
Konec ATI, zmatky kolem ostrovů a Barts na scéně
R.I.P. ATI
Array Technologies Incorporated, prezentovaná pod logem
„ATi“, byla založena před 25 lety, v roce 1985. O 19 let později (u
příležitosti vydání Radeonu X800 roku 2004) bylo logo upraveno z „ATi“ na „ATI“.
Za další dva roky se z názvu společnosti stala obchodní značka patřící do
arzenálu AMD, které ATI odkoupilo. V letošním roce dospělo vedení AMD
k závěru, že po čtyřech letech je již mezi lidmi přesun ATI pro značku AMD
zažitý natolik, že není potřeba grafickou divizi vymezovat logem původní firmy
a z ATI Radeonů se tak stávají AMD Radeony. Když už jsme u letopočtů,
nebude na škodu zmínit, že značka Radeon oslavila letos v dubnu své desáté
výročí (a doufejme, že ne poslední).

Samotná informace o tom, že ATI jako značka končí, vyvolala
mnoho diskusí jak mezi uživateli diskusních fór, tak i u partnerských firem
AMD. Ač se názorová různorodost objevovala v obou táborech, uznaly
v podstatě oba, že jak řadoví uživatelé tuto změnu přijmou, bude záležet
hlavně na tom, jak na ně zapůsobí nové produkty.
Northern Islands, Southern Islands...
O rodinách čipů „Northern Islands“ (NI) a „Southern Islands“
(SI) se začalo mluvit už před dvěma lety, kdy se na veřejnost dostala roadmpama
AMD s produkty označenými zkratkou „NI“, které měly být vyráběné 32nm
procesem. Tyto čipy měly být následovány generací SI vyráběné na 28nm procesu.
TSMC ale plány na 32nm výrobu zrušilo, a tak nezbylo,
než přichystané návrhy čipů upravit pro 40nm proces. V souvislosti
s tím byly čipy přejmenované na „Southern Islands“
Na přelomu jara a léta inženýry napadlo, že nedává smysl,
aby čipy s názvem SI (které měly být podle původních plánů vydány až po NI)
vyšly jako první, takže byly 40nm čipy (současné HD 6xxx) přejmenovány
zpět na NI. A 28nm čipy se budou jmenovat SI, jak bylo plánováno původně.
Z rodiny NI budou letos vydány tři produkty: Barts
(ostrovy svatého Bartoloměje, současný Radeon HD 6800), Cayman
(Kajmanské ostrovy) a Antilles (Antily, duální karta).
Barts: Radeon HD 6800
Od vydání prvního unifikovaného čipu ATI (R600 / Radeon
HD 2900) uplynulo tři a půl roku, během kterých se toho hodně
změnilo. Změnila se obchodní strategie (namísto velkých riskantních čipů musela
ATI vinou prohry s R600 sázet „na jistotu“ a zaměřit se na střední segment
trhu), změnilo se vedení a změnila se i strategie vývoje.

Namísto architektury, která by byla vyvíjená prakticky od
nuly a která by měla sloužit po několik let, než ji nahradí další zcela
nová architektura, byl preferován méně riskantní a rychlejší způsob
vývoje. Každá další generace produktů inovuje zhruba polovinu čipu a další
generace nahradí zase tu zbývající. Čip R600, který sice nebyl úspěšný jako
produkt, byl konceptuálně v mnoha ohledech předimenzovaný, umožňoval
snadnou adaptabilitu nových standardů. RV670 (HD 3800) přinesla úpravy
potřebné pro kompatibilitu s DirectX 10.1, RV770 (HD 4800)
přinesla změny funkční (odlehčené texturovací jednotky, výkonnější ROP a
restrukturalizaci systému texturingu, UVD 2.0). RV870/Cypress (HD 5800) přinesl
opět kompatibilitu s DirectX 11. Cílem čipu Barts byly opět především
změny funkční.
AMD je mimo základní parametry čipu poněkud skoupá na
přesné detaily ohledně provedených změn, nicméně následující rozdíly jsou
jisté:
- upravené
texturovací jednotky (kvalitnější anizotropní filtrace) - upravený
front-end čipu (souvisí mj. s teselací) - dva
UTDP procesory (efektivnější rasterizace a práce s menšími polygony) - změny
na úrovni SPs (nespecifikované, uspořádání zůstává 5D) - snížena
spotřeba ve 2D (o 8 W proti HD 5870) i ve 3D (o 37 W proti HD 5870) - UVD
3.0 (akcelerace 3D videa, plná akcelerace MPEG2, DivX, Xvid, MVC...) - DisplayPort
1.2 s podporou MultiStream (až šest LCD na dvou výstupech) - HDMI
1.4a (3D video)
Tyto novinky jsou doplněny i řadou změn softwarových,
které více či méně navazují na změny v architektuře čipu:
- Catalyst
AI surface optimizations (kontrola nad FP formáty v DX9 hrách) - Catalyst
AI texture filtering quality (přístupné nastavení kvality filtrace textur) - Morphological
anti-aliasing (AA i ve hrách, které ho neumožňují, např. UE3) - v přípravě:
Eyefinity 5x1 „portrait“ (konfigurace pro pět LCD „nastojato“) - v přípravě:
vylepšení pro HydraGrid (rozvržení pracovní plochy)
K těmto (softwarovým i hardwarovým) změnám se
podrobněji dostaneme v následujících kapitolách. Prozatím se můžeme
podívat na rozdíly v základních číslech:
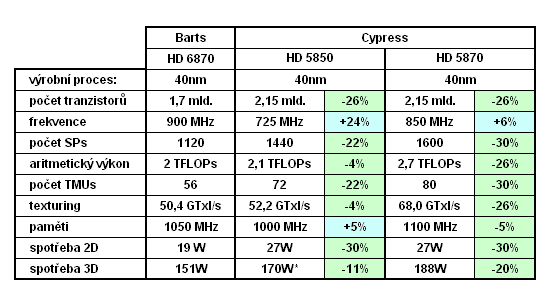 Poznámka: spotřeba HD 5850 byla převzata
Poznámka: spotřeba HD 5850 byla převzata
z oficiálních materiálů k příležitosti vydání HD 5800.
V nové prezentaci je uveden (zřejmě omylem?) údaj 151 W, totožný jako
u HD 6870
V tabulce je znázorněno srovnání čipu Barts
(v nejvýkonnější konfiguraci: HD 6870) oproti svým předchůdcům včetně
procentuálních rozdílů, o které se jednotlivé parametry liší. Ve srovnání
s HD 5870 bylo množství SPs a texturovacích jednotek sníženo
o 30%, frekvence zvýšena o 6%, takže celkový hrubý výkon poklesl
o 26%. Zlepšena ale byla efektivita.
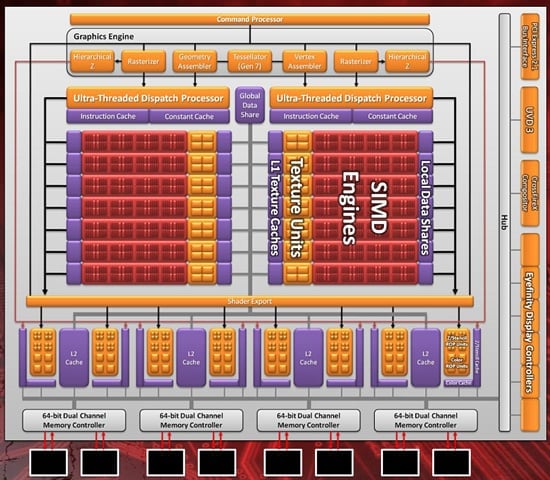
Diagram čipu Barts
(HD 6800) – kliknutím zvětšíte
Ještě než se na ní podíváme blíže, si můžete prohlédnout
základní diagram čipu. 3D jádro je (stejně jako u Radeonů HD 5800)
rozdělené na dva bloky, z nichž každý nese stejný počet SIMDs. Těch bylo
v případě HD 5870 deset, přičemž HD 6870 jich nese sedm (absenci
tří částečně dorovnává vyšší efektivitou a frekvencí).
ROP zůstaly po funkční stránce i kvantitativně beze
změny (32).
Efektivita, teselace
Efektivita
Jedním z hlavních limitů architektury Evergreen/R8xx
(Cypress/RV870) byl front-end čipu. Ač byl oproti Radeonu HD 4890 počet
všech funkčních jednotek zdvojnásoben, celkový výkon Radeonu HD 5870
vzrostl zhruba o 50%. Někteří uživatelé se mylně domnívali, že limitující
byla paměťová sběrnice, ale nebylo tomu tak.
Dalo by se říct, že šlo o skupinu souvisejících prvků, které
vzájemně snižovaly potenciál zbytku čipu. Jedním z těchto problémů byla
rasterizace, jejíž omezení souviselo s generováním vláken (čip nemohl
rasterizovat rychleji bez efektivnějšího – dalo by se říct jemnějšího –
zacházení s jednotlivými vlákny kódu). Tento problém do jisté míry souvisí
i s teselací (které je věnována následující kapitola).
Hlavní změna, která má na svědomí vyšší efektivitu jádra, je
zachycena i na diagramu níže: HD 5800 (Cypress) nesla jeden Ultra Threaded
Dispatch Processor (UTDP), který řídil oba výpočetní bloky. Oproti tomu
HD 6800 (Barts) má pro každý výpočetní blok samostatný UTDP procesor
(včetně příslušné cache), což umožňuje dosáhnout celkově vyšší efektivity,
kterou AMD popisuje trochu nepřímo jako výkon nad Radeonem HD 5850
s úsporou 25 % křemíku.
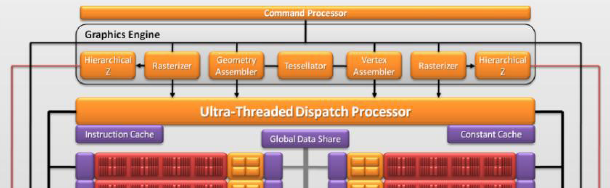
Front-end čipu Cypress (HD 5800)
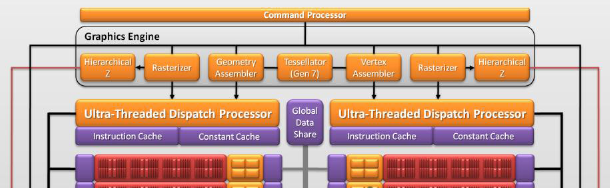
Front-end čipu Barts (HD 6800) – 2× UTDP a oddělené
cache.
Velmi diskutovaným tématem je poměr výkonu a spotřeby.
V tomto ohledu si je AMD poměrně jistá - chlubí se nejvýkonnějším
produktem na trhu. I kdybychom vzali v potaz Radeon HD 6870 (TDP
151 W), který je výkonnostně vcelku blízko Radeonu HD 5870 (TDP 188 W),
jde téměř o čtvrtinové zlepšení (samozřejmě v závislosti na konkrétní
aplikaci). S ohledem na stejný výrobní proces obou čipů je to poměrně
slušný rozdíl.
AMD bohužel nezmiňuje, jakým způsobem dokázali snížit
klidovou spotřebu o 30 %. Domívám se, že nově implementovali GDDR5
undervolting, tzn. snížení napájecího napětí paměťových modulů (dosud byla
pouze regulována jejich frekvence v několika krocích). GDDR5 undervolting
není ale úplnou novinkou, podporuje ho již konkurenční GeForce GTX 460
(GF104) a GTS 450 (GF106).
Teselace
V poslední době je geometrický výkon velmi diskutovaným
tématem. Abychom si udělali představu o rozdílech v implementaci mezi
oběma konkurenty, začnu malým srovnáním:
Oproti Cypress (RV870 / HD 5800) nese Fermi (GF100) 4x
více triangle setup jednotek, dvojnásobek rasterizérů (i když s polovičním
výkonem), 16 polymorph enginů a zároveň zvládá ještě docela efektivně nakládat
s cca 4 pixelovými polygony, zatímco pro Cypress (RV870) jsou vhodnější větší
8-16 pixelové polygony (limitace rasterizérem).
Cypress (RV870) je schopen zpracovat jeden polygon za takt
bez teselace. Při teselaci je limitovaný na jeden polygon za tři takty, tzn.
geometrický výkon klesá na třetinu.
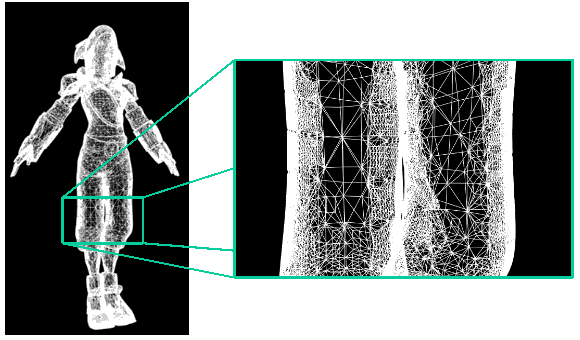
Na základě těchto rozdílů se mnoho lidí domnívá, že
teselátor čipu Cypress není dostatečně výkonný, a proto limituje výkon. To ale
není úplně pravda, pokusím se to vysvětlit na příkladu:
Řekněme, že používáme rozlišení 2048 × 1536 tzn. plochu o 3
145 728 pixelech.
Pokud bychom měli teselací polygony rozložené na
trojúhelníky o rozměrech 3 pixely v průměru, dostáváme tím
1 048 576 trojúhelníku ve scéně. Pro 60 fps (60 scén za vteřinu) by bylo třeba vykreslit 63 milionů trojúhelníků
za vteřinu. Budeme-li počítat s trojnásobným overdraw faktorem, je to 189
milionů t/s.
Radeon HD 5870 zvládá s teselací zpracovat teoreticky až 283 milionů
trojúhelníků za vteřinu. I pro výše popsaný extrémní případ by tedy jeho
teselační výkon měl i s 50% rezervou stačit. Bohužel, realita je
trochu jinde. Problém je v tom, že kvůli limitacím na straně front-endu
(rasterizér, distribuce polygonů…) nedokáže čip geometrický potenciál efektivně
využít.
Logicky se dostáváme k závěru, že na čipu Cypress
nepotřebuje upravit samotný teselátor, jako spíš jeho okolí. Tím je
rasterizace, systém distribuce polygonů a řízení.
Příslušnými úpravami se grafické divizi AMD podařilo zvýšit
teoretický teselační trianglerate z původní 1/3 polygonu za takt na necelý
jeden polygon v jednom taktu (neoficiálně se mluví až o 4/5 polygonu za
takt). Tímto zlepšením je možné reálně dosáhnout až dvojnásobného výkonu, což
je podle AMD dostačující pro současné i chystané hry (AMD argumentuje
faktem, že zhruba 85 % DirectX 11 her je vyvíjeno na HD 5000).
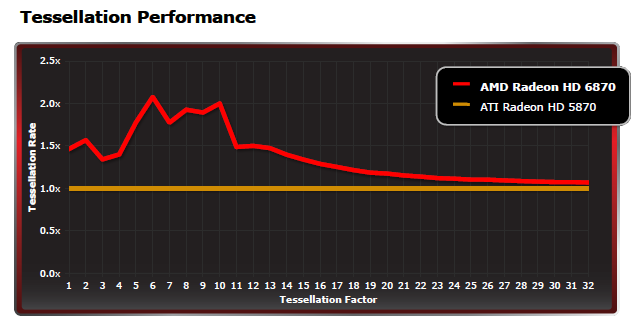
Jak si ale můžete všimnout z výše uvedeného grafu,
výraznější rozdíl ve výkonu se týká pouze nižších teselačních faktorů.
S vyššími faktory (které používají mnohé syntetické testy) bude rozdíl
oproti Radeonu HD 5870 zanedbatelný.
Následuje orientační tabulka, abyste si mohli udělat představu,
na kolik polygonů rozloží teselace původní jeden polygon při různých
teselačních faktorech:
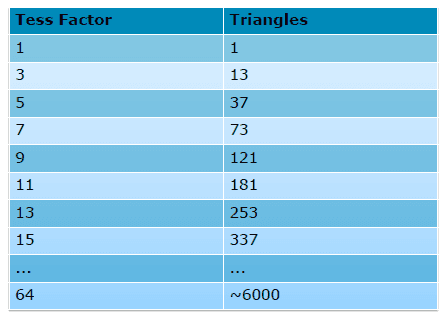
Na základě všech těchto informací se dá říct, že Radeon
HD 6800 zlepší výkon v teselaci spíš s ohledem na hry a dá
se říct mírně, zatímco Radeon HD 6900 přijde s mnohem razantnějším
řešením, které se promítne jak ve hrách, tak v syntetických testech.
Rozsáhlejší rozbor teselace s ohledem na situaci na
trhu, hry a Radeon HD 6900 najdete v samostatné kapitole.
Kvalitnější anizotropní filtrování, Catalyst AI pod kontrolou
Kvalitnější anizotropní filtrování (AF)
Když loni ATI na Radeonech HD 5000 nový režim
anizotropní filtrace, který jako první zcela odstranil úhlové optimalizace,
zdálo se, že je vše v nejlepším pořádku. Během letošního roku se ale
začaly objevovat názory, že ač je nový režim úhlově nezávislý, není zcela
dokonalý, protože se na texturách s pravidelnou vysokofrekvenční kresbou
mohou vyskytnout rušivé zlomy.
AMD se podařilo přechody zlepšit a všechny čipy
generace Northern Islands již ponesou texturovací jednotky s vylepšenou
filtrací. Podle prvních testů jsou výsledky poměrně slibné, výrazně lepší než
u předešlé generace, ale zatím nechci předbíhat – uvidíme až
s odstupem a větším množstvím praktických testů.
| GPU | quality | high-quality |
| R5xx |  |
 |
| R6xx |  |
|
| R7xx |  |
|
| R8xx |  |
|
| Barts |  |
 |
+ nastavení Performance u jádra Barts:

Všechny ukázky v archivu jsou k dispozici ke
stažení zde.
Catalyst AI pod kontrolou
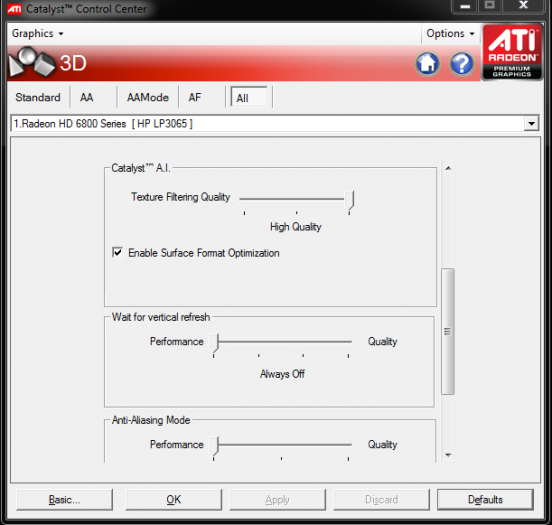
Další novinkou jsou nastavení Catalyst AI. Kvalitu filtrace
textur lze nastavit na „performance“, „quality“ a „high quality“. AMD uvádí, že
při testování doporučuje stejné nastavení, jako v ovládacím panelu Nvidie.
Třetí změnou je položka „Enable Surface Format
Optimization“. Ta se netýká samotné filtrace textur, ale FP formátů.
V době DirectX 9.0c byl jediným FP formátem FP16. Mnohé hry ho využívaly
tam, kde přesnost celočíselného Int8 nedostačovala. V současné době již
DX11 umožňuje používat celou řadu formátů vhodných pro specifické situace. Toho
se ATI před časem rozhodla využít: V některých starších DX9, kde použití
moderních formátů FP10 či FP11 nedegradovalo kvalitu obrazu, těmito formáty
nahradila (přes Catalyst AI) původně použitý FP16. Výhoda spočívá v tom,
že FP10/FP11 zvládají současné Radeony zpracovávat 2x rychleji, což má logicky
pozitivní dopad na výkon, obzvlášť u pomalejších low-endových karet.
Toho se ale chytila Nvidia a informovala recenzenty, že
ATI/AMD tímto způsobem cheatuje a pro dosažení objektivních výsledků
v testech je nutné vypnout Catalyst AI. Nvidia už ovšem recenzenty
neinformovala o tom:
- že
se tato optimalizace týká jen starších DX9 her, které se v recenzích
neobjevují - že
došlo k náhradě jen ve hrách, kde nejsou patrné negativní vizuální změny - že
vypnutí Catalyst AI vypne CrossFire a všechny optimalizace ovladače - Nvidii
tohle vadí hlavně z důvodu, že podobné vylepšení pro starší hry svým
vlastním zákazníkům nabídnout nemůže, protože Fermi umí FP10 / FP11
blending jen stejně rychle, resp. stejně pomalu, jako FP16 blending, takže
by se použití modernějších formátů nijak na výkonu neprojevilo
Jako důsledek této kauzy AMD do ovládacího panelu umístilo
check-box, s jehož pomocí lze tuto funkci vypnout. Pro uživatele to
znamená, že zaškrtnutím položky „Enable Surface Format Optimization“ výkon
v několika starších hrách mírně stoupne a naopak.
Mirek Jahoda: V tomto místě jsem s Jirkou vedl
polemiku a zejména rozdělení rolí na hloupé novináře (co ani netuší, že se s Catalyst
AI Disabled vypne třeba i CrossFireX), tradičně zlou Nvidii a hodné AMD mi v tomto
hodně nesedí. Problémů na texturách ve hrách si všimli i běžní uživatelé
a AMD zvolilo taktiku „zatloukat, zatloukat, zatloukat...“.
V podstatě teprve v textu Jirky Součka se
dozvídáme některá vysvětlení, dalším je ono nové zatržítko v ovladačích.
Nvidia byla ohledně nepoužití FP16 opravdu v roli „bonzáka“, nicméně třeba
Far Cry 2, Resident Evil 5, Warhammer 40,000: Dawn of War II nebo Battlefield:
Bad Company 2 se stěží dají považovat za starší hry, které se v recenzích neobjevují.
Ty další problémy se týkají anizotropního filtrování (které
tedy Barts opět vylepšil) a problémů tam, kde hra nekorektně využívala filtraci
textur a pravděpodobně hardwaru HD 5000 to nesedělo (jelikož třeba v Trackmanii
Nvidia konkrétně tyto problémy alespoň příliš viditelné neměla). Budeme tedy
zvědavi, zda už se Barts popere dobře i s těmito situacemi. Máslo na hlavě
AMD ohledně nevysvětlení problémů s obrazem však zůstává.
Nový anti-aliasing – Morphological AA (MLAA)
MLAA – Morphological anti-aliasing
Často se setkáváme s hrami, ve kterých není možné
standardním způsobem zapnout anti-aliasing. Je to dáno tím, že někteří vývojáři
her nepoužívají standardní postupy renderingu, při kterých je možné standardní
cestou anti-aliasing zapnout, ale používají postupy vlastní a zároveň se
nezaobírají tím, že by k nim bylo potřeba implementovat anti-aliasing.
Typickým příkladem je například Tim Sweeney, který v názoru na AA zaostal
v roce 2000 a čas od času jen utrousí poznámku, že AA je „framerate
killer“ a tudíž mimo jeho zájem. Sweeneyho Unreal Engine 3 (který používá
netypický deferred shading a g-buffers), z tohoto důvodu nepodporuje anti-aliasing.
ATI (nyní AMD) i Nvidia se tuto liknavost vývojářů snaží
napravovat, seč mohou, a přicházejí s různými způsoby řešení či
obcházení v rámci ovladačů, aby si uživatelé v dané hře mohli AA
zapnout. Hráči by si ale měli uvědomit, že nefunkční AA je nedostatkem hry,
resp. jejího vývojáře, který se neobtěžoval s jeho implementací, nikoli
chyba výrobce hardwaru, který napravuje, co neudělal autor hry.

Důsledkem tahanic mezi výrobci pak situace může zajít tak
daleko, jako se stalo se hrou Batman, do níž Nvidia implementovala podporu AA,
kterou ale „uzamkla“ pouze pro své karty. Tím uživatele Radeonů od možnosti AA
odstřihla. Dál tuhle aféru nemá smysl rozebírat, uvádím jí pouze jako příklad
situace, ke které AMD uvedlo (částečné) řešení.
Standardní AA (MSAA) pro svoji funkčnost musí být proveden
v okamžiku, kdy jsou přístupné geometrické údaje. U her založených
např. na zmíněném UE3 je právě tohle problém – když se pixel dostane na úroveň
ROP, už geometrická data neexistují a není jak AA provést.

Zdroj: Practical Morphological Anti-Aliasing
MLAA (Morphological anti-aliasing) funguje jinak.
Nevyhlazuje hrany prováděním dodatečných výpočtů podle geometrických údajů, ale
vezme již hotový vykreslený obraz a pomocí algoritmů detekuje hrany, které
na základě sady vzorů nahradí vyhlazenými hranami. Zjednodušeně řečeno. AMD pro
tento proces údajně používá Direct Compute, tzn. Compute Shader.

Zvětšený výřez
z Aliens vs. Predator
Je logické očekávat, že propady výkonu budou vyšší, než při
běžném MSAA (údajně je výkon lepší než při SSAA a zhruba srovnatelný s CFAA
s edge-detect), ale na druhé straně jsou výhody:
- funkčnost
v jakékoli DX 9/10/11 aplikaci - vyhlazuje
celý obraz, tzn. i transparentní textury (není třeba zapínat transparentní
AA) - na
běžných hranách je velmi účinný
Krom výkonu je negativem snad jen nižší účinnost na
specifické formy geometrického aliasu (např. dráty ve velké vzdálenosti, které
se bez AA jeví jako přerušované, budou přerušované i s MLAA).
Detailní popisy této techniky včetně srovnání s MSAA 8×
najdete v článku Practical Morphological Anti-Aliasing.
UVD 3.0, Eyefinity, ColorMapping a výstupy na monitory
UVD 3.0
Po rodině Evergreen, která podporu přehrávání videa kromě
přidání bitstream processingu bezztrátového audia nijak výrazně nezměnila,
došlo konečně na příjemný krok vpřed a rozšíření podpory akcelerovaných formátů
videa. Nejpodstatnějšími změnami jsou:
- plná
akcelerace MPEG-2 (oproti UVD 2.0 přibyl entropy decoding) - plná
akcelerace MVC (Blu-ray 3D) - plná
akcelerace MPEG-4 (např. DivX a Xvid)
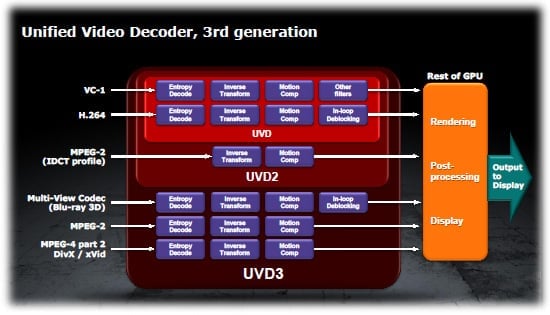
Nový UVD3 a znázornění schopností UVD2 a UVD. Klikněte pro zvětšení.
AMD dál uvádí ještě nové možnosti nastavení, ale konkrétní
položky opět zmíněny nejsou.
ColorRemapping
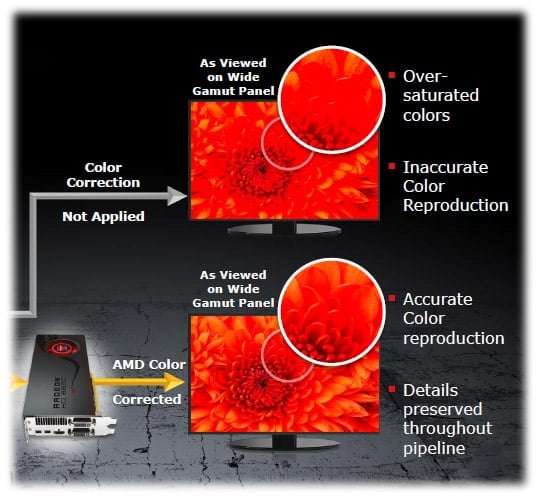
Novinkou je podpora technologie, která je schopna kvalitně
přemapovat sRGB barevný prostor pro wide-gamut LCD, čímž předchází degradaci
barev (známé přesaturované slité barvy)
DisplayPort 1.2
Upraveny jsou i možnosti výstupu. DisplayPort 1.2 podporuje
technologii MultiStream, což umožňuje přenos signálu pro více monitorů přes
jeden konektor. Pro využití této technologie je buďto třeba DisplayPort
(MultiStream Transport) hub, nebo monitor podporující DaisyChain (tzn. že kromě
vstupu má i výstup, ke kterému lze připojit další monitor, a tak
dál). DP 1.2 je díky vysoké datové propustnosti vhodný i pro Stereo 3D
zobrazení (120 Hz).
Díky DP1.2 je možné k obyčejné verzi karty
(ne-Eyefinity6) připojit až šest monitorů. AMD ale dodává, že čip Barts je
pinově kompatibilní s HD 5800, takže výrobci mohou uvést
i klasický Eyefinity6 model se šesti samostatnými výstupy.
HDMI 1.4a
Poslední revize rozhraní HDMI přináší podporu hlavně pro 3D
video (podpora formátu frame-packing).

referenční karty budou
mít výstupy:
- 2× mini DP (DP 1.2)
- 1× HDMI 1.4a
- 1× DVI-I single-link
- 1× DVI-I dual-link
mnohé nereferenční karty
mají možnosti výstupu omezeny na:
- 1× DP 1.2 (namísto dvou mini-DP konektorů)
- 1× HDMI 1.4a
- 1× DVI-I dual-link
- 1× DVI-D (bez možnosti analogového výstupu)

Teselace – loutka marketingu?
Teselace – loutka marketingu?
S vydáním Nvidia Fermi se tak nějak pozapomnělo, že DirectX
11 přineslo řadu nových technologií, které umožňují dosáhnout vyššího výkonu a
lepší kvality obrazu. Nvidia se logicky rozhodla marketingově využít tu,
v níž zvládala výrazně překonat konkurenci a z teselace
v očích zákazníků vytvořila alfu a omegu DirectX 11.
Nicméně je patrné, že se blíží určité vystřízlivění –
marketingová teselační mánie brzy vyjde z módy – podobně jako se stalo i
s mánií okolo PhysX, s HDR před třemi roky nebo s TnL mánií před
mnoha lety. V okamžiku, kdy bude situace vyrovnaná, přestane být teselace
zajímavá pro marketingová oddělení obou výrobců a stane se z ní zcela
běžná technologie, jako každá jiná.
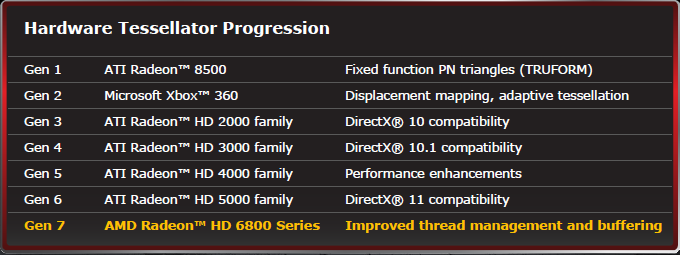
Možná nebude na škodu, když se na celou situaci podíváme
v širších souvislostech. ATI byla teselaci nakloněna už v dobách R200/Radeonu 8500, který používal tzv. Truform (jednoduchá fixní forma teselace).
Tato idea se zamlouvala i Microsoftu, který vyžadoval, aby GPU jejich nové
herní konzole (Xbox 360) podporovalo programovatelnou teselaci, kterou plánoval
uvést jako novinku DirectX 10. Pro ATI nebylo problém teselátor Xenosu
(grafický čip Xbox360) upravit, aby splňoval požadavky DirectX 10, jenže Nvidia
s G80 teselaci prostě neřešila.
Jelikož DirectX 10 bylo první generací
DirectX, které nevyužívalo „cap bits“ a všechny specifikace DX byly pro
hardware povinné, musel Microsoft požadavek na teselaci ze specifikací DX10
vyškrtnout a Nvidii ustoupit. Krom G80 se v podstatě totéž opakovalo
i s G92 a GT200, které rovněž teselaci nepodporovaly. Nyní, po čtyřech
letech ignorování této technologie, přišla Nvidia s čipem, který ji umí.
Doslova přes noc je z teselace zcela nezbytná věc, bez které by hry
nemohly existovat, stejně jako loni bez PhysXu a před pár lety bez HDR.
Na druhou stranu ani ATI na této šarádě není zcela bez viny.
Teselační výkon Radeonů HD 5000 evidentně nebyl takový, jak ATI očekávala
a podceněný front-end čipu dal Nvidii možnost této slabiny využít a na
teselaci postavit kariéru vlastnímu produktu.
Čím to ale je, že Nvidia, která o teselaci dlouhá léta (od dob GeForce 3 a RT-patches) vůbec
nejevila zájem a prakticky bojkotovala její rozšíření, letos obrátila o
180°?
Proslýchá se, že Fermi v počátcích svého vývoje neměla
teselaci podporovat, ale počítalo se s emulací. Nakonec byl ale čip
přepracován do současné podoby, což vedlo k určitému zdržení. Do jaké míry
může být tato informace pravdivá, asi nechám spekulačním diskusím, nicméně
výsledné zpoždění umocněné potížemi s výrobním procesem bylo realitou.
Necelý měsíc před vydáním Fermi, konkrétně na GDC 2010,
ještě Nvidia varuje vývojáře, že používání příliš malých polygonů je
neefektivní a doporučuje jim vyhýbat se polygonům menším než osm pixelů:

GDC 2010 „Tesselation Performance“. Zdroj: Nvidia (developer)
Proč tedy došlo k takovému obratu a Nvidia nyní
propaguje co nejvyšší teselaci a co nejmenší polygony? Odpověď na tuhle
otázku lze najít v základních principech architektury současných
grafických čipů. Teselační výkon není závislý jen na samotném teselátoru, ale
na všech segmentech grafického čipu:
- triangle-setup
(rozhoduje o tom, zda bude teselátor dostatečně „zásobován“) - rasterizace
(jak malé mohou polygony být, aby je čip efektivně zvládal) - shading
(limit efektivity: čtyři pixelové polygony) - ROP/MSAA (čím více polygonů a hran, tím větší zátěž na MSAA a sběrnici)
Pro nás budou v tuto chvíli klíčové body dva a tři.
Shading je v souvislosti s teselací stejným
limitujícím prvkem pro čipy ATI i Nvidie. Všechny současné grafické čipy
pracují s bloky 2 × 2 pixely. Pokud ale teselací vytvoříme polygony, které
budou menší, např. ~1 pixel, zabijeme tím výkon. Důvod je následující:
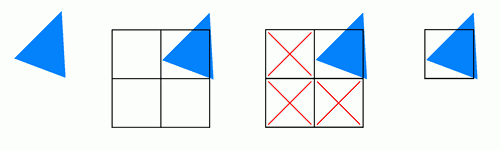
Máme polygon odpovídající jednomu pixelu. Pixel shading ale
pracuje výhradně s bloky 2x2 pixely. V praxi to znamená, že musejí
být zpracovány všechny 4 pixely (tzn. i ty, kterých není třeba), ale
jelikož byla vyžadována jen jedna hodnota, jsou zbývající tři odstraněny,
vyhozeny. Tím dochází ke zbytečnému vyplýtvání 75% výkonu čipu. Jelikož je
toto omezení stejné pro ATI i Nvidii, vysvětluje to sice, proč Nvidia zprvu
nedoporučovala používat polygony menší než osm pixelů, stejně jako ATI – ale
nevysvětluje to, proč později změnila názor.
![]()
Druhým zmíněným limitem je rasterizace. Rasterizér ATI
dosahuje optimálních výsledků, pokud se polygony nedostanou pod 16 pixelů (s
osmipixelovými je efektivita 50 % atp.). Zde narážíme na první rozdíl.
Rasterizér Fermi dosahuje 100% efektivity i s osmipixelovými polygony
a efektivita klesá až dál.
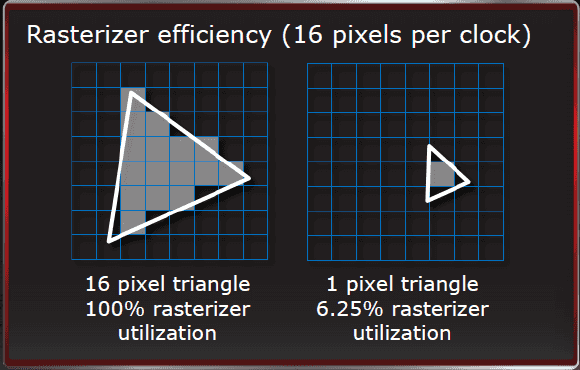
Poslední podstatnou informací je, že čip Fermi, ačkoli má 48
ROP, zvládá na úrovni jádra zpracovávat maximálně 32 pixelů za takt. 32 pixelů
za takt zvládá i Radeon HD 5870. Díky vyšším frekvencím se ale
tento poměr kloní ve prospěch ATI.
Pro Nvidii je tedy výhodné, pokud určitá aplikace či hra je
na Radeonu limitována něčím jiným, než těmito 32 pixely za takt, protože zde má
ATI převahu. A toho lze snadno dosáhnout právě teselací, kde se limity přesunou
jinam. Pokud budou polygony dostatečně malé (~8 pixelů), bude efektivita na
Radeonech skoro poloviční. Pokud budou ale ještě menší (čtyři pixely a méně),
tak sice Fermi i HD 5870 narazí na limit pixel shaderu a výkon půjde
u obou karet citelně dolů (většina výpočtů je „skartována“), ale kvůli
rasterizéru se výkon Radeonu bude propadat čtyřikrát strměji než výkon Fermi.
Pro vývojáře her je sice klíčové dosažení vysokého výkonu,
takže se malým polygonům narážejícím na limit pixel shaderu a rasterizéru budou
vyhýbat, ale pro Nvidii jsou tyto situace z marketingového hlediska velmi
výhodné: Pokud Nvidia použije benchmark, který jde s rozměry polygonů pod
limit pixel shaderu a připraví tak Fermi o polovinu výkonu, je to
marketingově stále výhodné, neboť konkurenci taková situace zmasakruje výrazně
víc a z testu vyjde jako velký vítěz Fermi (pamětníci Diabla II si
možná vybaví strategii s Iron Maiden :-).
Reakce AMD
Na serveru KitGuru se minulý týden Richard Huddy z AMD
rozpovídal na téma teselace a DX11. Podle jeho slov si Nvidia zajistila,
aby některé syntetické testy využívaly teselaci nad rámec vizuálního přínosu
takovým způsobem, aby Radeony prezentovaly ve špatném světle. Huddy
upozorňuje na to, že některé benchmarky zvyšují počet polygonů výrazně nad
úroveň, která se ještě odráží na vizuální stránce a tudíž nereflektují
požadavky reálných her.

Richard Huddy, AMD: „Ve vykonstruovaných testech, jako je
Stone Giant, který byl zaplacen Nvidií, je teselováno na úroveň jednopixelových
polygonů. I přesto ale daný pixel nemůže být oddělen od zbývajících tří pixelů
svého quadu [pozn.: pixely jsou na úrovni hardwaru zpracovávány ve čtveřicích].
Zpracovávat každý pixel ve čtveřici s tím, že ve výsledku ¾ výpočtů přijde
vniveč, je prostě zoufalé.“
Více: Kitguru
Huddy zde naráží právě na rozpor mezi přístupem vývojářů
her, v jejichž zájmu je maximální optimalizace a přístupem Nvidie,
v jejímž zájmu je zajistit za každou cenu, aby se šířily taková dema a
benchmarky, ze kterých vyjde konkurenční produkt jako poražený.

Huddyho slova ale extrémní případy uplacených dem a
benchmarků z recenzí neodstraní, takže AMD nezbývá než jít ještě dál a
s čipem Cayman (HD 6900) představit mimo jiné
i distribuovanou geometrii, což prakticky znamená více teselátorů
v jednom čipu.
H.A.W.X. 2 demo – další v řadě?
Jinou strategii Nvidia zvolila v případě dema
ke hře H.A.W.X. 2, které bylo přichystáno a Nvidií poskytnuto a
doporučeno k testování právě při příležitosti vydání Radeonů HD 6800.
Na hře se podílelo i AMD a vyvinulo pro ni i vlastní optimalizace. Ty ale
nebyly do demoverze hry, kterou Nvidia rozeslala redaktorům, zahrnuty.
Výsledek: Recenze zkreslené demem „na objednávku“.

AMD: „AMD demonstrovalo Ubisoftu optimalizace
teselačního výkonu, ze kterých by benefitovala všechny GPU, ale Ubisoft je do
tohoto dema neimplementoval. Z toho důvodu pracujeme v rámci ovladačů
na řešení, které zlepší výkon bez degradace kvality obrazu. Mělo by být hotové
do vydání finální verze hry. Do té doby nedoporučujeme používat toto demo
k testování, neboť v žádném ohledu neodráží nároky ostatních DirectX
11 her využívajících teselaci.“

Více: HardOCP
V současné chvíli nezbývá než doufat, že po vydání
Radeonu HD 6900 ztratí tato fraška smysl a z teselace konečně
přestane být nástrojem marketingovým a stane se tím, čím měla být od začátku –
nástrojem zlepšujícím vizuální stránku her. Budeme také zvědavi, zda AMD dokáže, že mluví na HardOCP pravdu a do finální hry předloží ovladače s významně zlepšených výkonem v H.A.W.X. 2.






































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU