
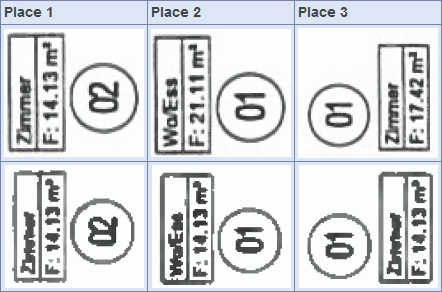
Problém objevil a na svém blogu zveřejnil německý akademik David Kriesel. Ilustruje ho obrázek výše: nahoře je naskenovaný originál, dole kopie z Xerox WorkCentre 7535. Všimněte si číselných údajů na druhém řádku v rámečku: v originále je číslo pokaždé jiné, na kopii ale vždy 14,13. Kriesel prováděl ještě tři pokusy s WorkCentre 7556 a kopírka pokaždé zmotala minimálně jedno číslo.
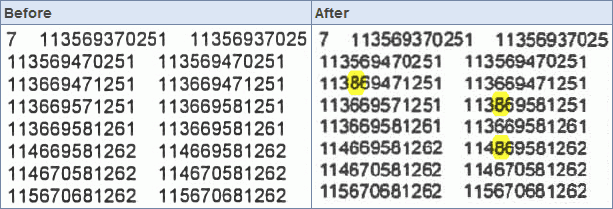
Kopírky WorkCentre s oblibou mění šestky na osmičky. Není to jenom chybně vytištěných několik pixelů, které by číslici dokreslily. Celý znak je vyměněn za jiný a nemáme-li originál pro srovnání, nic nenasvědčuje tomu, že je něco v nepořádku.

Chyby na první pohled vypadají jako produkt optického rozpoznávání znaků (OCR), které není vždy stoprocentně spolehlivé. Jedná se ale o fotokopie, kdy je naskenována celá stránka a obratem vytištěna. Jádro pudla pochopitelně leží mezi těmito dvěma kroky. Xerox totiž komprimuje naskenovaný obraz algoritmem JBIG2. Ten vytváří „slovník“ duplicitních částí obrazu, které pak stačí mít v paměti uložené jednou. Velikost těchto výřezů je očividně nastavena tak, že při malé velikosti písma (na druhém obrázku je Arial výšky 7 bodů) se do nich vejde celý znak – a když algoritmus shledá číslice 6 a 8 jako příliš podobné, bez milosti cifry nahradí.

Kompletní seznam modelů, které chyba postihuje, zatím není znám; Xerox byl na problém upozorněn a prošetřuje jej. Verze firmware na tisk popletených čísel nemá vliv – chyba tedy zřejmě existuje už dlouhou dobu a je s podivem, že se na ni přišlo až nyní.
Zdroj: dkriesel.com











































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU