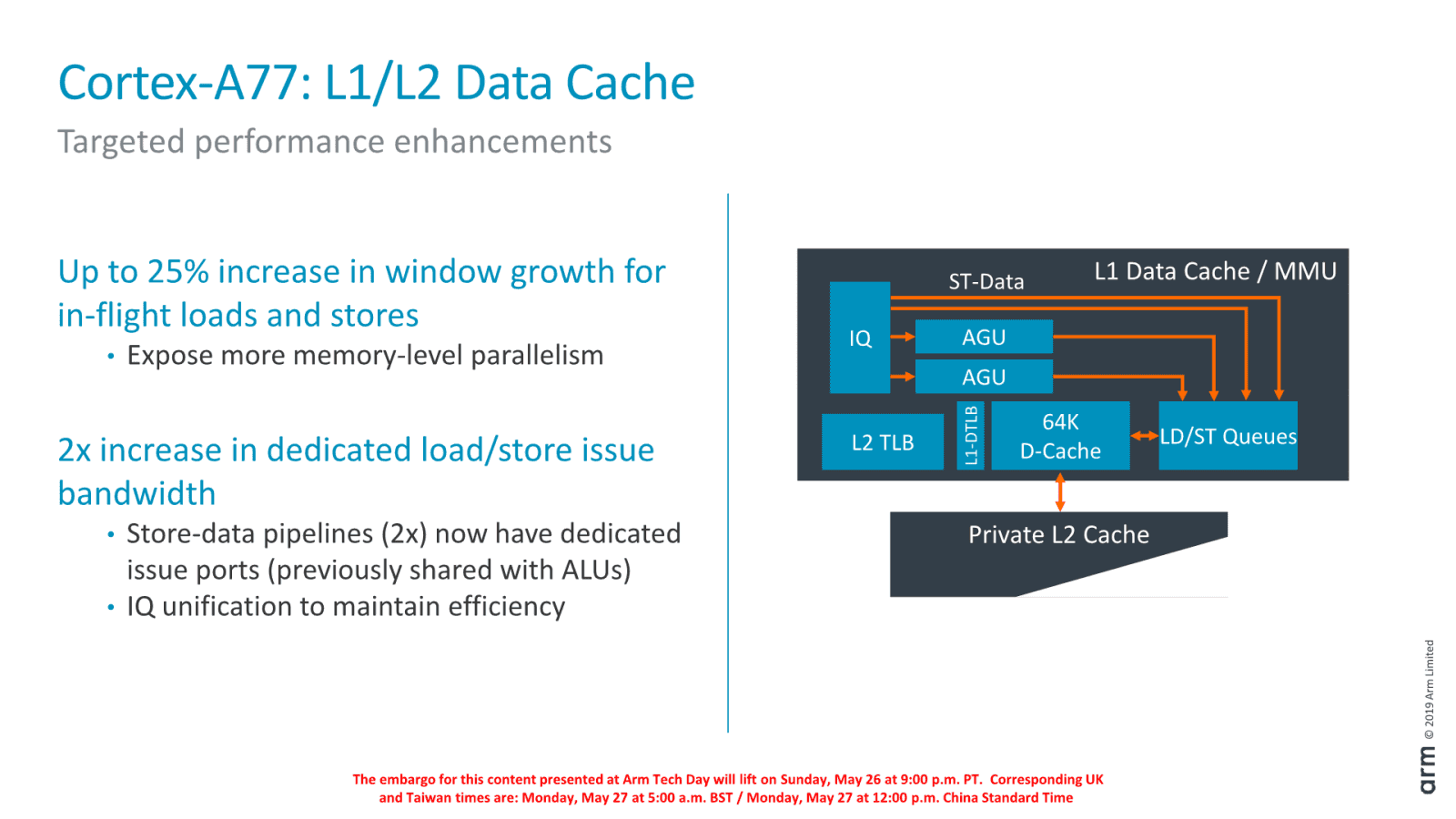
V load/store pipeline má Cortex-A77 nadále jen dvě AGU (podobně jako Zen, například, naproti tomu Intel Sunny Cove má dvojnásobnou kapacitu). Ovšem přibyly k nim dva separátní porty pro operaci ukládání dat (ty předtím zaměstnávaly jednotky ALU). Fronty load/store operací byly údajně také unifikovány a jejich celková hloubka je o 25 % věší. Díky více položkám lez operace efektivněji optimalizovat out-of-order vykonáváním.

Pokročilý prefetch, system-aware prefetching
Vylepšený byl také prefetch, tedy hardwarové automatické přednačítání dat z paměti do cache. Jaké změny to přesně jsou, není jasné, ale už v Cortexu-A76 byla údajně predikce toho, která data bude CPU potřebovat, excelentně účinná a jeho prefetchery tím dokázaly velmi dobře maskovat latenci pamětí v řadě úloh a teď by to snad mělo být ještě lepší. Například se má zvětšit maximální velikost „kroku“, v jejímž rámci bude tento systém schopen rozeznat pravidelná čtení z paměti a data automaticky číst předem, aby byly k dispozici bez čekání.

Kromě toho se prefetchery mají umět přizpůsobit různým výkonnostním parametrům operační paměti, které se u jednotlivých zařízení mohou značně lišit (toto ARM nazývá „system-aware prefetching“). Také by mělo být zohledňováno, jak jednotlivá jádra využívají L3 cache, do které se data prefetchují, aby jedno aktivní jádro neškrtilo ostatní tím, že vyčerpá kapacitu a propustnost pro sebe.
IPC lepší o 20% (i víc)
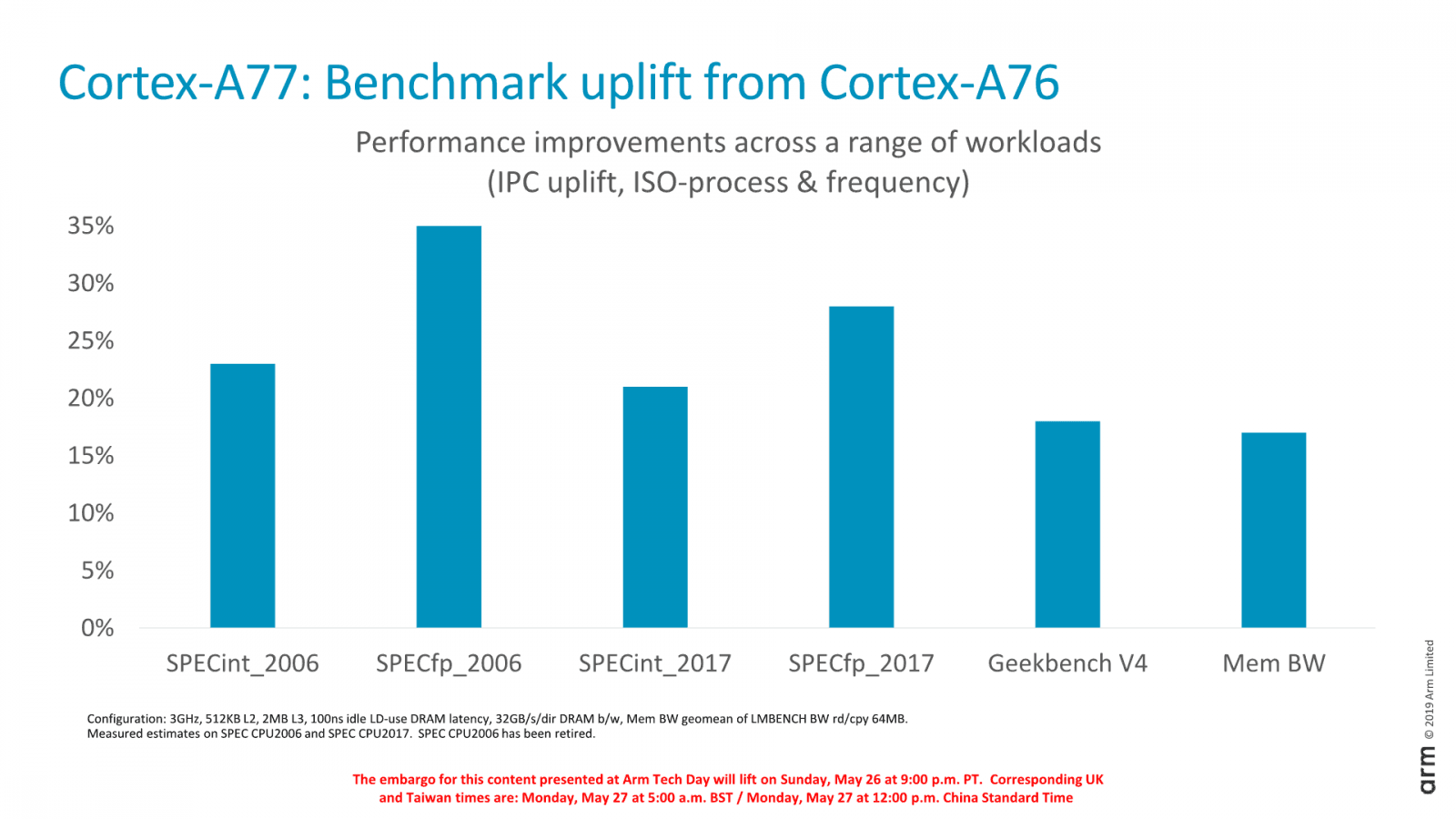
ARM plánoval, že by výkon jader Cortex-A77 proti jádrům Cortex-A76 měl narůst asi o 20 %, což má být převážně dosaženo zvýšeným IPC. Očekává se totiž, že SoC budou stále vyráběny 7nm procesem a přínosy procesu ve formě vyšších frekvencí budou omezené. Očekává se, že frekvence těchto CPU budou končit někde u 3 GHz, jako u A76. Pro srovnání, u Cortexu-A76 sliboval ARM zlepšení výkonu o 35 %, ale tehdy byla započítána i změna z 10nm na 7nm proces a tím zvýšené takty.
Výsledky, které nyní firma uvádí, jsou někde okolo onoho 20% cíle. Jádro má údajně mít o 23 % lepší IPC v SPECint2006, o 35 % lepší v SPECfp2006 (SPEC2006 je hodně závislý na přístupu do paměti, méně na hrubém výpočetním výkonu, proto asi tyto výsledky, ač ARM přímo nevylepšil FPU). Ve SPEC2017 jsou výsledky o něco horší, vypadá to podle grafu na +21% pro SPECint2017 a +28 % pro SPECfp2017). Geekbench V4 má vykazovat zlepšení IPC o asi 18 % a efektivní paměťová propustnost je údajně o 17 % lepší. Tyto výsledky jsou pro 3GHz Cortex-A77 s 512KB L2 Cache, 2MB L3 cache a pamětí s fyzickou/teoretickou propustností 32 GB/s v porovnání s jádrem A76; jde nejspíš o simulaci, nikoliv test na fyzickém hardwaru.

 Projekce toho, jak se u Cortexu-A77 zlepší IPC v různých programech proti Cortexu-A76
Projekce toho, jak se u Cortexu-A77 zlepší IPC v různých programech proti Cortexu-A76Vyšší spotřeba?
Podle ARMU má Cortex-A77 mít stejnou energetickou efektivitu jako A76. Tím se myslí, že na vykonání stejné práce spotřebuje stejně elektřiny. Protože má ale při stejném taktu mít vyšší výkon, znamená toto, že v zátěži bude mít tato novinka vyšší příkon. Jinými slovy, stoupne asi absolutní výkon, ne výkon na 1 W. V telefonech limitovaných nízkým TDP budou tedy tato jádra o něco méně schopná pořádně roztáhnout křídla (pokud budou aktivní třeba všechna čtyři v „big“ klastru). Ovšem toto by nevadilo v noteboocích, kde mají i čtyřjádrové Cortex-A75 (a výhledově A76) velkou rezervu proti typicky 15W procesorům x86. Nemluvě už třeba o serverových aplikacích.
 5G ARM SoC MediaTek s modemem Helio M70
5G ARM SoC MediaTek s modemem Helio M70Primární využití ovšem bude tradičně v mobilních zařízeních s Androidem, to se asi nezmění. SoC s těmito novými jádry by se měl objevit od všech hlavních výrobců pravděpodobně začátkem příštího roku nebo ještě koncem tohoto. V poslední době šlapal na plyn nejvíce HiSilicon, jenže jeho mateřská Huawei je teď pod sankcemi a ARM s ní přerušil spolupráci. Těžko říci, zda byl čip Kirin s jádry Cortex-A77 v té chvíli už dostatečně hotový, aby ho Huawei mohl teď začít vyrábět (a poté používat v telefonech bez softwarové a další podpory a asistence ARMu). Pokud by tato rána od současného Bílého domu HiSiliconu znemožnila vydání, pak bude asi prvním uživatelem této nové architektury nový Qualcomm Snapdragon (865?). MediaTek již stihl oznámit, že bude mít Cortexy-A77 v 7nm čipu s 5G modemem Helio M70, ale jeho uvedení je ještě asi také vzdálené.














































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU