
Architektura nazvaná podle italského fyzika nemá své „vědecké“ jméno náhodou. A zřejmě nemá náhodou ani kódové označení GF100 (GeForce Fermi 100). Byla tu už sice G200 nebo GT200 (GeForce Tesla), ale naopak toto označení bylo matoucí. Zatímco GT200 byla pouhým faceliftem (a spíše násobením a zvětšováním) G80 a G92, vývoj GF100 zřejmě započal po G80. Jenže jakožto vývoj opravdu nové architektury trval podstatně déle a Nvidia mezitím samozřejmě nemohl ustrnout na G80 a G92. Bude kódové označení Fermi kromě vhodnosti GF100 pro náročné vědecké účely mít spojitost i s faktem, že Enrico Fermi sestrojil první jaderný reaktor?
Od triangle setup až k GPGPU
Nvidia při stručné historii GPU v úvodu prezentace nové architektury nezapomněla připomenout, že zkratka GPU (Graphics Processing Unit) se zavedla společně s první GeForce (GeForce-256), která nesla novinku ukotvenou v sedmé generaci DirectX: T&L jednotku. Transform&lighting (transformace a výpočty osvětlení) dosud dělal procesor a ukousnutí jeho práce předznamenalo další vývoj. Nechme teď stranou, že GeForce-256 nebyla první grafickou kartou s T&L a že první ulevení práce procesoru bylo i v konzumních (či herních) 3D čipech pozorovatelné ještě dříve (mluvím o triangle setup) a u jiné značky. Později se fixní T&L jednotka vyšvihla v programovatelný vertex shader a byť byla kontrola vrcholů trojúhelníka možná stále jen pomocí jazyků nižšího řádu, byl to další krok.
Současně s ním grafická karta GeForce 3 pod rozhraním DirectX 8 nabízela programovatelné operace s pixely (pixel shader, pod OpenGL fragment shader) a s další skutečně celou generací přišly i jazyky (shaderů) vyššího řádu. Skutečným předchůdcem GF100 je však G80, srdce GeForce 8800 (GTX, GTS-320/640 a Ultra). Ačkoli uvedena v listopadu 2006, pracovalo se na ní už od roku 2002. G80 byla prvním GPU, u něhož se dalo mluvit o GPGPU – General Purpose GPU znamená opravdu grafickou vypočetní jednotku použitelnou k obecnějším účelům (výpočtům). Unifikované stream procesory G80 podporovaly jazyk C (první verze CUDA) a programátoři dostali k dispozici i SIMT model (jedna instrukce více vláken) a sdílenou paměť odbourávající bariéru komunikace procesových vláken.
V roce 2008 došlo k vylepšení G80 v podobě čipu GT200. Herní GeForce GTX 280 a GPGPU karta Tesla T10 měla k dispozici především namísto 128 rovnou 240 stream procesorů (později Nvidií nazývaných jako CUDA procesory) a kromě přidání podpory double precision (s nevalným výkonem) bylo v podstatě vše týkající se GPGPU zdvojnásobeno.
Přichází Fermi
Architektura Fermi není žádným faceliftem a přidáváním jednotek: jedná se o velký skok ve vývoji a z velké části nový směr. Jestli správný, to ukáží až následující měsíce a spíše roky. Návrháři Fermi se zaměřili především na tato dosavadní omezení:
- slabý výkon v double precision (FP operace, v single precision už výkon GPU byl ve velkých násobcích výkonu CPU)
- podpora pamětí ECC (aby GPU mohla sloužit v datacentrech)
- některé paralelní algoritmy nemohly používat sdílenou paměť GPU (je třeba opravdové sdílené cache a také programátoři chtěli více než 16 kB sdílené paměti)
- vývojáři chtěli rychlejší přepínání kontextu
- stejně tak byly požadovány rychlejší atomické operace v paralelních algoritmech
Nvidia na tato přání reaguje Fermi s těmito klíčovými vlastnostmi:
- 32 CUDA procesorů na streaming multiprocessor (SM), čtyřnásobek GT200
- 8× vyšší výkon v double precision než GT200
- 64 kB RAM s L1 cache
- unifikovaný adresní prostor s plnou podporou C++
- optimalizace pro OpenCL a DirectCompute
- podpora přesnosti IEEE 754-2008 32- a 64-bit
- Parallel DataCache hierarchie s konfigurovatelnou L1 a unifikovanou L2
- podpora ECC pamětí
- podstatně vyšší výkon atomických operací
- 10× rychlejší přepínání kontextu
- out-of-order
- ...
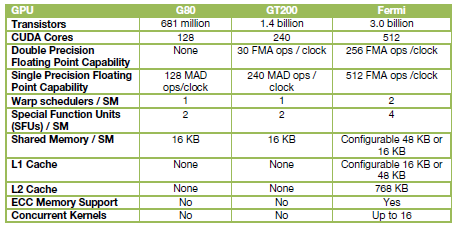
První GPU architektury Fermi, GF100, obsahuje 3 miliardy tranzistorů a až 512 CUDA (stream) procesorů. 512 SP je organizováno do šestnácti SM (každý s 32 jádry). GPU má 384bitový paměťový řadič (6× 64-bit) a podporuje maximálně 6 GB GDDR5.

Že vám tohle schématické znázornění hlavních části GF100 něco připomíná? Ano, vypadá to trochu jako Larrabee (doporučuji pročíst článek o architektuře tohoto "x86 GPU" Intelu). Při rozhovorech se zástupci Nvidie také nezřídka slyšíte, že cílem „útoku“ nebyly ani tak Radeony společnosti AMD, ale právě Larrabee mocného Intelu. Jestli má Fermi nějakou spojitost s odchodem Pata Gelsingera dosud prezentujícího Larrabee z Intelu, to si ale opravdu netroufám ani spekulovat.
Dvakrát do jedné řeky nevstoupíš?
Jisté je, že Nvidia opět nezvolila strategii AMD: trefit "sweet spot" s čipem vyššího mainstreamu o rozumné velikosti (i když AMD s RV870 už také trochu vybočila) a od tohoto čipu odvodit odsekáním jednotek levnější řešení a pomocí Multi-GPU dosáhnout na příčky nejvyšší. GF100 bude opět veliký čip, z něhož se budou odvozovat další, levnější a pomalejší. Nvidia (zřejmě správně) uvádí, že škálovatelnost Fermi bude daleko větší (snadnější).

Nebudu vás unavovat detaily výpočetních jednotek, jež bych stejně musel přeložit prakticky 1:1 z materiálu Nvidie (zájemci o tento text nechť využijí odkazu vedoucího na TechReport na konci článku), namísto toho se podívejme na jeden z několika výkonnostních grafů z prezentace:

Bohužel není ani z kontextu v PDF jasné, zda se jedná o srovnání architektur takt na takt a třeba i při stejném počtu jednotek. To by byl pro Fermi optimistický scénář, pesimistický spočívá ve srovnání GTX 280 a první karty na GF100 (tedy s rozdílnými takty jádra a především SP/CUDA procesorů a hlavně s 512 SP proti 240 SP).
Další graf patří rychlosti třídění algoritmem Radix, u něhož je dosaženo podobného nárůstu jako u DP:

Simulace kapalin (resp. kolizí kapalin s konvexními tvary) zaznamená na Fermi až 2,7násobku rychlosti oproti GT200:

Slibované urychlení atomický operací je díky kombinaci více jednotek v hardwaru a přidání L2 cache dramatické:

Nexus – sen vývojářů?
Skoro nakonec jsem si nechal něco, co Nvidia nazývá tím vůbec nejvíce „sexy“ na Fermi. Je to možnost vyvíjet pro GPGPU v kompletním integrovaném prostředí pomocí C++. Vývojářský nástroj se jmenuje Nvidia Nexus pod odstavcem vidíte jeho ukázku.

Nexus umožňuje návrh a odladění kódu pro GPU přímo v nástroji, na který jsou vývojáři zvyklí z programování pro CPU – Microsoft Visual Studiu. Nexus Visual Studio obohacuje o nástroje pro masivní paralelismus (v němž GPU samozřejmě dále a ještě výrazněji exceluje).
Co čekat?
Fermi je bezpochyby odvážným krokem a opravdu směřuje do vod dosud neprobádaných. Nedokážu predikovat, zda je už opravdu čas pro čip tolik zaměřený na GPGPU a zda Nvidia vytvoří prakticky nový trh. Stejně tak nemůžeme zatím předpokládat, jak si GF100 povede v 3D a jestli bude rychlejší než Radeon HD 5870 a případně o kolik. Z „konvenčních parametrů“ víme toliko:
- jádro GF100, 3 miliardy tranzistorů, 40nm výrobní proces u TSMC
- 512 stream procesorů
- 384bitová paměťová sběrnice (GDDR5)
Dá se sice s určitou mírou přesnosti odhadovat plocha jádra, použití podobně rychlých GDDR5 jako AMD (4,8 Gb/s, následně v kombinaci s 384bitovou sběrnicí propustnost 230 GB/s), takt stream (CUDA) procesorů opět kolem 1,5 GHz, ... ale při neznalosti změn v texturovacích jednotkách, ROP a efektivity nové architektury půjde pořád o čistou spekulaci. 3D část GF100 bude odhalena minimálně o měsíc později a bude zajímavé sledovat, zda se svou DirectX 11 GeForce stihne Nvidia předvánoční trh.
Není nezajímavé také připomenout, že Nvidia na GPU Technology Conference (viz webcasty) evidentně zmiňuje dříve zatracovaný raytracing. Koupě mental images a navyšování GPGPU výkonu by mohlo leccos naznačovat. Můžete být také pesimisty a vzpomenout na zdánlivě revoluční v praxi však nešťastnou VLIW architekturu GeForce FX (malou reminiscencí je zapomenutý obsah nvidia.com),...

... nebo také optimisty a čekat opakování úspěchu GeForce 8800 GTX (G80).
Aktuálně:
- Architektura Fermi na nvidia.com (animované představení s ženským hlasem, PDF whitepaper)
- Blog (zápisky) z GTC 09











































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU